Outil de gestion des paquets de modèles d’apprentissage profond
Cette section propose un guide d’utilisation de l’outil de gestion des paquets de modèles d’apprentissage profond ainsi que quelques remarques importantes.
Introduction
L’outil de gestion des paquets de modèles d’apprentissage profond est conçu pour gérer tous les paquets de modèles d’apprentissage profond dans Mech-Vision. Il permet d’optimiser des paquets de modèles uniques ou en cascade exportés par Mech-DLK 2.2.0 ou ultérieur, et de gérer et surveiller le mode de fonctionnement, le type de matériel, l’efficacité du modèle et l’état du paquet de modèle. En outre, cet outil permet de surveiller l’utilisation de la mémoire GPU de l’IPC.
Si des Étapes d’apprentissage profond sont utilisées dans le projet, vous pouvez d’abord importer le paquet de modèle dans l’outil de gestion des paquets de modèles d’apprentissage profond, puis utiliser les modèles dans les Étapes correspondantes. L’importation du paquet de modèle dans l’outil facilite l’optimisation préalable du paquet de modèle.
|
À partir de Mech-DLK 2.4.1, les paquets de modèles peuvent être divisés en paquets de modèle uniques et paquets de modèle en cascade.
|
Présentation de l’interface
Vous pouvez ouvrir l’outil de l’une des deux manières suivantes :
-
Après avoir créé ou ouvert un projet, sélectionnez dans la barre de menus.
-
Dans un projet ouvert, sélectionnez l’Étape « Inférence du paquet de modèle d’apprentissage profond », puis cliquez sur le bouton Outil de gestion des paquets de modèles dans le panneau Paramètres de l’Étape.
Les options de l’outil de gestion des paquets de modèles d’apprentissage profond sont présentées dans le tableau ci-dessous.
| Option | Description |
|---|---|
Paquet de modèle disponible |
Les noms des paquets de modèles importés |
Nom du projet |
Le projet Mech-Vision dans lequel le paquet de modèle correspondant est utilisé |
Type de paquet de modèle |
Le type de paquet de modèle, tel que « Détection d’objets » (paquet de modèle unique) et « Détection d’objets + Segmentation des défauts » (paquet de modèle en cascade) |
Mode de fonctionnement |
Le mode de fonctionnement du paquet de modèle, y compris « Mode partagé » et « Mode performance » |
Type de matériel |
Le type de matériel utilisé pour l’inférence du paquet de modèle. Si vous utilisez un modèle GPU, vous pouvez modifier le type de matériel, c.-à-d. GPU (par défaut), GPU (optimisation) et CPU |
Efficacité du modèle |
L’efficacité d’inférence du paquet de modèle |
État du paquet de modèle |
L’état du paquet de modèle, tel que « Chargement et optimisation », « Chargement terminé » et « Échec de l’optimisation » |
|
Mode de fonctionnement
Type de matériel
|
|
L’outil de gestion des paquets de modèles d’apprentissage profond détermine l’option Type de matériel en détectant le type de matériel de l’ordinateur. Les règles d’affichage pour chaque option Type de matériel sont les suivantes.
|
Utilisation
Suivez les étapes ci-dessous pour connaître les procédures courantes d’utilisation de l’outil de gestion des paquets de modèles d’apprentissage profond.
Importer le paquet de modèle d’apprentissage profond
-
Ouvrez l’outil de gestion des paquets de modèles d’apprentissage profond, puis cliquez sur Importer dans l’angle supérieur gauche.
-
Sélectionnez le paquet de modèle que vous souhaitez importer dans la fenêtre contextuelle Sélectionner un fichier et cliquez sur Ouvrir. Le paquet de modèle d’apprentissage profond apparaîtra alors dans la liste de la fenêtre, ce qui indique que le paquet de modèle a été importé avec succès.
|
Pour importer un paquet de modèle avec succès, la version minimale requise du pilote graphique est 472.50, et la configuration minimale requise pour le CPU est un processeur Intel Core de 6e génération. Il n’est pas recommandé d’utiliser un pilote graphique supérieur à la version 500, qui peut provoquer des fluctuations du temps d’exécution des Étapes d’apprentissage profond. Si le matériel ne répond pas à l’exigence, le paquet de modèle d’apprentissage profond ne pourra pas être importé avec succès. |
Sélectionner le paquet de modèle d’apprentissage profond dans l’Étape
Après avoir importé le paquet de modèle dans l’outil, si vous souhaitez utiliser le paquet de modèle dans l’Étape Inférence du paquet de modèle d’apprentissage profond, vous pouvez sélectionner le paquet de modèle dans la liste déroulante du paramètre Nom du paquet de modèle dans le panneau Paramètres de l’Étape.
Supprimer le paquet de modèle d’apprentissage profond importé
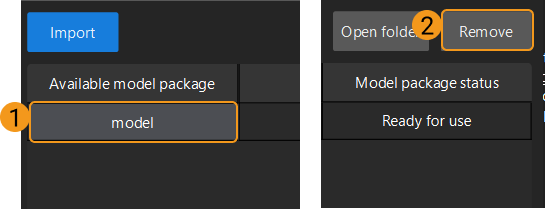
Si vous souhaitez supprimer un paquet de modèle d’apprentissage profond importé, sélectionnez d’abord le paquet de modèle, puis cliquez sur le bouton Supprimer dans l’angle supérieur droit.
|
Lorsque le paquet de modèle d’apprentissage profond est Chargement et optimisation ou que le projet utilisant le paquet de modèle est en cours d’exécution, le paquet de modèle ne peut pas être supprimé. |
Changer le mode de fonctionnement
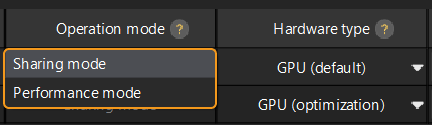
Si vous souhaitez changer le Mode de fonctionnement pour l’inférence du paquet de modèle d’apprentissage profond, vous pouvez cliquer sur ![]() dans la colonne Mode de fonctionnement de l’outil de gestion des paquets de modèles d’apprentissage profond, puis sélectionner Mode partagé ou Mode performance.
dans la colonne Mode de fonctionnement de l’outil de gestion des paquets de modèles d’apprentissage profond, puis sélectionner Mode partagé ou Mode performance.
|
Changer le type de matériel
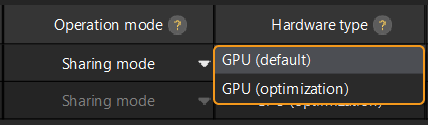
Vous pouvez changer le type de matériel pour l’inférence du paquet de modèle d’apprentissage profond en GPU (par défaut), GPU (optimisation) ou CPU.
Cliquez sur ![]() dans la colonne Type de matériel de l’outil de gestion des paquets de modèles d’apprentissage profond, puis sélectionnez GPU (par défaut), GPU (optimisation) ou CPU.
dans la colonne Type de matériel de l’outil de gestion des paquets de modèles d’apprentissage profond, puis sélectionnez GPU (par défaut), GPU (optimisation) ou CPU.
|
Configurer l’efficacité du modèle
Lorsqu’un paquet de modèle exporté par Mech-DLK 2.4.1 ou supérieur est utilisé, l’efficacité du modèle peut être configurée. La procédure de configuration de l’efficacité du modèle est la suivante.
-
Importez le paquet de modèle d’apprentissage profond.
-
Cliquez sur le bouton Configurer dans la colonne Efficacité du modèle ; une fenêtre de configuration de l’efficacité du modèle s’ouvrira et vous pourrez configurer la « Taille de lot » et la « Précision ».
Les paramètres « Taille de lot » et « Précision » peuvent affecter la configuration de l’efficacité du modèle.
-
Taille de lot : le nombre d’images qui seront passées à travers le réseau neuronal en une seule fois pendant l’inférence, allant de 1 à 128. Augmenter la valeur augmentera la vitesse d’inférence du modèle, mais davantage de mémoire vidéo sera utilisée. Si la valeur n’est pas correctement définie, la vitesse d’inférence sera ralentie. Les modèles de segmentation d’instances ne prennent pas en charge la configuration de la « Taille de lot », et la « Taille de lot » par défaut doit être réglée sur 1.
-
Précision (Disponible uniquement lorsque le « Type de matériel » est « GPU optimisation ») : FP32 : modèle de haute précision avec une vitesse d’inférence plus faible. FP16 : modèle de faible précision avec une vitesse d’inférence plus élevée. Par exemple, si « FP32 » est remplacé par « FP16 », le résultat d’inférence changera en raison d’une précision de modèle réduite.
Il est recommandé de définir la « Taille de lot » égale au nombre réel d’images qui sont passées à travers le réseau neuronal.
Si la « Taille de lot » définie est beaucoup plus grande que le nombre réel d’images qui sont passées à travers le réseau neuronal, une partie des ressources sera gaspillée, ce qui entraînera un ralentissement de l’inférence.
Par exemple, si le nombre d’images est 26 et que la « Taille de lot » est définie à 20, deux inférences distinctes seront effectuées. Lors de la première inférence, 20 images seront fournies au réseau neuronal, tandis que lors de la seconde inférence, 6 images seront fournies au réseau neuronal. Pour la seconde inférence, la « Taille de lot » définie est beaucoup plus grande que le nombre réel d’images qui sont passées à travers le réseau neuronal ; une partie des ressources sera gaspillée, ce qui entraînera un ralentissement de l’inférence. Par conséquent, veuillez régler la « Taille de lot » sur une valeur appropriée afin d’assurer une utilisation efficace des ressources.
-
Dépannage
Échec de l’importation d’un paquet de modèle d’apprentissage profond
Symptôme
Après avoir sélectionné un paquet de modèle d’apprentissage profond à importer, le système affiche le message d’erreur « Échec de l’importation du paquet de modèle d’apprentissage profond. »
Causes possibles
-
Un paquet de modèle portant le même nom a été importé.
-
Un paquet de modèle contenant le même contenu a été importé.
-
Le matériel et les logiciels ne répondent pas aux exigences minimales.
Solutions
-
Modifiez le nom du paquet de modèle ou supprimez le paquet importé portant le même nom.
-
Vérifiez le contenu du paquet de modèle. S’il est identique au paquet déjà importé, il n’est pas nécessaire de l’importer à nouveau.
-
Assurez-vous que la version minimale requise du pilote graphique est 472.50 et que la version minimale requise du CPU est Intel Core de 6e génération.
Échec de l’optimisation d’un paquet de modèle d’apprentissage profond
Symptôme
Lors de l’optimisation d’un paquet de modèle d’apprentissage profond, un message d’erreur « Échec de l’optimisation du paquet de modèle » est apparu.
Causes possibles
Mémoire GPU insuffisante.
Solutions
-
Supprimez les paquets de modèles inutilisés dans l’outil, puis réimportez le paquet de modèle pour l’optimiser.
-
Passez le « Mode de fonctionnement » des autres paquets de modèles en « Mode partagé », puis importez à nouveau le paquet de modèle pour l’optimisation.
Remarques sur les compatibilités
-
Les paquets de modèles d’apprentissage profond exportés par Mech-DLK 2.4.1 peuvent être utilisés dans Mech-Vision 1.7.1. Cependant, des problèmes de compatibilité peuvent survenir. Il est recommandé d’utiliser des paquets de modèles exportés par Mech-DLK 2.4.1 ou supérieur avec Mech-Vision 1.7.2 ou supérieur.
-
Les paquets de modèles en cascade ne peuvent pas être utilisés dans Mech-Vision.
-
L’efficacité du modèle ne peut pas être configurée.
-
Les performances de la classification d’images peuvent être diminuées.
-
Les paquets de modèles ne peuvent pas être utilisés sur des appareils CPU.
-
-
Si des paquets de modèles optimisés avec Mech-Vision 1.7.1 sont utilisés dans Mech-Vision 1.7.2, le temps d’exécution peut être plus long lorsque le paquet de modèle optimisé est utilisé pour la première fois dans l’Étape « Inférence du paquet de modèle d’apprentissage profond ».
-
Veuillez prêter attention au problème suivant lorsque le Type de matériel pour l’inférence du paquet de modèle est défini sur GPU (optimisation).
Si le paquet de modèle n’est pas optimisé dans Mech-Vision 1.7.X et qu’il est optimisé dans Mech-Vision 1.8.0 ou des versions ultérieures, le paquet de modèle ne pourra pas fonctionner correctement dans Mech-Vision 1.7.X. Vous devez cliquer sur Ouvrir le dossier dans l’Outil de gestion des paquets de modèles d’apprentissage profond, supprimer le dossier de cache correspondant au paquet de modèle, puis optimiser à nouveau le paquet de modèle.
Vous pouvez vérifier le dossier de cache correspondant au paquet de modèle dans le fichier model_config.json.