Utiliser l’apprentissage profond
Dans cette section, vous apprendrez à appliquer l’apprentissage profond à vos projets. Le flux de travail global est présenté comme suit :

-
Préparation: Avant l’entraînement du modèle, certaines préparations doivent être effectuées, notamment l’acquisition d’images et le choix d’un IPC.
-
Entraîner un modèle: Après les préparatifs, utilisez les données acquises pour entraîner et valider un modèle dans Mech-DLK.
-
Configurer et utiliser le modèle: Configurez le modèle entraîné dans Mech-Vision et utilisez le modèle dans les Étapes pertinentes pour accomplir des tâches spécifiques.
-
Itération du modèle: Après une certaine période d’utilisation, vous pouvez constater que le modèle entraîné peut ne pas être applicable à certains scénarios. À ce stade, vous devez itérer le modèle.
Se préparer
Préparer un IPC
L’IPC utilisant Mech-DLK pour l’entraînement des modèles d’apprentissage profond doit répondre aux exigences suivantes.
Version de licence logicielle autorisée |
Pro-Run |
Pro-Train/Standard |
|---|---|---|
Système d’exploitation |
Windows 10 ou version ultérieure |
|
CPU |
Intel® Core™ i7-6700 ou supérieur |
|
Mémoire |
8 Go ou plus |
16 Go ou plus |
Carte graphique |
GeForce GTX 1660 ou supérieure |
GeForce RTX 3060 ou supérieure |
Pilote de la carte graphique |
Version 526.98 ou supérieure |
|
|
La version Pro-Run offre le déploiement Mech-DLK SDK, l’annotation et le mode d’exploitation. La version Pro-Train prend en charge toutes les fonctionnalités, y compris la mise en cascade de modules, l’annotation, l’entraînement, la validation et le déploiement Mech-DLK SDK, tandis que la version Standard prend en charge les fonctionnalités d’annotation, d’entraînement et de validation. |
Créer un projet d’acquisition d’images
Avec un IPC qualifié à disposition, vous pouvez maintenant commencer à créer un projet d’acquisition d’images. Il n’est pas nécessaire de construire un projet d’acquisition d’images séparément, car l’acquisition d’images est couverte dans les projets de vision élaborés selon les besoins réels de l’application.
Assurez-vous que la fonction stockage des données est activée afin que les images puissent être enregistrées dans le répertoire spécifié lorsque le projet créé s’exécute.
-
Ouvrir le panneau de stockage des données. Cliquez sur l’onglet Assistant de projet dans le coin inférieur droit de l’interface, puis cliquez sur
 pour ouvrir le panneau de stockage des données.
pour ouvrir le panneau de stockage des données. -
Activer la fonction de stockage des données. Activez l’option Enregistrer les données et les paramètres.
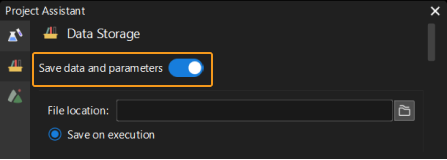
-
Définir le répertoire d’enregistrement des images. Spécifiez l'Emplacement du fichier pour l’enregistrement des images. Dans la plupart des cas, les images sont enregistrées dans le dossier « data » sous le dossier du projet.
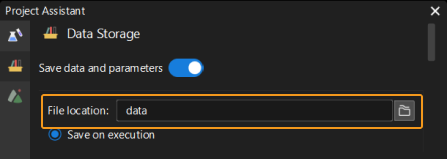
Acquérir des données d’image
Une fois le projet construit et déployé, vous pouvez commencer à acquérir des images.
Assurer la qualité des images (avant l’acquisition)
La qualité des images a un impact considérable sur la stabilité du modèle, et des images de haute qualité conduisent souvent à de meilleures performances de reconnaissance et à des prédictions plus précises. Avant l’acquisition d’images, ajustez la balance des blancs et les paramètres d’exposition 2D de la caméra afin de garantir que les images acquises sont complètes.
Ajuster la balance des blancs
La balance des blancs est le paramètre de la caméra qui aide à corriger les couleurs, quelle que soit la condition d’éclairage, afin que les objets blancs apparaissent réellement blancs.
Si des images 2D avec des couleurs déformées sont utilisées pour l’entraînement du modèle d’apprentissage profond, ces déformations seront extraites comme caractéristiques de l’objet pour l’entraînement, ce qui affecte les performances de reconnaissance du modèle. Par conséquent, l’ajustement de la balance des blancs de la caméra est crucial pour acquérir des images avec une représentation correcte des couleurs. Voir les instructions détaillées dans Ajuster la balance des blancs.
Ajuster les paramètres d’exposition
Lors de l’entraînement du modèle, toutes les caractéristiques des objets dans une image sont extraites, telles que la couleur et la forme. Cependant, si les images sont surexposées ou sous-exposées, ces caractéristiques seront perdues dans une certaine mesure, ce qui signifie que l’entraînement manquera d’informations clés. Par conséquent, les performances du modèle sont affectées. Ainsi, l’ajustement des paramètres d’exposition de la caméra est crucial pour acquérir des images de haute qualité. Voir les instructions détaillées dans Ajuster la balance des blancs.
Assurer la qualité des images (pendant l’acquisition)
Un nombre suffisant d’images doit être acquis pour garantir une diversité d’images disponible pour l’entraînement du modèle. Notez que pour différents objets cibles, le nombre d’images requis peut varier.
Il est courant de démarrer le projet manuellement pour l’acquisition d’images afin d’assurer la diversité des images. Les positions et l’agencement des objets cibles doivent être ajustés manuellement à chaque exécution du projet.
|
Les objets cibles rigides sont des entités capables de conserver leur forme et leur taille malgré des mouvements et des forces externes. Les positions relatives de chaque point au sein de ces objets restent inchangées dans de telles conditions. |
Cliquez ici pour consulter les exigences de quantité d’images pour les objets cibles rigides dans diverses conditions.
| Objet cible à cas unique | Objet cible multi-cas (matériaux entrants uniques) | Objet cible multi-cas (matériaux entrants mixtes) | Objet cible polyédrique | |
|---|---|---|---|---|
Quantité d’images pour des matériaux entrants ordonnés |
40–60 |
40–60 |
60–80 |
80–100 |
Quantité d’images pour des matériaux entrants dispersés |
60–80 |
40–60 images pour chaque type d’objet cible |
100 |
100–120 |
Notez que les images acquises des objets cibles rigides doivent couvrir les situations des objets cibles dans plusieurs stations et plusieurs orientations, ainsi que différentes densités, différentes hauteurs, et diverses conditions d’éclairage.
Cliquez ici pour consulter les exigences de quantité d’images pour des sacs dans diverses conditions.
| Sacs entièrement remplis et soigneusement empilés | Sacs peu remplis et avec de nombreux plis de surface | |
|---|---|---|
Quantité d’images |
20 |
30 |
Notez que les images doivent couvrir les situations où les sacs sont de différents types et couches et dans des conditions d’éclairage différentes, et des situations qui reflètent des agencements, des motifs de palettes et des conditions d’arrivée des sacs différents.
Cliquez ici pour consulter les exigences de quantité d’images pour des cartons dans diverses conditions.
| Cartons à cas unique | Cartons multi-cas (matériaux entrants mixtes) | Cartons dispersés | Cartons avec rubans adhésifs, étiquettes ou feuillards | |
|---|---|---|---|---|
Quantité d’images |
30 images depuis la couche la plus haute jusqu’à ce que la palette soit vide |
20 images pour chaque type de carton |
50 images au total.
|
50 |
Notez que les images doivent couvrir les situations où les cartons sont de différents types et couches et dans des conditions d’éclairage différentes, et des situations qui reflètent des agencements, des motifs de palettes et des conditions d’arrivée des cartons différents.
Filtrer les images (après l’acquisition)
Après l’acquisition d’images, les images de faible qualité doivent être filtrées et les bonnes conservées. Assurez-vous que les images conservées reflètent toujours la diversité.
Cliquez ici pour consulter les exigences de filtrage d’images pour des objets cibles rigides, des sacs et des cartons.
| Images à filtrer | Images à conserver | |
|---|---|---|
Objets cibles rigides |
|
|
Sacs et cartons |
|
|
Entraîner un modèle
Après les préparatifs ci-dessus, vous pouvez maintenant utiliser ces images pour entraîner un modèle dans Mech-DLK. Le flux de travail général de l’entraînement du modèle est le suivant.

-
Créer un nouveau projet: Créez un nouveau projet pour l’entraînement du modèle.
-
Sélectionner un algorithme: Sélectionnez le module d’algorithme d’apprentissage profond souhaité.
-
Importer des images: Importez les images acquises pour l’entraînement du modèle.
-
Annoter les images: Annotez les caractéristiques des images pour fournir les informations requises par l’entraînement du modèle.
-
Entraîner un modèle: Entraînez un modèle d’apprentissage profond après l’annotation.
-
Valider le modèle: Une fois l’entraînement terminé, validez le modèle et vérifiez les résultats.
-
Exporter le modèle: Si les performances du modèle répondent à vos besoins, exportez-le vers un emplacement spécifié sous la forme d’un paquet de modèle.
Pour des instructions détaillées, voir Utiliser le module de segmentation d’instances.
Configurer et utiliser le modèle
Le package de modèle exporté doit être configuré dans Mech-Vision avant d’être utilisé dans les Étapes pertinentes pour l’inférence. Pour des instructions détaillées, voir le lien:https://docs.mech-mind.net/en/suite-software-manual/2.1.2/vision-tools/deep-learning-model-management.html#operation-guide[section d’utilisation de l’outil de gestion des packages de modèles d’apprentissage profond].
Itération du modèle
Après une certaine période d’utilisation, vous pouvez constater que le modèle entraîné peut ne pas être applicable à certains scénarios. À ce stade, vous devez itérer le modèle. Il est courant de réentraîner le modèle avec davantage de données, mais un tel effort pourrait réduire la précision globale de la reconnaissance et prendre beaucoup de temps. Il est donc recommandé d’utiliser la fonction de finetuning du modèle pour l’itération, afin de maintenir la précision et de gagner du temps. Pour plus de détails, voir Itération de modèle d’apprentissage profond.
Vous pouvez maintenant regarder la vidéo ci-dessous pour apprendre à entraîner un modèle de segmentation d’instances et à l’appliquer.