Information Reading (Optical Character Recognition)
This section introduces the target object recognition configuration workflow for the optical character recognition scenario. This method is used to recognize characters printed, engraved, or inkjet-marked on the target object surface to extract key information such as model numbers and batch numbers.
Click Config wizard, select the Information Reading scenario, and select the Optical character recognition method to enter this configuration workflow.
Usage Workflow
The overall recognition workflow includes four steps:

-
Image preprocessing: Perform color conversion, enhancement, denoising, morphological transformations, and other preprocessing on the input image to improve image quality, highlight target object features, and reduce background interference, providing a reliable data foundation for subsequent character recognition.
-
Pose correction: Set the recognition region and align the recognition target with the template through alignment operations. Select an appropriate correction method based on recognition target features, flexibly configure parameters, eliminate position and angle deviations, and improve recognition accuracy and result reliability.
-
Information reading: Based on actual requirements, set the target area for detection in the aligned image, and set related parameters and judgment rules to accurately read and parse character content and verify its format and content accuracy.
-
General settings: Configure output ports to output recognition results and key information, meeting production line automated detection and data traceability requirements.
Image Preprocessing
Before recognizing target objects, you can choose to enable Convert color space or Image preprocessing based on the input image quality, and adjust the corresponding parameters to make image features clearer, thereby improving recognition accuracy and efficiency.
Convert Color Space
Converting the image color space can transform the input image from one color space to another, for example, from BGR to grayscale, BGR to HSV, etc. Through color space conversion, image features can be better highlighted to facilitate subsequent image processing.
For detailed parameter description and tuning examples, please read Convert Color Space.
Image Preprocessing
In image preprocessing, you can perform enhancement, denoising, morphological transformations, grayscale inversion, edge extraction, and other preprocessing operations on the input image.
For detailed parameter description and tuning examples, please read Image Preprocessing.
Pose Correction
After completing image preprocessing, configure the pose correction settings. By setting the recognition region and correction parameters, the pose of the recognition target in the current image is corrected to align with the template, ensuring the accuracy and reliability of subsequent recognition.
Add Correction Settings
After entering the pose correction workflow, you need to create a new correction parameter group. The system supports creating multiple parameter groups, each of which can independently set recognition regions and parameters without affecting each other.
Click the Add button to enter the new parameter group window. When creating a parameter group, select an appropriate correction method based on image features and configure the corresponding parameters.
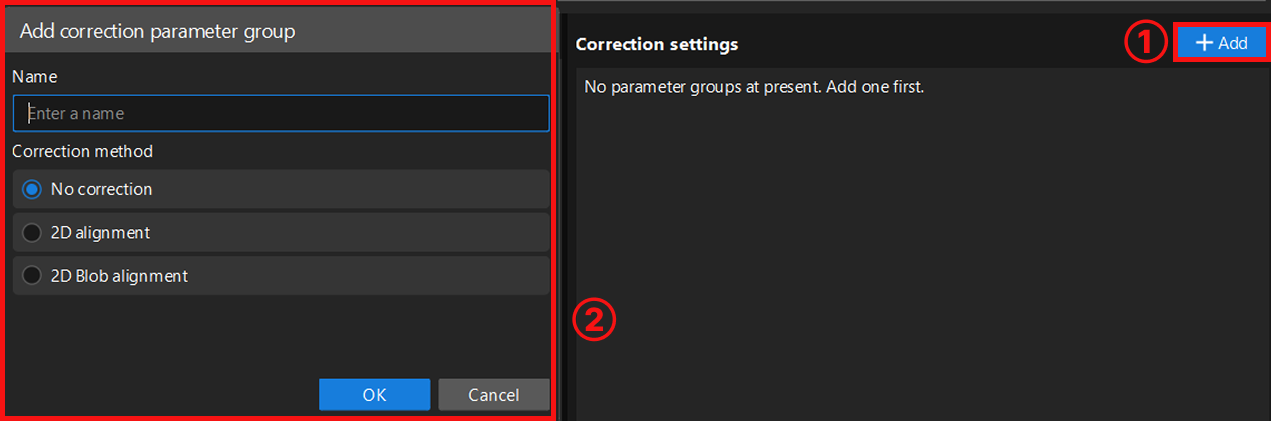
Currently, the following three correction methods are supported:
-
No correction: Uses the original input image directly for recognition without any pose correction processing. Suitable for scenarios where the recognition target position is relatively fixed in the image and the correction accuracy requirement is not high.
-
2D alignment: Aligns the recognition target’s pose with the template through translation and rotation operations. This method can extract the edge contour of the recognition target and uses an edge matching algorithm for precise alignment. Suitable for scenarios where the recognition target position is not fixed but has distinct fixed contours. For detailed configuration, read 2D Alignment.
-
2D Blob alignment: Used to detect bright and dark regions (i.e., Blobs) in the image. Filters target Blobs based on geometric features of the Blob (such as area, centroid, etc.) and calculates its minimum bounding rotated rectangle. Then adjusts the image pose so that the target Blob’s centroid aligns with the image center point, and the principal axis of its minimum bounding rotated rectangle aligns with the image coordinate axes. For detailed configuration, read 2D Blob Alignment.
After creating the parameter group, right-click the parameter group name, or directly click the function buttons on its right side to perform operations such as rename, delete, or create a copy.
2D Alignment
2D alignment is a correction method that aligns the recognition target in the input image with the template through translation and rotation operations. It can eliminate recognition errors caused by inconsistent recognition target positions, improving recognition stability. After selecting this method, you need to complete recognition region settings, template settings, and recognition parameter tuning in sequence.
Set Target Region
Used to set the effective range for alignment. When selecting, the recognition target must be fully covered with appropriate margins on all sides to ensure the stability of alignment operations and the accuracy of subsequent recognition. You can select Set all as target region or Customize target region based on actual requirements. After selecting customize, click the "Select" button to manually select the recognition region.
-
Set all as target region: Recognizes the entire image, typically suitable for scenarios where recognition targets are widely distributed.
-
Customize target region: Recognizes only the selected area, typically suitable for scenarios where you only need to focus on a specific part of the image, or want to exclude irrelevant areas (such as background, fixtures, and other interferences), helping to improve recognition efficiency and accuracy.
Recognize Target Object
Set Target Object Template
After setting the recognition region, select or edit the template for subsequent positioning and matching of the recognition target. Click the Edit button to enter the 2D Matching Template Editor.
Select representative and stable edge features from the image to generate the template, so that the system can subsequently search the image automatically and accurately locate target objects that match the template features, while ensuring the uniqueness and stability of matching results. For detailed instructions, please refer to 2D Matching Template Editor.
| After each template editing, click Update to apply the latest configuration. |
Adjust Recognition Parameters
After selecting the template, click Run Step to view the template matching results and recognition performance.
If the recognition performance is not satisfactory, you can adjust other parameters based on the features and requirements of the recognition target for optimization.
For detailed parameter description, please refer to 2D Alignment.
Then, click Next to proceed to the error-proofing check workflow.
2D Blob Alignment
2D Blob alignment is a Blob-based correction method. This method detects all Blobs in the image and filters out the Blob with the most prominent geometric features. It then adjusts the image pose so that the target Blob’s centroid aligns with the image center point, and the principal axis of its minimum bounding rotated rectangle aligns with the image coordinate axes. After selecting 2D Blob alignment, you need to complete recognition region settings and recognition parameter tuning in sequence.
Set Target Region
Used to set the effective range for alignment. When selecting, the recognition target must be fully covered with appropriate margins on all sides to ensure the stability of alignment operations and the accuracy of subsequent recognition. You can customize the settings based on actual requirements.
The system supports rectangle and circle selection modes, and allows mixed addition of multiple regions. That is, on the same image, multiple rectangle or circle recognition regions can exist simultaneously to meet recognition requirements in complex scenarios.
Recognize Target Object
After setting the recognition region, you can adjust other parameters based on the features and requirements of the recognition target for optimization.
For detailed parameter description and tuning suggestions, please refer to 2D Blob Alignment.
You can also learn more about the usage of each parameter through tuning examples.
Information Reading
After aligning the image, perform intelligent recognition of characters such as letters and numbers in the image. Through image acquisition and target area settings, combined with deep learning training and validation, character recognition results can be output.
Acquire Images
Acquire image data for training the model.
-
Confirm that the input port of the current Step is connected to image data.
-
When entering the tool, the camera will automatically acquire one image for model training. You can click the Acquire images button to acquire new image data for model training.
|
When acquiring images, it is recommended to cover typical variations in the production site, including:
Diverse images help the model adapt to the actual environment and improve judgment accuracy. |
Set ROI
After acquiring images, you need to set the ROI to define the character recognition range.
-
Click the Edit button to enter the ROI setting interface.
-
Set character size.
The system will automatically generate an orange default character size rectangle in the visualization area. After selecting it, you can adjust its size by dragging the border. To ensure model inference accuracy, please adjust this box to a size close to the actual character size. Too large or too small will affect recognition performance.
If the character size region is not displayed in the visualization area, please check whether the "Show character size region" switch is enabled.
-
Set the ROI. Two methods are available:
Setting method Description Set all as ROI
The ROI automatically covers the entire image. Suitable for scenarios where the target characters fill the image. To exclude certain areas, you can set mask regions in the next step.
Custom ROI
Select the "Rectangle" or "Ring" selection tool to drag and draw the ROI in the visualization area. Please accurately select the target area based on the actual position and shape of the target characters, avoiding irrelevant backgrounds.
-
Rectangle selection: Drag directly to draw a rectangular ROI.
-
Ring selection: Refer to the image below to drag along the circumference to draw a ring ROI. After drawing is complete, you need to set the reading direction of the circular text to clockwise or counterclockwise.

-
-
Set mask region (optional).
When there are irrelevant interferences such as reflections, shadows, or fixed backgrounds within the target area, you can set mask regions to exclude them, avoiding impact on model training and classification judgment results.
Click the Set mask region button, and use the "Polygon" selection tool to draw the mask region in the visualization area: click the left mouse button to add polygon vertices, and double-click the right mouse button to close the polygon and complete the selection.
-
After the setting is completed, click Save and apply to apply the ROI configuration.
|
When the masks of the character size region, target area, and mask region completely overlap, only the topmost layer supports editing.
|
Validate and Optimize Model
After completing the ROI setting, click the validate button to enter the validation interface.
Set Validation Parameters and Validate Model Performance
You can view or set the following parameters in the validation interface, and observe whether the model’s recognition results meet expectations.
| Parameters | Description |
|---|---|
Validation result |
Parameter description: Displays the character recognition result. After enabling judgment, the validation result will be displayed as OK or NG based on the set judgment conditions. |
Time |
Parameter description: Displays the single inference time (unit: ms). |
Confidence threshold |
Parameter description: The minimum confidence standard for the model to recognize characters. Recognition results below this value will be judged as recognition failure.
|
Character correction |
Parameter description: Used to constrain the types of the first N characters in the recognition result. The number of wildcards entered determines the number of character positions constrained; subsequent characters beyond this length are not affected. When a character at a certain position does not match the constrained type, the model will replace it with the candidate character with the highest confidence of that type. Supported wildcards: ? (any character), $ (letter), % (number), @ (symbol), ! (uppercase letter), & (lowercase letter). Default value: Off. Tuning instructions: Suitable for fixed-format character correction, such as scenarios where the first few positions have clear type requirements. It is recommended to fill in wildcards from left to right according to the actual encoding rules, avoiding over-constraining that may cause incorrect replacements. Tuning example: It is known that the actual encoding format is "number + uppercase letter + number + ...", but the model recognition result is iR20181102ar06Xd", where the first character was incorrectly recognized as a lowercase letter. 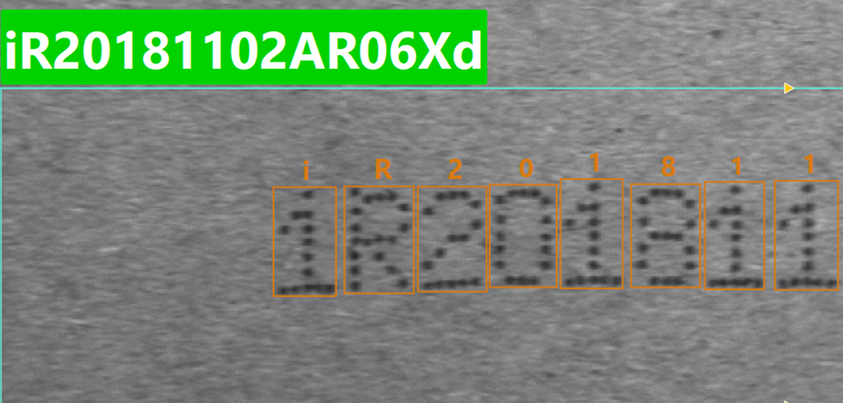
In this case, enter "%!%" in the input box (the 1st position is constrained to a number, the 2nd position is constrained to an uppercase letter, the 3rd position is constrained to a number; the 4th position and beyond are not constrained). After re-inference, the first character is corrected to the number with the highest confidence, and the result becomes "1R20181102ar06Xd". 
|
Recognition target |
Parameter description: Used to specify the character types to be extracted from the recognition results for further processing. Unselected character types will be ignored.
|
Insert separator |
Parameter description: When multiple lines of characters are recognized, this parameter is used to specify the separator to join segments for the final output.
|
Enable judgment |
Parameter description: Used to validate whether the recognition result meets expectations. Character type, character count, or fixed formats can be specified. Results that do not meet the rules will be judged as NG. Two judgment modes are supported:
Default value: Off. Tuning instructions: Used for automatic compliance checking. Use manual input mode for fixed-format validation, and global variable mode for dynamic content validation. |
Additional Training and Model Optimization (Optional)
If inaccurate recognition results are found during validation (such as character misrecognition, missed recognition, or background false detection), you can use the "Additional training" function for targeted correction until the model performance meets actual requirements.
|
Additional training is recommended in the following situations:
|
The specific operation process is as follows:
-
Click the additional training button on the validation interface to enter the additional training page.
-
Add additional content based on the problem type:
Additional content Description Operation Recognition content
Used to correct missed or misrecognized characters. Select the character area that was not correctly recognized on the image, enter the correct character content for that position, and add it as training content.
-
Click the Add button to draw a rectangle in the visualization area to select the character area.
-
Enter the correct character, and click a blank area to confirm the addition.
-
Click Infer next image, and the system will update the model based on the added content and perform inference validation on the newly acquired image. Repeat the above steps until the training content labeling is completed.
Exclusion content
Used to eliminate background false detection. Select the area on the image that was incorrectly recognized as characters, and mark it as an exclusion area. The recognition results of this area will be removed.
-
Click the Add button to drag and draw the exclusion area in the visualization area. Release the mouse to complete the addition.
-
Click Infer next image, and the system will update the model based on the added content and perform inference validation on the newly acquired image. Repeat the above steps until the exclusion content labeling is completed.
-
-
Click the Train button to retrain the model using the additional training content. After training is completed, the system automatically returns to the validation interface, where you can validate the optimized recognition performance.
Under the current mechanism, characters labeled during additional training are not restricted by the "Character correction" and "Recognition target" validation rules, and may still appear in the recognition results. To avoid conflicts between recognition results and validation rules, it is recommended to only add training content that is consistent with the character correction and recognition target settings.
-
After validation is passed, click the Save and apply button to save the model configuration.
At this point, the model configuration is completed. Click Next to proceed to the general settings workflow.
General Settings
In this workflow, you can configure auxiliary functions beyond visual recognition. Currently, output port configuration is supported.
Configure Output Port
Here, you can select the output ports based on actual requirements. By default, the recognition result is output, i.e., the specific character content.
-
Recognition judgment result: Outputs the recognition judgment result, i.e., OK or NG.
-
Recognition status: Used to indicate whether recognition is successful; true for success, false for failure.
-
Image with result: Outputs an image with detection results.
After checking the relevant ports, the 2D Target Object Recognition Step will add the corresponding output ports in real time.