信息识读(字符识别)
本文将介绍字符识别场景下的工件识别配置流程。该方式用于识别目标物体表面印刷、刻印或喷墨的字符,提取型号、批次等关键信息。
单击配置向导,选择信息识读场景,并选择字符识别方式,即可进入该配置流程。
使用流程
整体识别流程包括四个步骤:

-
图像预处理:对输入图像进行色彩转换、增强、降噪、形态学变换等预处理,提升图像质量,突出目标物体特征并减少背景干扰,为后续字符识别提供可靠的数据基础。
-
位姿对齐:设置识别区域,并通过对齐操作使识别目标与模板对齐。可根据识别目标特征选择合适的校正方式,灵活配置参数,消除位置与角度偏差,提升识别准确性和结果可靠性。
-
信息识读:根据实际需求,在对齐后的图像中设置检测用的目标区域,并设置相关参数和判定规则,准确读取并解析字符内容,验证其格式和内容准确性。
-
通用设置:配置输出端口,输出识别结果和关键信息,满足产线自动化检测和数据追溯需求。
图像预处理
在识别目标物体之前,可根据输入图像质量,选择开启转换图像色彩空间或图像预处理,进行相应的参数调整,使图像特征更清晰,从而提高识别的准确度和效率。
转换图像色彩空间
转换图像色彩空间可以将输入图像从一种色彩空间转换为另一种色彩空间,例如从 BGR 转灰度图、BGR 转 HSV等。通过色彩空间的转换,可以更好地突出图像特征,方便后续图像处理。
具体参数说明和调参案例请阅读 转换图像色彩空间。
位姿对齐
完成图像预处理后,进行位姿对齐设置。通过设置识别区域和校正参数,将当前图像中识别目标的位姿修正为与模板一致,确保后续识别的准确性与可靠性。
添加校正设置
进入位姿对齐流程后,需要新建校正参数组。系统支持创建多个参数组,每个参数组都可以独立设置识别区域和参数,互不影响。
单击添加按钮,进入新建参数组窗口。在创建参数组时,需要根据图像特征选择合适的校正方式,并配置相应参数。
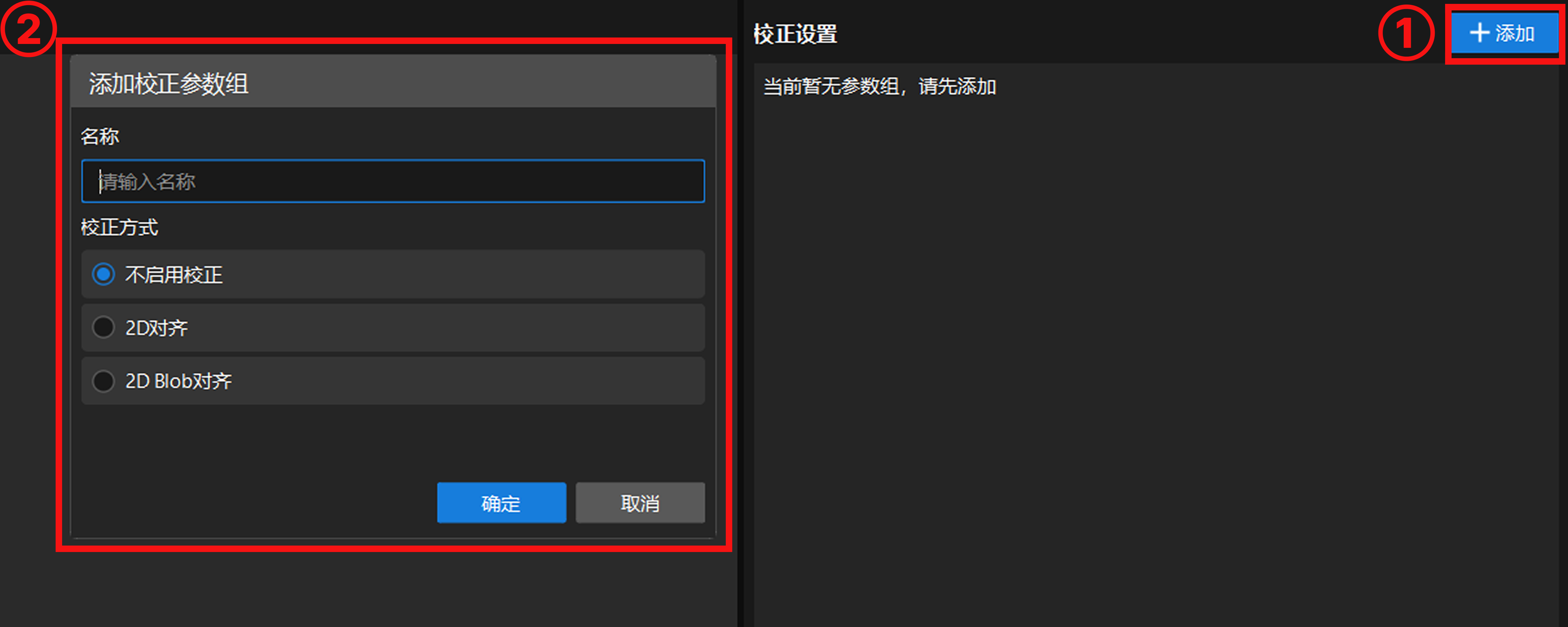
目前支持以下三种校正方式:
-
不启用校正:直接使用原始输入图像进行识别,不进行任何位姿对齐处理。适用于识别目标在图像中的位置相对固定、对校正精度要求不高的场景。
-
2D 对齐:通过平移和旋转操作,将识别目标的位姿与模板对齐。该方式可提取识别目标的边缘轮廓,并采用边缘匹配算法实现精准对齐,适用于识别目标位置不固定,具有明显固定轮廓的场景。具体配置可阅读 2D 对齐。
-
2D Blob 对齐:用于检测图像中的明暗区域(即 Blob)。根据 Blob 的几何特征(如面积、质心等)筛选出目标 Blob,并计算其最小外接旋转矩形。随后调整图像位姿,使目标 Blob 的质心与图像中心点重合,并将其最小外接旋转矩形的主轴与图像坐标轴对齐。具体配置可阅读 2D Blob 对齐。
完成参数组创建后,右键单击参数组名称,或直接单击其右侧的功能按钮,即可执行重命名、删除或创建副本等操作。
2D 对齐
2D 对齐是一种通过平移和旋转操作,使输入图像中的识别目标与模板对齐的校正方式。可消除因识别目标位置不一致带来的识别误差,提升识别稳定性。选择该方式后,需要依次完成识别区域设置、模板设置和识别参数调优。
设置识别区域
用于设置对齐的有效范围。框选时需完全覆盖识别目标,并在其四周预留适当余量,以确保对齐操作的稳定性和后续识别的准确性。可根据实际需求,选择全部为识别区域或自定义识别区域。选择自定义后,需单击“框选”按钮手动框选识别区域。
-
全部为识别区域:对整张图像进行识别,通常适用于识别目标分布较广的场景。
-
自定义识别区域:仅对框选区域进行识别,通常适用于只需关注图像中某一部分,或希望排除无关区域(如背景、夹具等干扰)的场景,有助于提升识别效率和准确率。
识别工件
设置工件模板
在设置好识别区域后,选择或编辑模板,用于后续识别目标的定位与匹配。单击编辑按钮,进入 2D 匹配模板编辑器。
应从图像中选取具有代表性且稳定的边缘特征生成模板,以确保系统后续能够在图像中自动搜索并准确定位与模板特征一致的工件,同时保证匹配结果的唯一性与稳定性。详细说明请参考 2D 匹配模板编辑器。
| 每次完成模板编辑后,需单击更新以应用最新配置。 |
调整识别参数
选择模板后,可单击运行步骤查看模板匹配结果和识别效果。
若识别效果不理想,可根据识别目标的特征和需求调整其他参数,以优化识别效果。
具体参数说明请参考 2D 对齐。
随后,单击下一步进入防错检查流程。
2D Blob 对齐
2D Blob 对齐是一种基于 Blob 的校正方式。该方式从图像中检测所有 Blob,并筛选出几何特征最显著的 Blob,随后调整图像位姿,使目标 Blob 的质心与图像中心点重合,并将其最小外接旋转矩形的主轴与图像坐标轴对齐。选择 2D Blob 对齐后,需要依次完成识别区域设置和识别参数调优。
信息识读
对齐图像后,对图像中的字母、数字等字符进行智能识别。通过图像采集、目标区域设置,结合深度学习训练与验证,可输出字符识别结果。
采集图像
采集用于训练模型的图像数据。
-
确认当前步骤的输入端口已接入图像数据。
-
进入工具时,相机将自动采集一张图像数据用于模型训练,你可单击采集图像按钮,采集新的图像数据训练模型。
|
采集图像时,建议覆盖生产现场的典型变化,包括:
多样化的图像有助于模型适应实际环境,提升判定准确率。 |
设置目标区域
采集图像后,需要设置目标区域以限定字符识别范围。
-
单击编辑按钮,进入目标区域设置界面。
-
设置单个字符大小。
系统将在可视化区域自动生成一个橙色的默认字符大小矩形框。选中后,通过拖拽边框即可调整其大小。为确保模型推理精度,请将该框调整至与实际字符尺寸相近的大小,过大或过小均会影响识别效果。
若可视化区域中未显示字符大小区域,请检查“显示字符大小区域”开关是否已开启。
-
设置目标区域。提供两种方式:
设置方式 说明 全部为目标区域
ROI 自动覆盖整张图像。适用于目标字符占满图像的场景。如需排除部分区域,可在下一步设置屏蔽区。
自定义目标区域
选择“矩形”或“圆环”框选工具,在可视化区域拖拽绘制 ROI。请根据目标字符的实际位置和形状,准确框选目标区域,避免包含无关背景。
-
矩形框选:直接拖拽绘制矩形 ROI。
-
圆环框选:参考下图沿圆周拖拽绘制圆环 ROI。绘制完成后,需设置环形文字读取方向为顺时针或逆时针。

-
-
设置屏蔽区域(可选)。
当目标区域内存在反光、阴影或固定背景等无关干扰时,可通过设置屏蔽区域将其排除,避免影响模型训练和分类判定结果。
单击设置屏蔽区域按钮,使用“多边形”框选工具在可视化区域绘制屏蔽区:单击左键添加多边形顶点,双击右键闭合多边形完成框选。
-
设置完成后,单击 保存并使用,应用目标区域配置。
|
当字符大小区域、目标区域和屏蔽区域的掩膜完全重叠时,仅置顶的图层支持编辑。
|
模型验证与优化
完成目标区域设置后,单击验证按钮进入验证界面。
设置验证参数并验证模型效果
你可在验证界面查看或设置如下参数,并观察模型的识别结果是否符合预期。
| 参数 | 说明 |
|---|---|
验证结果 |
参数解释:显示字符识别结果。启用判定后,将根据设置的判定条件显示验证结果为 OK 或 NG。 |
耗时 |
参数解释:显示单次推理耗时(单位:ms)。 |
置信度阈值 |
参数解释:模型识别字符的最低置信度标准。低于此值的识别结果将被判定为识别失败。 默认值:0.5 调节说明:推荐使用默认值。 |
校正字符内容 |
参数解释:用于约束识别结果前 N 位字符的类型。输入的通配符数量决定约束的字符位数,超出长度的后续字符不受影响。当某位字符不符合约束类型时,模型会将其替换为该类型中置信度最高的候选字符。支持通配符:?(任意字符)、$(英文字母)、%(数字)、@(符号)、!(英文大写字母)、&(英文小写字母)。 默认值:关闭。 调节说明:适用于固定格式字符校正,例如前几位有明确类型要求的场景。建议按实际编码规则从左到右填写通配符,避免过度约束导致误改。 调节示例: 已知实际编码格式为“数字 + 英文大写字母 + 数字 + …”,但模型识别结果为 “iR20181102ar06Xd”,首字符被误识别为英文小写字母。 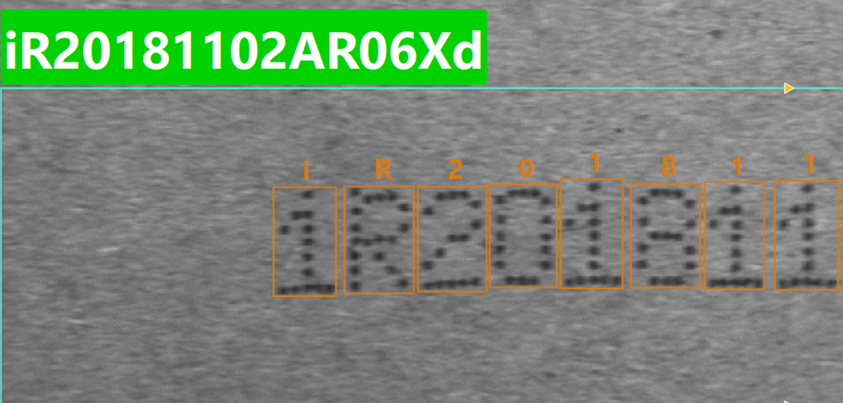
此时在输入框中填入 “%!%”(第 1 位限定为数字,第 2 位限定为英文大写字母,第 3 位限定为数字;第 4 位及之后不受限制),再次推理后,首字符被校正为置信度最高的数字,结果变为 “1R20181102ar06Xd”。 
|
识别对象 |
参数解释:指定从识别结果中读取并参与后续处理的字符类型,未勾选的字符将被忽略。 值列表:英文大写字母、英文小写字母、数字、符号 默认值:全部勾选。 调节说明:根据实际字符内容勾选参与识别的字符类型,减少无关字符干扰,提高模型判定准确率。 |
拼接间隔符 |
参数解释:当识别到多行字符时,指定行与行之间的连接方式。 默认值:无。 调节说明:根据实际需求进行调节。 |
启用判定 |
参数解释:用于验证识别结果是否符合预期。可限定字符类型、字符数量或固定格式,不符合规则的结果将判定为 NG。支持两种判定模式:
默认值:关闭。 调节说明:用于自动合格性检查。固定格式验证选手动输入模式,动态内容验证选全局变量模式。 |
追加训练并优化模型效果(可选)
如在验证过程中发现识别结果不准确(如字符误识别、漏识别或背景误检),可通过“追加训练”功能进行定向修正,直至模型效果满足实际需求。
|
出现以下情况时建议进行追加训练:
|
具体操作流程如下:
-
在验证界面单击追加训练按钮,进入追加训练页面。
-
根据问题类型添加追加内容:
追加内容 说明 操作 识别内容
用于修正漏识别或误识别。在图像上框选未被正确识别的字符区域,输入该位置的正确字符内容,将其添加为训练内容。
-
单击添加按钮,在可视化区绘制矩形框选字符区域。
-
输入正确字符,单击空白处确认添加。
-
单击推理下一张图像,系统将基于已添加的内容更新模型,并在新采集的图像上进行推理验证。重复上述步骤,直至训练内容标注完成。
排除内容
用于消除背景误检。在图像上框选被错误识别为字符的区域,将其标记为忽略区域,该区域的识别结果将被剔除。
-
单击添加按钮,在可视化区域拖拽绘制排除区域,松开鼠标即完成添加。
-
单击推理下一张图像,系统将基于已添加的内容更新模型,并在新采集的图像上进行推理验证。重复上述步骤,直至排除内容标注完成。
-
-
单击训练按钮,使用追加训练的内容进行模型再训练。训练完成后,系统自动返回验证界面,可验证优化后的识别效果。
当前机制下,追加训练中标注的字符不受验证规则中的“校正字符内容”和“识别对象”限制,仍可能出现在识别结果中。为避免识别结果与验证规则冲突,建议仅追加与校正字符内容、识别对象一致的训练内容。
-
验证通过后,单击保存并使用按钮,保存模型配置。
至此,模型配置已完成。单击下一步进入通用设置流程。