AI文字認識ツール
機能
「AI文字認識ツール」 は、ディープラーニングをベースとした可視化OCRツールです。さまざまな文字に対するカスタム学習に対応しています。ウィザード形式の設定手順に従うことで、画像取得からモデル推論までの一連の流れを迅速に構築できます。このツールは、金属刻印文字、曲面上の文字、複雑な背景を含む文字など、従来のアルゴリズムでは処理が難しいシーンでよく利用されます。
このツールには事前学習済みモデルが組み込まれているため、目標領域を設定するだけで推論を実行でき、一からモデルを学習する必要はありません。ユーザーは検証結果に応じて追加学習を行い、必要に応じてモデル性能を最適化することができます。

-
画像を取得:モデルの検証および最適化に使用する画像データを取得します。実際の生産環境における代表的な状況を十分にカバーできるよう、画質と多様性を備えた画像を取得することを推奨します。これにより、モデルの判定精度を向上させることができます。
-
ROI設定:取得した画像上で目標領域(ROI)を設定します。長方形またはリング形のROIに対応しており、文字領域を正確に囲むことで、後続の認識処理における対象範囲を限定できます。
-
モデルの検証と最適化:取得した画像を使用してモデルの認識性能を検証します。実際の要件に応じて、正解文字列、認識対象範囲、判定条件、および文字列の連結ルールを設定できます。認識結果が期待どおりでない場合は、「追加学習」 機能を利用して画像を追加し、モデルを重点的に最適化することで、実運用に必要な性能が得られるまで改善できます。
使用手順
ツールを開いた後、左側のモデルリストの右上にある 新規作成 をクリックし、新しいモデル設定フローを作成して開始します。
画像取得
モデル検証・最適化用の画像データを取得します。
-
現在ステップの入力ポートに画像データが接続されていることを確認してください。
-
ツールを開くと、カメラが自動的に1枚の画像を取得し、モデル検証用データとして使用します。必要に応じて、画像を取得 をクリックし、新しい画像を取得してモデル検証に使用できます。
|
画像取得時には、生産現場における代表的な変化条件を含めることを推奨します。
多様な画像を使用することで、モデル性能をより包括的に検証できるだけでなく、その後のモデル最適化の効率向上にもつながります。 |
目標領域を設定
画像取得後、文字認識範囲を限定するため、目標領域(ROI)を設定する必要があります。
|
「対象物の位置姿勢」ポートに入力がある場合、ROI は対象物の位置姿勢に合わせて同期的に変換されます。ここで設定するROIは基準位置であり、実際の認識時には位置合わせパラメータに基づいて動的に位置補正されます。 |
-
編集 をクリックすると、目標領域設定画面が表示されます。
-
単一文字のサイズを設定します。
システムは、可視化エリア内にオレンジ色のデフォルト文字サイズ長方形枠を自動生成します。長方形枠を選択した後、枠線をドラッグすることでサイズを調整できます。モデル推論精度を確保するため、実際の文字サイズに近い大きさへ調整してください。大きすぎる場合や小さすぎる場合は、認識性能に影響を与える可能性があります。
可視化エリア内に文字サイズ領域が表示されない場合は、「文字サイズ領域を表示」スイッチが有効になっているか確認してください。
-
目標領域を設定します。以下の2つの方法をサポートしています。
設定方式 説明 すべてを目標領域として設定
ROI が画像全体を自動的に覆います。目標文字が画像いっぱいに存在する場合に適しています。一部領域を除去したい場合は、次の手順でマスク領域を設定してください。
目標領域をカスタマイズ
長方形またはリング形選択ツールを使用して、可視化エリアでドラッグして ROI を描画します。目標文字の実際の位置や形状に合わせて、不要な背景を含めないよう正確に領域を選択してください。
-
長方形:ドラッグして長方形 ROI を描画します。
-
リング:下図を参考に、円周に沿ってドラッグしてリング形の ROI を描画します。描画後、環状文字の読み取り方向を 時計回り または 反時計回り に設定する必要があります。

-
-
(任意)マスク領域を設定します。
目標領域内に反射、影、固定背景などの不要要素が存在する場合は、マスク領域を設定することで除外できます。これにより、モデルトレーニングおよび分類判定への影響を防止できます。
マスク領域を設定 をクリックし、ポリゴン範囲選択ツールを使用して表示領域内にマスク領域を描画してください。左クリックで頂点追加、右ダブルクリックでポリゴンを閉じて設定完了となります。
-
設定完了後、保存して適用 をクリックして目標領域設定を適用します。
|
文字サイズ領域、目標領域、マスク領域のマスクが 完全に重なった場合、最前面レイヤ のみ編集可能です。
|
モデルの検証と最適化
目標領域の設定完了後、検証 をクリックすると検証画面が表示されます。
検証パラメータを設定してモデル性能を検証
検証画面では、以下のパラメータ確認・設定、およびモデル認識結果確認を行えます。
| パラメータ | 説明 |
|---|---|
検証結果 |
パラメータ説明: 文字認識結果を表示します。判定を有効化すると、設定した判定条件に基づいて、検証結果が OK または NG として表示されます。 |
処理時間 |
パラメータ説明: 1回あたりの推論処理時間(ms)を表示します。 |
信頼度しきい値 |
パラメータ説明:モデルが文字を認識する際の最低信頼度基準です。この値を下回る認識結果は、認識失敗として判定されます。
|
文字内容を補正 |
パラメータ説明:認識結果の先頭 N 文字の種類を制約します。入力したワイルドカード数が制約対象の文字数を決定し、それ以降の文字は制約されません。ある位置の文字が指定タイプに一致しない場合、モデルはそのタイプ内で最も信頼度の高い候補文字に置き換えます。サポートするワイルドカード:?(任意文字)、$(英字)、%(数字)、@(記号)、!(英大文字)、&(英小文字)。 初期値:無効 調整説明:先頭数文字に明確な形式制約がある固定フォーマット文字列の補正に適しています。実際のコード規則に従い、左から順にワイルドカードを入力してください。過度な制約は誤補正につながる可能性があります。 調整例: 実際のコード形式が「数字 + 英大文字 + 数字 + …」であることが既知であるにもかかわらず、モデル認識結果が iR20181102ar06Xd となり、先頭文字が英小文字として誤認識されたとします。 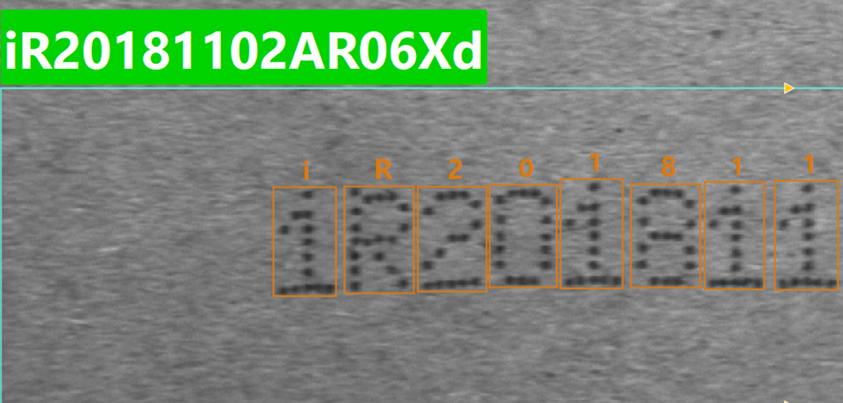
この場合、%!% を入力します(1 文字目:数字、2 文字目:英大文字、3 文字目:数字、4 文字目以降は制限なし)。再推論後、先頭文字は最も信頼度の高い数字に補正され、結果は 1R20181102ar06Xd になります。 
|
認識 |
パラメータ説明:認識結果から後続処理に使用する文字種を指定します。チェックを入れない文字種は無視されます。
|
結合区切り文字 |
パラメータ説明:複数行文字を認識した場合の行間連結方法を指定します。
|
判定を有効化 |
パラメータ説明:認識結果が期待どおりかを検証します。文字タイプ、文字数、固定フォーマットを制限でき、条件に一致しない場合は NG と判定されます。以下の2種類の判定モードに対応します。
初期値:無効 調整説明:自動的な合否判定に使用します。固定フォーマットの検証には「手動入力モード」を使用し、動的内容の検証には「グローバル変数モード」を使用してください。 |
追加学習によるモデル精度の最適化(任意)
検証中に認識結果が不正確な場合(文字の誤認識、未認識、背景の誤検出など)は、「追加学習」機能を使用して重点的に修正し、実運用要件を満たすまでモデル性能を最適化できます。
|
以下のような場合には、追加学習の実施を推奨します。
|
詳細な手順は以下の通りです。
-
検証画面で 追加学習 をクリックし、追加学習ページへ移動します。
-
問題の種類に応じて、追加内容を設定します。
追加内容 説明 操作 認識内容
未認識または誤認識を修正します。画像上で正しく認識されていない文字領域を選択し、その位置の正しい文字内容を入力して学習データとして追加します。
-
追加 をクリックし、可視化エリアで長方形選択により文字領域を指定します。
-
正しい文字を入力し、空白部分をクリックして追加を確定します。
-
次の画像を推論 をクリックすると、追加内容をもとにモデルが更新され、新しく取得した画像で推論検証が実行されます。必要に応じて上記手順を繰り返し、学習内容のラベル付けを完了してください。
各クラスでラベル付け可能な画像の最大枚数は 30 枚です。
除去内容
背景の誤検出を除去します。文字として誤認識された領域を指定し、無視領域として設定することで、その領域の認識結果を除去します。
-
追加 をクリックし、可視化エリアでドラッグして除去領域を描画します。マウスを離すと追加が完了します。
-
次の画像を推論 をクリックすると、追加内容をもとにモデルが更新され、新しく取得した画像で推論検証が実行されます。必要に応じて上記手順を繰り返し、除外内容のラベル付けを完了してください。
-
-
トレーニング をクリックし、追加学習内容を使用してモデルを再トレーニングします。トレーニング完了後、自動的に検証画面へ戻り、最適化後の認識結果を確認できます。
現在の仕様では、追加学習でラベル付けした文字は、検証ルール内の「文字内容補正」および「認識対象」の制限を受けません。そのため、認識結果にそれらの文字が含まれる場合があります。検証ルールとの不整合を避けるため、追加学習には「文字内容補正」および「認識対象」と一致する内容のみを追加することを推奨します。
-
検証完了後、保存して適用 をクリックし、モデル設定を保存します。
追加学習後も効果が改善しない場合は、取得した画像を Mech-DLK にインポートし、Mech-DLK 上で学習を行うことで、より高性能なモデルを取得できます。
これでモデル設定は完了です。ツールを閉じた後、「モデル名」パラメータのドロップダウンリストから作成したモデルを選択すると、後続の推論ステップでそのモデルを利用して文字認識を行うことができます。