ディープラーニングを使用
以下はディープラーニングのワークフローについての説明です。全体のワークフローを下図に示します。

-
事前準備:モデルをトレーニングする前に、画像データの取得やIPC型番の選定など、関連する準備作業が必要です。
-
モデルのトレーニング:準備作業が整ったら、Mech-DLKで用意したデータを使用してモデルのトレーニングと認証を行います。
-
モデルの設定と使用:モデルのトレーニングが完了したら、Mech-Visionでモデルを設定し、関連するステップでそのモデルを使用してタスクを実行します。
-
モデルの追加学習:モデルを使用して現場のニーズを満たさない場合、モデルの追加学習を行う必要があります。
事前準備
IPCの選定
Mech-DLKを使用してモデルをトレーニングする際には、IPCは以下の最小要件を満たすことをお勧めします。
ソフトウェアライセンスバージョン |
Pro-Run |
Pro-Train/Standard |
|---|---|---|
オペレーティングシステム |
Windows 10以上 |
|
CPU |
Intel® Core™ i7-6700以上 |
|
メモリ |
8 GB以上 |
16 GB以上 |
グラフィックスカード |
GeForce GTX 1660以上 |
GeForce RTX 3060以上 |
グラフィックスカードのドライバー |
バージョン 472.50以上 |
|
|
Pro-Runバージョンには、Mech-DLK SDKの展開、ラベル付け、実行モードの機能が揃っています。Pro-Trainバージョンには、モジュールの接続、ラベル付け、トレーニング、検証、Mech-DLK SDKの展開機能が揃っています。Standardバージョンにはラベル付け、トレーニング、検証の機能が揃っています。 |
画像取得プロジェクトの作成
IPCが用意されたら、画像取得プロジェクトを作成できます。特別な画像取得プロジェクトを新たに作成する必要はありません。ビジネスの実際の要件に基づいて作成されたビジョンプロジェクトを使用して、画像取得を行います。
ビジョンプロジェクトが作成されたら、プロジェクトを実行する際に画像を指定の場所に保存するために、 データの保存 機能を有効にする必要があります。
-
データ保存画面に移動します。Mech-Visionのプロジェクト設定エリアの下部で プロジェクトアシスタント をクリックし、
 をクリックしてデータ保存の画面に入ります。
をクリックしてデータ保存の画面に入ります。 -
データ保存機能を有効にします。データ保存画面で データとパラメータを保存 を有効にします。
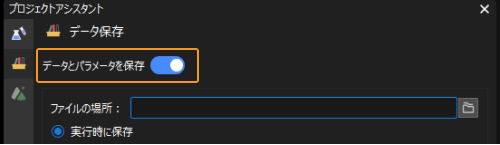
-
画像の保存パスを設定します。取得した画像データを保存するために、データ保存画面で ファイルの場所 を設定します。通常はプロジェクトフォルダ内の「data」フォルダに保存します。
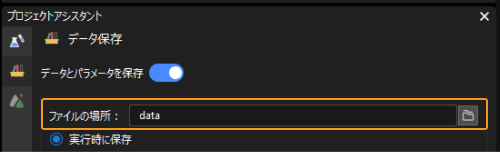
画像データの取得
ビジョンプロジェクトが作成および設定されたら、画像データの取得を開始できます。
画像品質の確認(取得前)
画像品質はモデルの安定性を決定し、高品質の画像データは通常モデルの認識効果と予測の精度を向上させることができます。したがって、画像データを取得する前に、カメラのホワイトバランスと2D露出パラメータを調整し、取得される画像が完全で切り取られていないことを確認する必要があります。
ホワイトバランスの調整
ホワイトバランスは、カメラや写真撮影において、撮影される画像の中の白色が実際の白に見えるように色調整するための機能や調整のことを指します。
色が歪んだ2D画像を使用してディープラーニングモデルをトレーニングすると、色の偏りがトレーニングの対象物特性として使用されるため、後続のモデルに影響します。したがって、正常なホワイトバランスの画像データを取得するためには、データの取得前にホワイトバランスを調整する必要があります。詳細については、 ホワイトバランスの調整 をご参照ください。
露出パラメータの調整
モデルのトレーニング時に、画像中の対象物の様々な特徴(色情報、輪郭形状情報など)が抽出されます。画像が過度に露出したり、過度に暗い場合、上記の特徴情報はある程度失われる可能性があり、モデルのトレーニングで重要な情報を学習できなくなり、後続のモデルに影響します。したがって、高品質な画像データを得るためには、データを取得する前にカメラの露出パラメータを調整する必要があります。詳細については、 カメラのパラメータ をご参照ください。
画像数量の確認(取得時)
画像データを取得する際には、十分な量の画像を取得し、モデルのトレーニングに使用するために画像の多様性を確保する必要があります。異なる種類のワークには異なる画像取得数の要件があるため、注意が必要です。
画像の多様性を確保するためには、通常、プロジェクトを手動でトリガーして画像を取得する方法が使用されます。プロジェクトを1回実行するごとに、ワークの位置や配置を手動で調整する必要があります。
|
「剛体ワーク」とは、運動や力の影響を受けても形状とサイズが変わらず、内部の各点の相対的な位置が変わらないワークを指します。 |
異なる状況での剛体ワークの画像取得数の要件を確認するには、こちらをクリックしてください。
| 同種類のワーク | 複数種類のワーク(非混載) | 複数種類のワーク(混載) | 多面体のワーク | |
|---|---|---|---|---|
整列して並べられている場合 |
40~60枚 |
40~60枚 |
60~80枚 |
80~100枚 |
バラ積みされている場合 |
60~80枚 |
ワークの種類ごとに40~60枚 |
100枚 |
100~120枚 |
取得された剛体ワークの画像には 複数のセル が含まれ、 異なる向き 、 異なる配置間隔 、 異なる高さ および 異なる照明条件 が反映される必要があります。
異なる状況での麻袋の画像取得数の要件を確認するには、こちらをクリックしてください。
| 麻袋に中身が入っている状態で、整列して並べられている場合 | 麻袋が緩く積まれ、表面にしわが多い場合 | |
|---|---|---|
画像取得数 |
20枚 |
30枚 |
取得された麻袋の画像には、異なる種類/層の麻袋 、異なる配置/供給方法/パレットパターン 、異なる光照条件 が反映される必要があります。
異なる状況での段ボール箱の画像取得数の要件を確認するには、こちらをクリックしてください。
| 同じ種類の段ボール箱 | 複数種類の段ボール箱(混載) | バラ積みされている段ボール箱 | その他の状況(テープやラベルが貼られているか、結束バンドで固定しているかなど) | |
|---|---|---|---|---|
画像取得数 |
最上層から空のパレットまで合計30枚の画像を取得する必要があります。 |
各種類ごとにそれぞれ20枚の画像を取得する必要があります。 |
50枚の画像を取得する必要があります。
|
50枚 |
取得された段ボール箱の画像には、異なる種類/層の箱 、箱の異なる配置/供給方法/パレットパターン 、異なる光照条件 が反映される必要があります。
画像のフィルタリング(取得後)
画像データの取得が完了したら、低品質な画像を削除し、高品質な画像を保持し、かつ画像の多様性を確保するために、画像をフィルタリングする必要があります。
剛体ワークおよび麻袋/段ボール箱の画像フィルタリング要件を確認するには、こちらをクリックしてください。
| 削除すべき画像 | 保持すべき画像 | |
|---|---|---|
剛体ワーク |
|
|
麻袋/段ボール箱 |
|
|
モデルのトレーニング
上記の準備ができたら、取得した画像を使用してMech-DLKでモデルをトレーニングできます。モデルのトレーニングフローは以下の通りです。
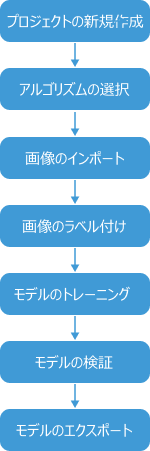
-
プロジェクトの新規作成:モデルをトレーニングするためのプロジェクトを作成します。
-
アルゴリズムの選択:実際の要件に基づいてディープラーニングアルゴリズムモジュールを選択します。
-
画像のインポート:モデルをトレーニングするために、取得した画像データをインポートします。
-
画像のラベル付け:画像にラベルを付け、モデルのトレーニングに必要な情報を提供します。
-
モデルのトレーニング:選択したディープラーニングアルゴリズムモジュールを使用して、ラベル付け画像でモデルをトレーニングします。
-
モデルの検証:モデルのトレーニングが完了したら、モデルを検証してその効果を確認します。
-
モデルのエクスポート:モデルに問題がないことを確認したら、モデルを指定された場所にモデルパッケージとしてエクスポートします。
詳細な操作手順については、 インスタンスセグメンテーションモジュールの使用例 をご参照ください。
モデルの設定と使用
モデルパッケージを取得したら、Mech-Visionで設定を行い、それを関連するステップで推論に使用する必要があります。詳細な手順については、 ディープラーニングモデルパッケージ管理ツールの使用ガイド をご参照ください。
モデルの追加学習
モデルを使用して現場のニーズを満たさない場合、モデルの追加学習を行う必要があります。従来はデータセットを追加して再度トレーニングを行いますが、全体の正確度が落ちるほか、時間もかかります。「微調整」機能を使用すると、正確度を影響せずに時間も削減できます。詳細については、 ディープラーニングモデルの追加学習 をご参照ください。
上記の手順が完了したら、以下の動画チュートリアルに従ってインスタンスセグメンテーションモデルのトレーニングと使用を実践できます。