使用文本识别模块
以识别码数据(单击下载)为例,本文将展示如何使用“文本识别”模块训练出可识别和输出图像中字符(数字、字母及部分特殊符号)的模型。
| 用户可使用自己准备的数据。整体使用流程一致,标注环节存在差异。 |
-
新建工程并添加“文本识别”模块:单击初始页面上的新建工程按钮,选择工程路径并输入工程名称以新建一个工程。然后,单击右上角的
 ,选择“文本识别”模块。
,选择“文本识别”模块。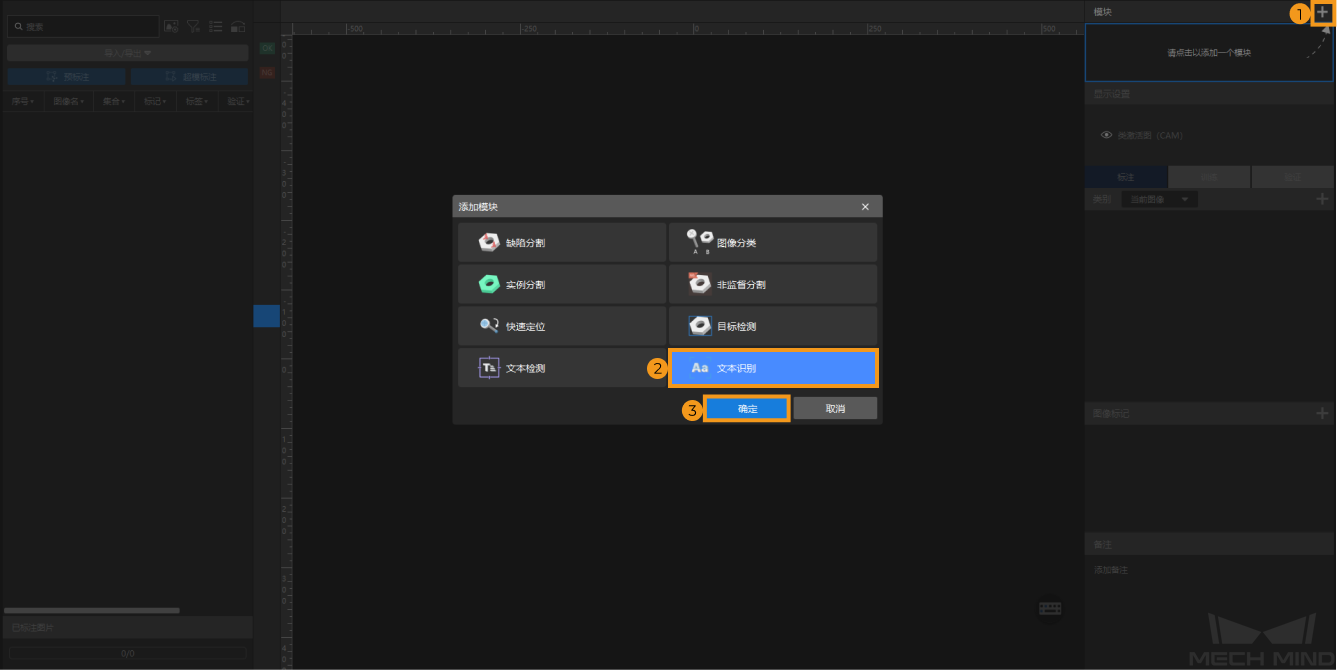
-
导入图像数据:解压缩下载的压缩包,单击左上方的导入/导出按钮,选择 导入文件夹 导入下载的识别码图像数据。
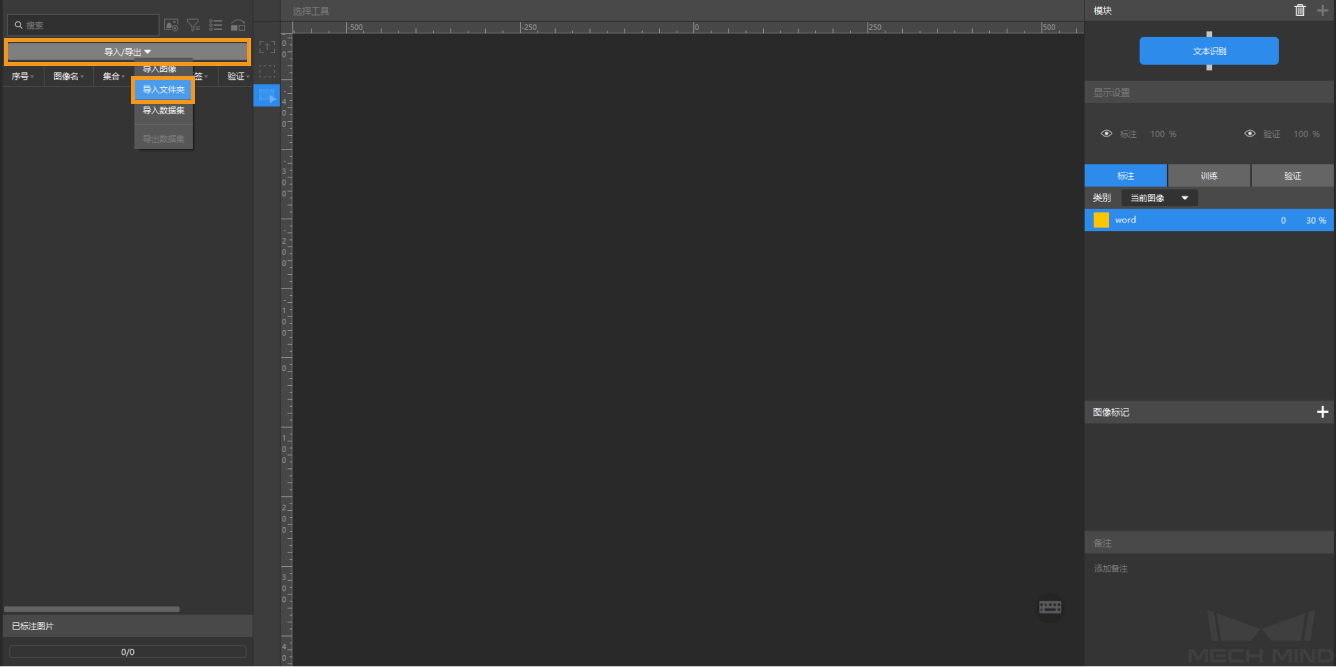
-
导入图像中,待识别文本应尽量为正方向(0°)。
-
“文本识别”模块可前置“文本检测”或“目标检测”模块来提升模型效果,导入数据时应选择 。
-
若前置的是“文本检测”模块,导入数据时确认“图像校正”功能已开启(默认开启)。通常,“图像校正”功能可校正图像至 0°,但也有可能将少数 0° 图像校正至 180°,建议根据实际情况判断是否开启该功能。
-
-
选择导入数据集选项时,此模块仅支持导入 DLKDB 格式(.dlkdb)的数据集,即仅限于从 Mech-DLK 中导出的数据集。
-
-
截取 ROI:单击 ROI 工具
 ,框选能涵盖所有图像中文本区域的部分作为感兴趣区域,并单击 ROI 边框右下角的
,框选能涵盖所有图像中文本区域的部分作为感兴趣区域,并单击 ROI 边框右下角的  应用当前ROI。截取 ROI 的目的是减少无关背景信息的干扰。
应用当前ROI。截取 ROI 的目的是减少无关背景信息的干扰。
-
标注图像:在图像左侧标注工具栏选择“文本识别工具”进行标注。使用“文本识别工具”框选文本后,会自动生成识别结果,需人工校验和确认。因此,标注时绘制有效的标注框并及时确定正确的结果有助于提升模型质量。
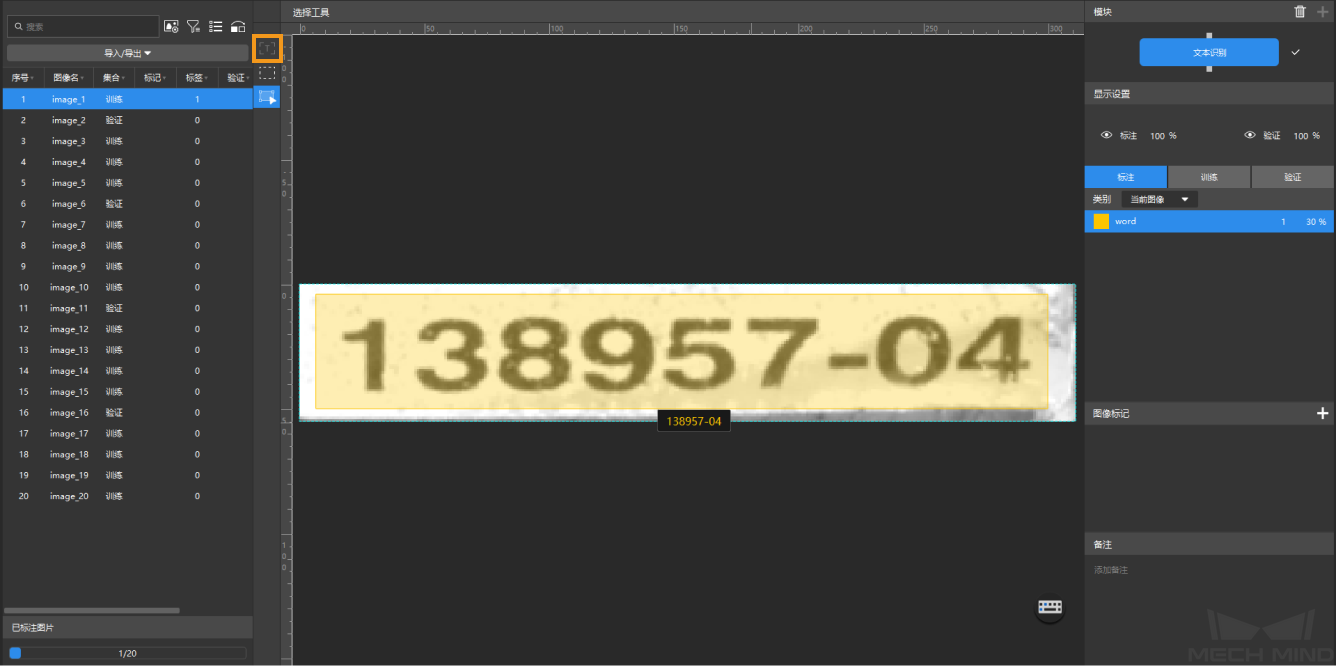
-
划分训练集与验证集:软件默认将数据集的 80% 划分为训练集,20% 为验证集,可以单击
 拖动滑块调整图像占比。需要确保划分后的训练集和验证集中涵盖所有需要识别的文本类型,如果默认划分的数据集不满足这一条件,右键单击图像名称后选择“移到训练集”或“移到验证集”调整图像所属集合。
拖动滑块调整图像占比。需要确保划分后的训练集和验证集中涵盖所有需要识别的文本类型,如果默认划分的数据集不满足这一条件,右键单击图像名称后选择“移到训练集”或“移到验证集”调整图像所属集合。
-
训练模型:使用默认参数设定,单击训练 开始训练模型。

-
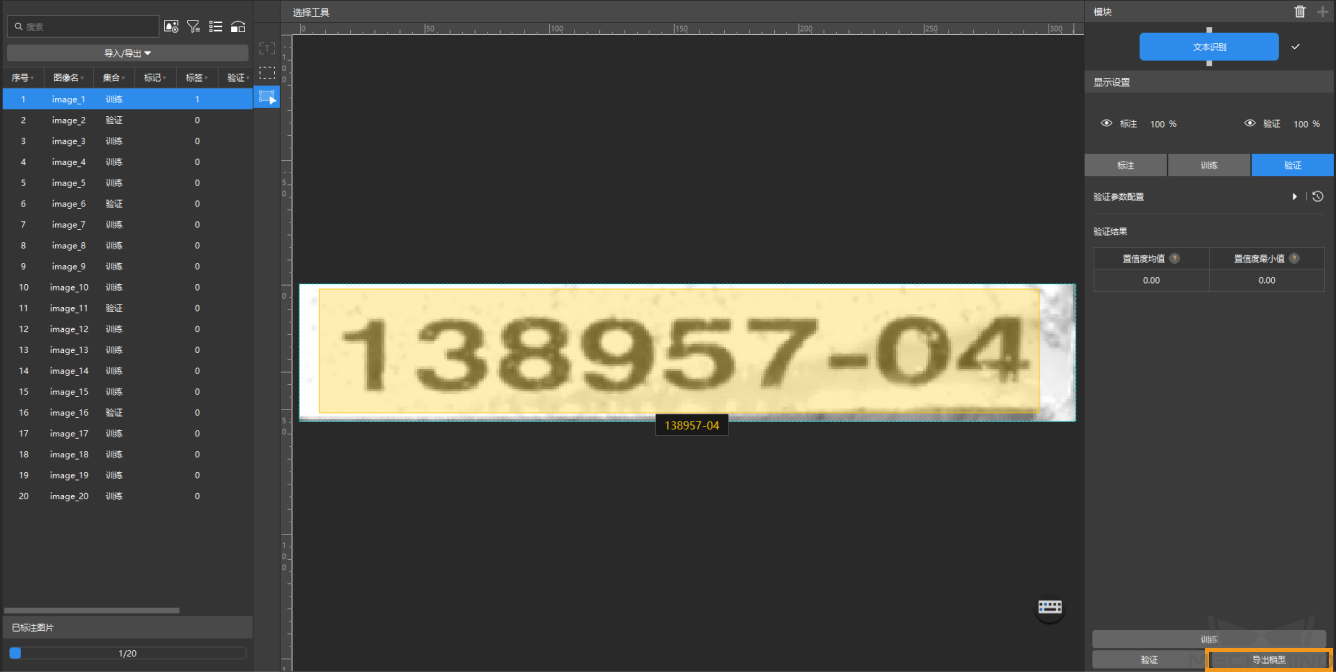
验证模型:训练结束后,单击验证 可以验证并查看模型识别效果。
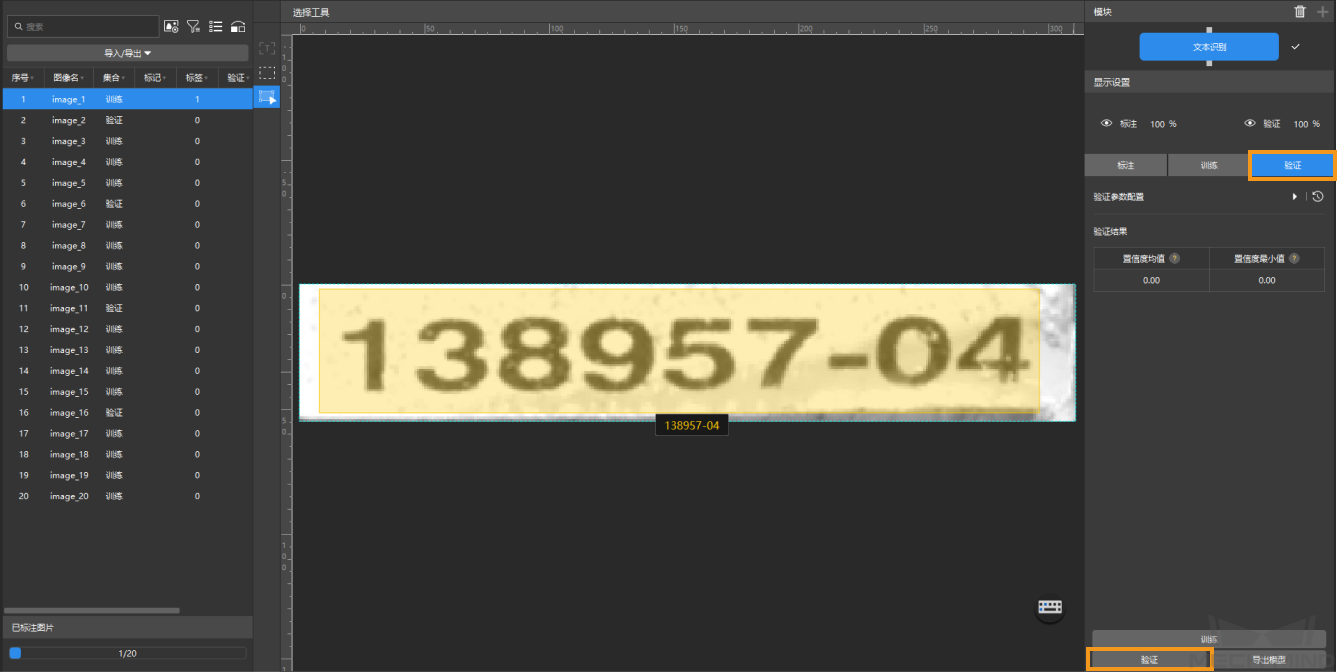
-
导出模型:单击导出模型,然后选择存放路径,即可导出模型。
导出后的模型可在 Mech-Vision 与 Mech-DLK SDK 中使用,单击此处 查看详细说明。