Deploy Models – Instance Segmentation for 3D Robot Guidance
Instance Segmentation models can be used in 3D robot guidance to recognize and locate target objects. This section demonstrates how to deploy and use such a model in Mech-Vision.
Currently, you can import a deep learning model package into Mech-Vision by using the following two methods:
-
Use the Deep Learning Model Package Inference Step.
-
Use the Assist recognition with deep learning feature of the 3D Target Object Recognition Step.
The second method is generally recommended, as it enables combining deep learning-assisted segmentation with 3D matching, making project debugging easier. This section demonstrates how to apply an Instance Segmentation model in Mech-Vision using this method.
The process consists of four steps: importing the deep learning model package, checking the 2D ROI, configuring the confidence threshold, and tuning the dilation parameter settings.
Import a Deep Learning Model Package
-
Open the Mech-Vision project and click the Config wizard button in the 3D Target Object Recognition Step to open the production interface.
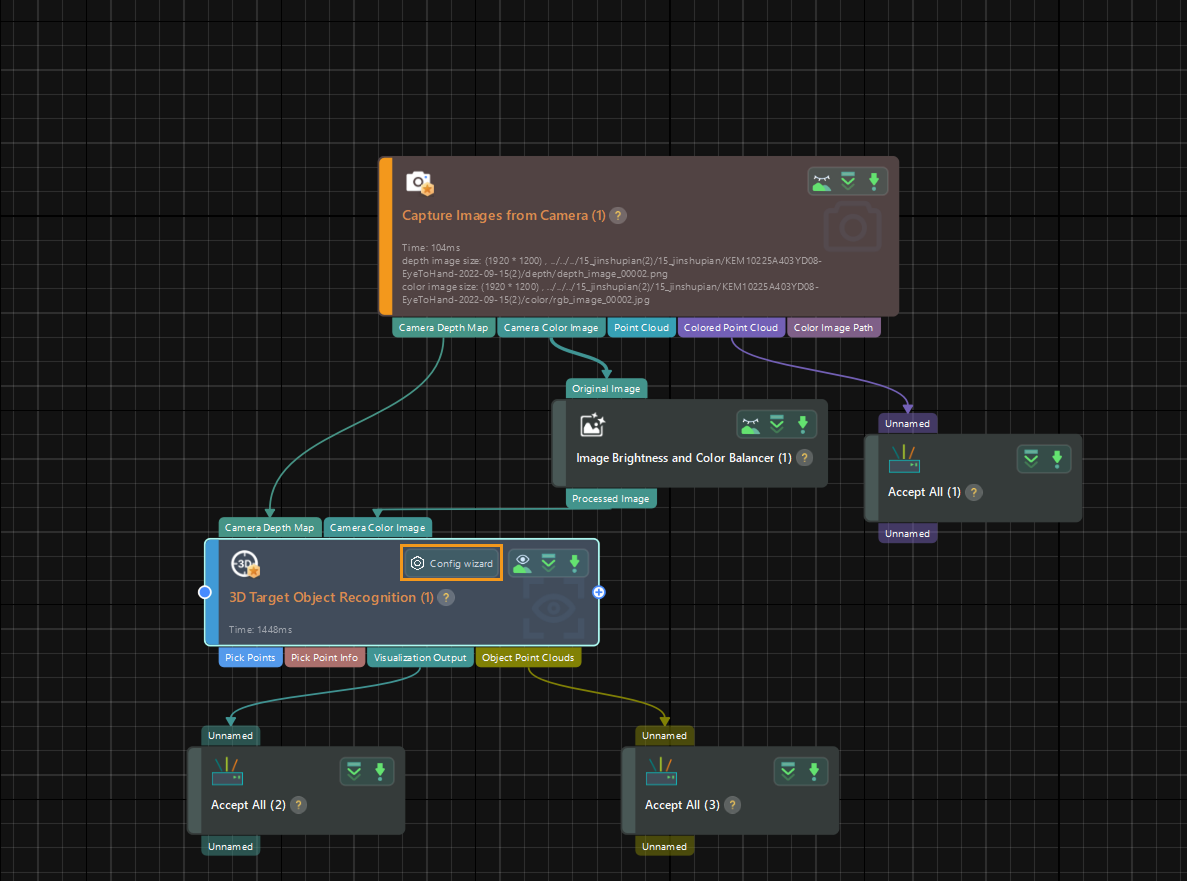
-
In the Target object selection and recognition step, enable Assist recognition with deep learning. Click Model package management tool. In the Deep Learning Model Package Management window, click the Import button and select the trained deep learning model package.
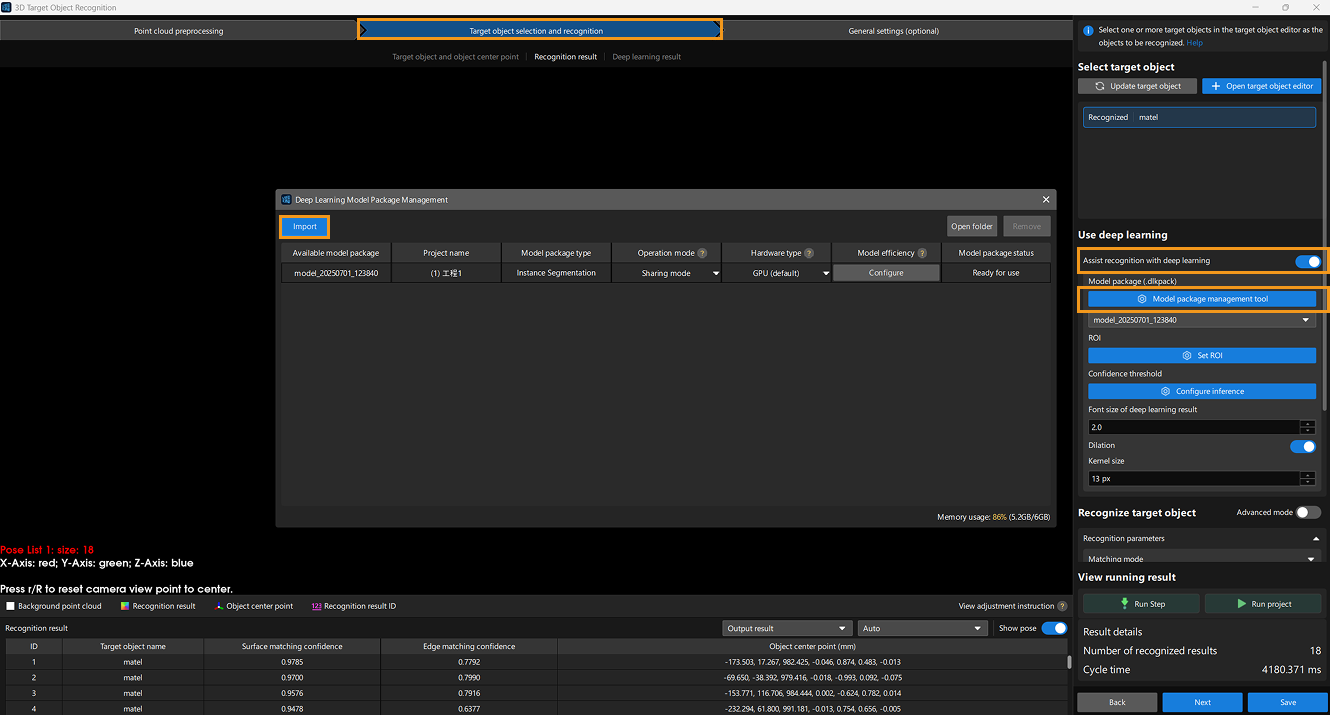
-
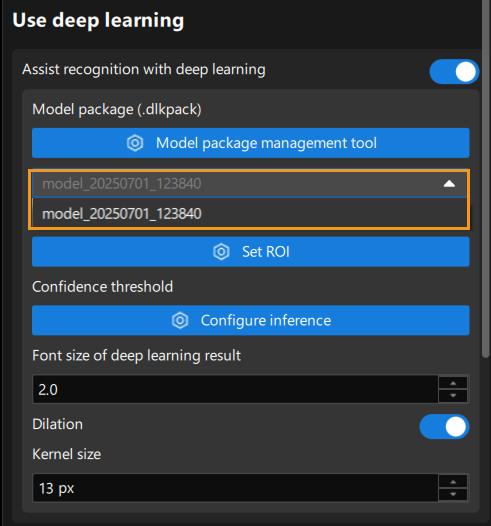
In the Target object selection and recognition step, select the imported package.
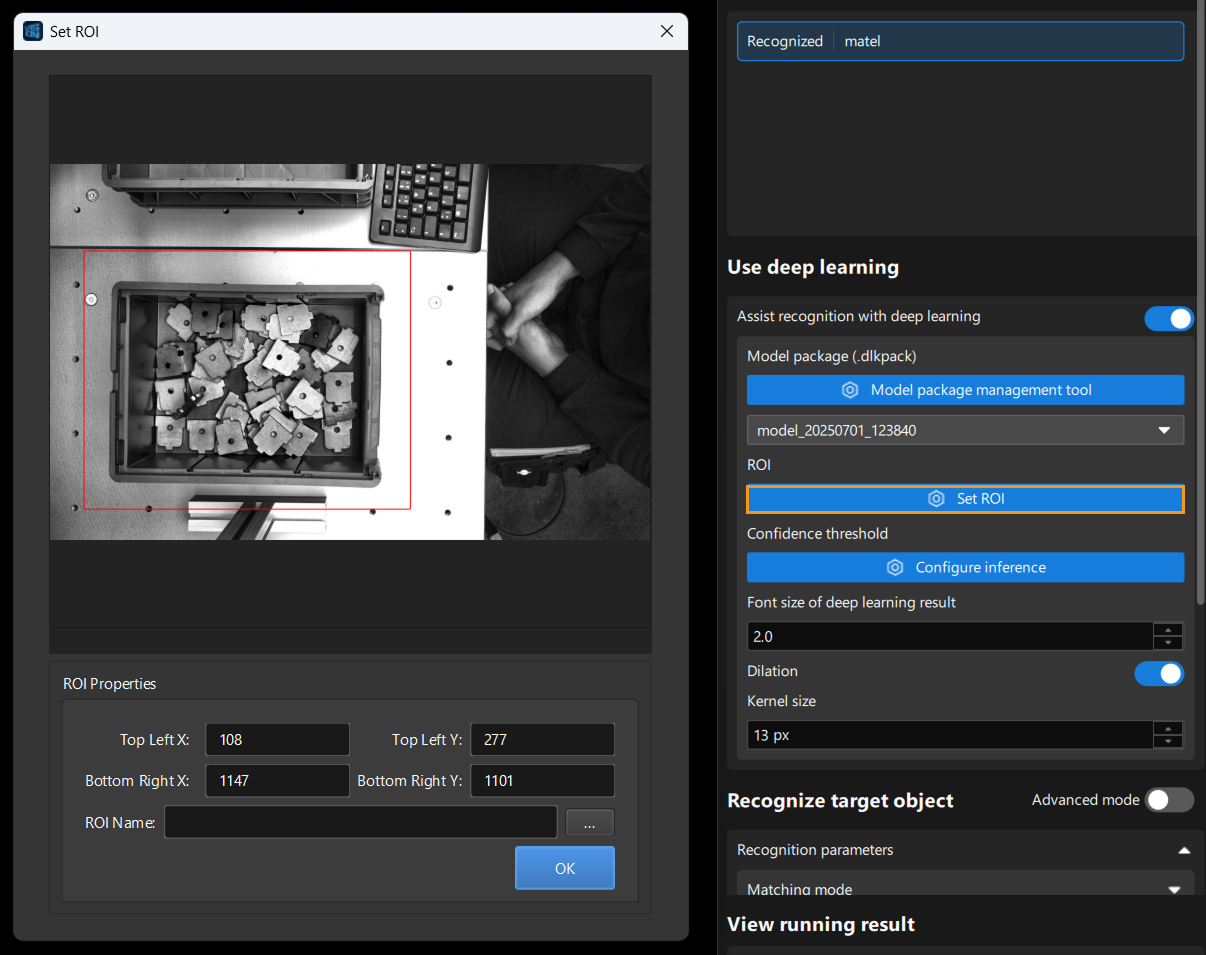
Check 2D ROI
To improve recognition accuracy, you need to set a 2D ROI. Note that the ROI here defaults to the same range as the one set in Mech-DLK during training. If any objects fall outside the ROI, you can adjust it accordingly. However, if the adjusted ROI differs too much from the original, it may affect the model performance. In such cases, you should re-specify a proper ROI during training.
Set Confidence Threshold
Switch to the Deep learning result interface and click the Configure inference button. In the Interface Configuration window, set Confidence threshold of Instance Segmentation to filter out results with low confidence or suboptimal segmentation. Adjustments showed that a confidence threshold of about 0.6 gives optimal mask performance.
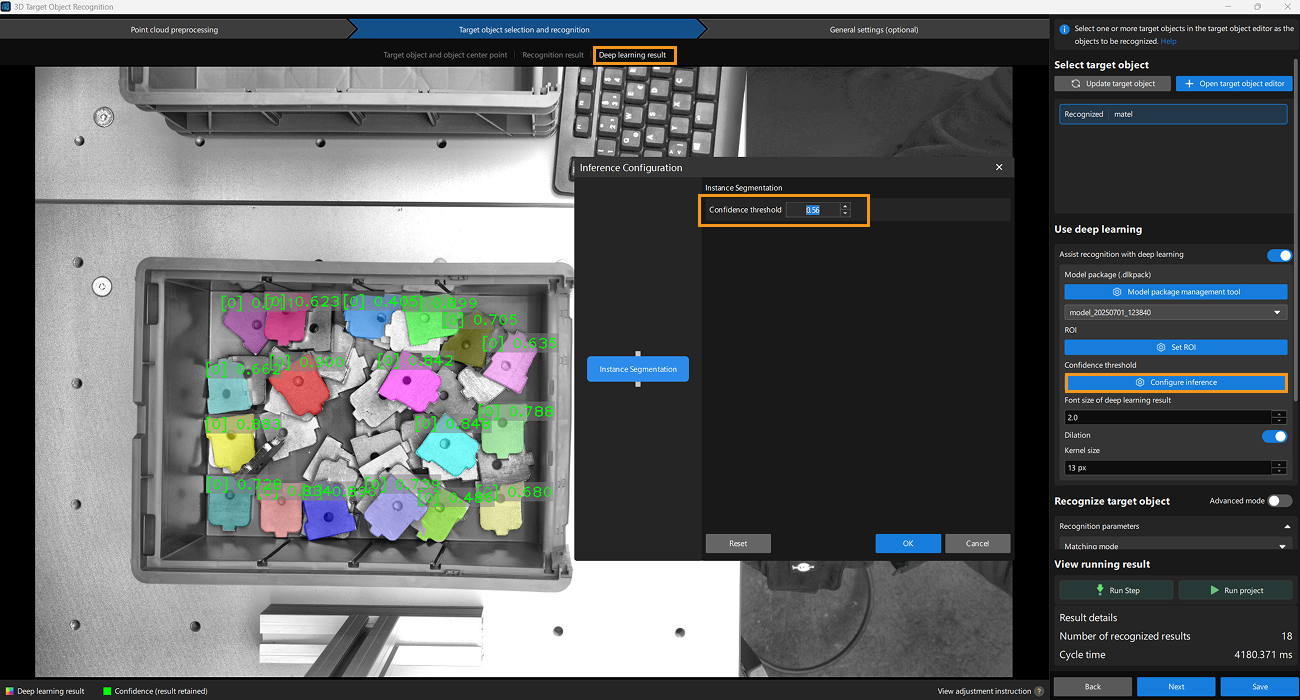
You can run the Steps to see the results.
Adjust Dilation Parameter Settings
Dilation parameters are used to ensure that the deep learning model can produce complete edge mask information, enabling the acquisition of full point cloud data of the object. Before use, you can switch to the Recognition result interface to view the current point cloud. In this case, the edge point cloud is sufficient and performs as expected, so no changes to the dilation parameters are needed.
This completes the import and configuration of the Instance Segmentation model package in the Mech-Vision project. You can now run the Mech-Vision project to identify the object.
Supplementary Information: Optimization Methods
If the recognition results are unsatisfactory, you can run the Capture Images from Camera Step to check the image status. If the image is not clear enough or the edges are blurry, you can use the Image Brightness and Color Balancer Step to adjust the image contrast. This Step balances color and brightness, helping to improve edge detection and object recognition.
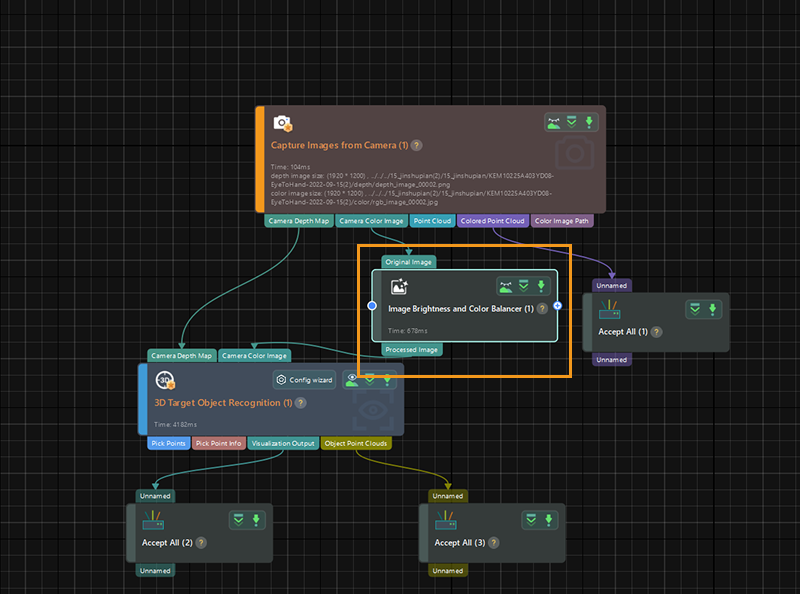
You will notice a clear improvement in the image after this Step.

If the image quality meets the requirements after improvement but the recognition results are still unsatisfactory, model iteration is needed. Use the inaccurately recognized images as training data to retrain the deep learning model and then apply the new model for subsequent use.