Data Acquisition Standard
When training a deep learning model, the model will extract and learn features of the objects in the images, such as colors, contours, and positions. If images are overexposed, dim, color-distorted, blurred, or occluded, these conditions can lead to the loss of features that the deep learning model relies on, which will affect the model training effect.
This topic describes the preparations before image acquisition, considerations during acquisition, and data selection standards after acquisition, helping you acquire high-quality images that improve model recognition and accuracy.
Preparations before Acquisition
Reduce Ambient Light Interference
Mech-DLK can resist the impact of interference of ambient lighting to some extent. When there is a moderate variation in ambient light, deep learning can still operate effectively. However, if the ambient light changes are significant, the lighting environment may differ from reality, and the details of the objects in the images can be lost, which affects the performance of model training.
Significant changes in ambient light typically refer to:
-
Significant differences in ambient light between day and night (direct sunlight, normal lighting, no lighting/low lighting)
-
Significant fluctuations in brightness of artificial light sources
-
Significant fluctuations in color temperature
-
Other changes in lighting that could significantly affect the pixel values of color images
If your working environment cannot avoid significant changes in ambient light, you can take the following measures:
-
Design appropriate shading or supplementary lighting solutions according to project requirements.
-
Choose the type of camera that suits your project requirements. If you only need to distinguish the contour of objects, you can use a monochrome camera. If you also need to distinguish the colors of objects, using a color camera can yield better results.
-
In Mech-Eye Viewer, adjust the 2D parameters such as exposure mode and white balance of the camera to ensure that the acquired images match the actual working environment.
| If the image outside the ROI is overexposed while the image inside the ROI is normal, you do not need to process the image. |





Ensure Application Consistency
Ensure that the background, perspective, and height of the acquired images are consistent with the actual application. Any inconsistency can reduce the effect of deep learning in practical applications. In severe cases, data must be acquired again. Please confirm the conditions of the actual application in advance.



Considerations during Acquisition
During acquisition, various placement conditions need to be properly allocated. For example, if there are horizontal and vertical incoming materials in actual production, but only the data of horizontal incoming materials are acquired for training, the classification effect of vertical incoming materials cannot be guaranteed. Therefore, when acquiring data, it is necessary to consider various conditions of the actual application, including the following:
-
Ensure that the acquired dataset includes all possible object placement orientations in actual applications.
-
Ensure that the acquired dataset includes all possible object positions in actual applications.
-
Ensure that the acquired dataset includes all possible positional relationships between objects in actual applications.
| If any of the representations among the above three is missed in the dataset, the deep learning model will not be able to learn the features properly and therefore cannot recognize the objects correctly. A dataset with sufficient samples will reduce errors. |
Object placement orientations
Object positions
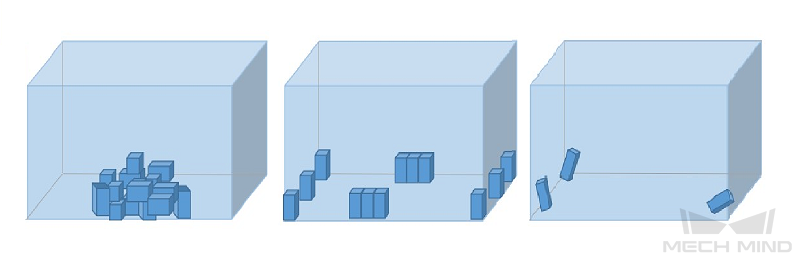
Positional relationships between objects
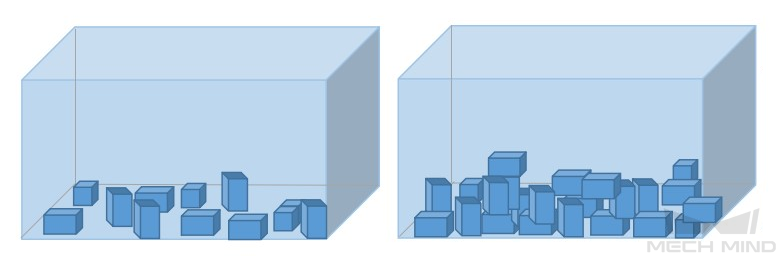

Selection Standards after Acquisition
-
Control the image quality and quantity of training set
When you first use some modules, it is recommended to control the quality and quantity of images in the training set.
-
High-quality images can ensure better model training. Poor images or irrelevant images may do damage to model training.
-
It is not true that the larger the number of images the better. Adding a large number of inadequate images in the early stage is not conducive to model improvement later, and will make the training time longer.
Module Suggested Image Quantity in Training Set Instance Segmentation
30–50
Defect Segmentation
20–30 (adjust based on the defect types and differences)
Classification
30
Object Detection
30
Fast Positioning
40
Text Detection
30–50
Text Recognition
40
Unsupervised Segmentation
30–50 OK images
-
-
Acquire representative data
-
Image acquiring should consider all the conditions in terms of illumination, color, size, etc. of the objects to be recognized.
-
Lighting: Project sites usually have environmental lighting changes, and the data should contain images with different lighting conditions.
-
Color: Objects may come in different colors, and the data should contain images of objects of all the colors.
-
Size: Objects may come in different sizes, and the data should contain images of objects of all existing sizes.
If the actual on-site objects may be rotated, scaled in images, etc., and the corresponding images cannot be acquired, the data can be supplemented by adjusting the data augmentation training parameters to ensure that all on-site conditions are included in the datasets.
-
-
-
Balance data proportion
The number of images of different conditions/object classes in the datasets should be proportioned according to the actual project; otherwise, the training effect will be affected. There should be no such case where 20 images are of one object, and only 3 are of the other object.
-
Images should be consistent with the application site
The factors that need to be consistent include lighting conditions, object features, background, and field of view.