Mech-MSR 딥 러닝 모델 패키지 관리 도구
Mech-MSR에서 딥 러닝 모델 패키지 관리 도구를 사용하여 모델 패키지를 가져올 수 있습니다.
소개
딥 러닝 모델 패키지 관리 도구는 Mech-MSR의 모든 딥러닝 모델 패키지를 효율적으로 관리하도록 설계되었습니다. Mech-DLK 2.6.1 이상 버전에서 내보낸 모델 패키지를 최적화할 수 있으며, 실행 모드, 하드웨어 유형, 모델 효율성, 모델 패키지 상태를 관리할 수 있습니다. 또한 IPC의 GPU 사용량도 실시간으로 모니터링할 수 있습니다.
프로젝트에서 딥 러닝 모델 패키지 추론 스텝을 사용하는 경우, 먼저 모델 패키지를 딥 러닝 모델 패키지 관리 도구에 가져와야 해당 스텝에서 사용할 수 있습니다. 모델 패키지를 사전에 도구에 가져오면, 최적화를 미리 수행할 수 있습니다.
| 딥 러닝 추론을 사용하려면 Pro-Run 또는 Pro-Train 버전의 유효한 Mech-DLK 라이센스가 필요합니다. 라이센스가 없는 경우 Mech-Mind 영업팀에 문의하세요. |
도구 열기
다음 방법 중 하나를 통해 딥러닝 모델 패키지 관리 도구를 열 수 있습니다:
-
프로젝트를 생성하거나 연 후, 상단 메뉴 바에서 menu:'딥 러닝'['딥 러닝 모델 패키지 관리 도구']를 선택합니다.
-
프로젝트 편집 구역에서 '딥 러닝 모델 패키지 추론' 스텝의 구성 마법사 버튼을 클릭합니다.
-
프로젝트 편집 구역에서 '딥 러닝 모델 패키지 추론' 스텝을 선택하고 파라미터 패널에서 모델 패키지 관리 도구 항목 아래 편집기를 열기 버튼을 클릭합니다.
도구 구성
이 도구는 다음과 같은 구성으로 이루어져 있습니다.
| 구성 | 설명 | ||
|---|---|---|---|
사용 가능한 모델 패키지 |
가져온 모델 패키지의 이름입니다. |
||
프로젝트 이름 |
해당 모델 패키지를 사용하는 Mech-MSR 프로젝트입니다. |
||
모델 패키지 유형 |
'텍스트 감지' 및 '텍스트 인식’과 같은 모델 패키지의 유형입니다.
|
||
실행 모드 |
실행 모드 옵션 : 공유 모드, 성능 모드
|
||
하드웨어 유형 |
하드웨어 유형 옵션 : GPU(기본값), GPU(최적화), CPU
|
||
모델 효율성 |
모델 패키지 추론 효율성을 구성할 수 있습니다. |
||
모델 패키지 상태 |
'최적화 중', '준비 완료', '최적화 실패’와 같은 모델 패키지의 상태를 확인할 수 있습니다. |
일반 작업
이 부분에서는 딥 러닝 모델 패키지 관리 도구에 대한 일반적인 작업에 대해 소개합니다.
딥 러닝 모델 패키지 가져오기
-
딥 러닝 모델 패키지 관리 도구를 연 후, 왼쪽 상단의 가져오기 버튼을 클릭합니다.
-
팝업 창에서 가져올 모델 패키지를 선택한 뒤, 열기 버튼을 클릭하면 선택한 모델 패키지가 목록에 추가됩니다.
|
딥 러닝 모델 패키지를 가져오기 위해서는 GPU 드라이버는 최소 버전 472.50 이상이 필요합니다. 단, 버전 500 이상의 드라이버는 딥 러닝 스텝 실행 시간에 변동이 발생할 수 있으므로 사용을 권장하지 않습니다. |
딥 러닝 모델 패키지 제거하기
가져온 딥 러닝 모델 패키지를 제거하려면 먼저 해당 모델 패키지를 선택하고 오른쪽 상단에 있는 제거하기 버튼을 클릭합니다.
|
딥 러닝 모델 패키지가 최적화 중이 거나 사용 중일 때(즉, 모델 패키지를 사용하는 프로젝트가 실행 중일 때) 모델 패키지를 제거할 수 없습니다. |
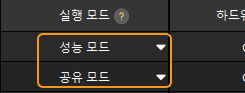
실행 모드 전환
딥 러닝 모델 패키지 관리 도구의 실행 모드 열에서 ![]() 버튼을 클릭하고 공유 모드 또는 성능 모드를 선택하면 됩니다.
버튼을 클릭하고 공유 모드 또는 성능 모드를 선택하면 됩니다.
|
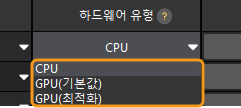
하드웨어 유형 전환
딥 러닝 모델 패키지 추론을 위한 하드웨어 유형을 GPU(기본값), GPU(최적화) 또는 CPU로 변경할 수 있습니다.
딥 러닝 모델 패키지 관리 도구의 하드웨어 유형 열에서 ![]() 버튼을 클릭하고 GPU(기본값), GPU(최적화), CPU 중 하나를 선택합니다.
버튼을 클릭하고 GPU(기본값), GPU(최적화), CPU 중 하나를 선택합니다.
|
딥 러닝 모델 패키지가 최적화 중 또는사용 중일 때(즉, 모델 패키지를 사용하는 프로젝트가 실행 중일 때) 하드웨어 유형을 변경할 수 없습니다. |
모델 효율성 구성
모델 효율성을 구성하는 프로세스는 다음과 같습니다.
-
구성할 딥 러닝 모델 패키지를 결정합니다.
-
모델 효율성 아래의 구성 버튼을 클릭하고 팝업 창에서 배치(Batch) 크기와 정밀도를 설정합니다. 모델의 실행 효율성은 배치 크기와 정밀도 설정에 따라 달라질 수 있습니다.
-
배치 크기(Batch size) : 추론 시 신경망에 한 번에 입력되는 이미지의 개수를 의미합니다. 기본값은 1이며, 변경할 수 없습니다.
-
정밀도 ('하드웨어 유형’이 GPU(최적화) 로 설정된 경우에만 표시)
-
FP32 : 고정밀 모델로, 추론 속도는 느리지만 정확도가 높습니다.
-
FP16 : 저정밀 모델로, 빠른 추론 속도를 제공합니다.
-
-
오류 분석
딥 러닝 모델 패키지 가져오기 실패
문제 증상
가져올 딥 러닝 모델 패키지를 선택한 후, 시스템에서 "딥 러닝 모델 패키지를 가져오지 못했습니다."라는 오류 메시지가 표시됩니다.
가능한 원인
-
동일한 이름의 모델 패키지를 가져왔습니다.
-
동일한 내용이 담긴 모델 패키지를 가져왔습니다.
-
하드웨어와 소프트웨어가 최소 요구 사항을 충족할 수 없습니다.
해결 방법
-
모델 패키지 이름을 수정하거나 같은 이름의 가져온 모델 패키지를 제거합니다.
-
모델 패키지의 내용을 확인합니다. 가져온 모델 패키지와 동일하면 다시 가져올 필요가 없습니다.
-
GPU 드라이버에 필요한 최소 버전이 472.50이고, CPU에 필요한 최소 버전이 6세대 Intel Core인지 확인하세요.