Usage Scenarios of Deep Learning
2D Camera + Deep Learning
The following show the usage scenarios of a 2D camera + deep learning. Use these deep learning modules according to actual needs.
Fast Positioning
You can use the Fast Positioning module to correct the object orientations.
-
Recognizes object orientations in images and rotates these images so that objects in them have a uniform orientation.

Defect Segmentation
You can use the Defect Segmentation module to detect all types of defects. These defects include surface defects, such as stains, bubbles, and scratches, and positional defects, such as bending, abnormal shape, and absence. Moreover, this module can be applied even under complex conditions, such as small defects, complicated background, or random object positions.
-
Detects air bubbles and glue spills on lenses.

-
Detects bending defects of parts.

Classification
You can use the Classification module to recognize the fronts and backs of objects, object orientations, and defect types and to judge whether objects are missing or neatly arranged.
-
Recognizes whether objects are neatly arranged or scattered.

-
Recognizes the fronts and backs of objects.

Object Detection
You can use the Object Detection module to detect the absence of objects in fixed positions, such as missing components in a PCB. You can also use it for object counting.
-
Counts all rebars.

Instance Segmentation
You can use the Instance Segmentation module to distinguish objects of a single type or multiple types and segment their contours.
-
Segments blocks of various shapes.

-
Segments scattered and overlapping track links.

-
Segments cartons closely fitted together.

Text Detection
You can use the Text Detection module to detect the text area in an image and thus reduce the interference from the background.
-
Detects the text areas of an image.
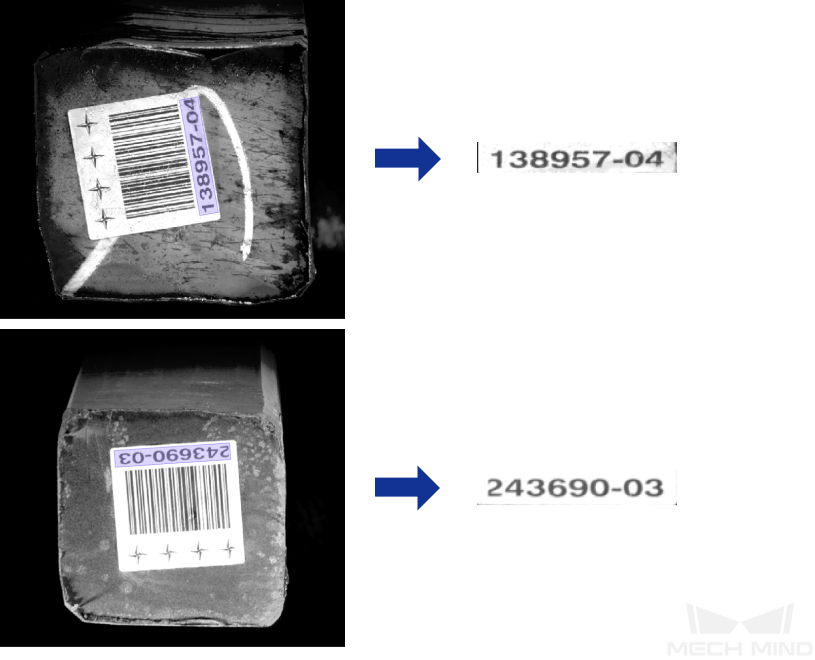
Text Recognition
You can use the Text Recognition module to recognize the text in an image, including letters, numbers, and some special symbols.
-
Recognizes the characters in an image.
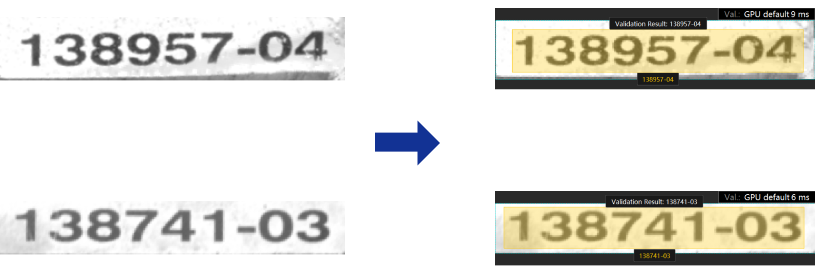
Unsupervised Segmentation
You can use the Text Recognition module to train a model on the basis of only OK images as the training set. The trained model can judge whether an image is OK, NG, or Unknown.
-
Judges whether an image is OK, NG, or Unknown according to set thresholds and displays the possible areas with defects.

3D Camera + Deep Learning
In the following scenarios, the data of point clouds cannot assure accurate recognition and positioning of objects. Therefore, we use 3D matching + deep learning to recognize and position objects.
Seriously Incomplete Point Clouds
The objects in the following figures are used as an example.
-
2D image: In the figure below, large quantities of reflective objects are in contact with each other, but their edges and shape features are clear.

-
Point cloud: As the objects are reflective, the point clouds are incomplete. Analysis shows that missing point clouds are mostly along the target object axis.

If point clouds are incomplete along the target object axis, 3D matching using the point clouds may be inaccurate and thus results in largely deviated picking poses. As the objects are in contact with each other, the point clouds may not be correctly segmented and thus lead to incorrect matching. In addition, the quantity of objects is large, and the vision cycle time will be long.
In such scenarios, you can use the Instance Segmentation module to train the corresponding model and then use the deep learning-related Steps in Mech-Vision to recognize the objects. Then, extract the point cloud corresponding to the mask of the object and calculate its Pose A on the basis of 3D matching. Finally, calculate Pose B on the basis of the extracted point cloud and correct the X and Y components of Pose A.

Key Features Missing from Point Cloud
The objects in the following figures are used as an example.
-
2D image: In the figure below, the objects in the red boxes have their fronts facing up, while the objects in the blue boxes have their backs facing up. The arrows point to key features used to distinguish between fronts and backs.

-
Point cloud: In the point cloud, the key features used to distinguish between fronts and backs of objects are missing.

As the key features used to distinguish object types are very small (even missing from the point cloud), when 3D matching is used to recognize different object types, the matching result may be incorrect, which results in the wrong classification of objects.
In such scenarios, you can use the Instance Segmentation module to train the corresponding model and set corresponding labels for different types of objects. When this model is used in the deep learning-related Steps in Mech-Vision, the Steps will not only extract the masks of each object but also output the type labels of objects.

Almost No Point Cloud of Objects
The objects in the following figures are used as an example.
-
2D image: Wave washers are reflective and are placed close to each other in the bin.

-
Point cloud: The point clouds of the objects are unstable. Chances are that the points of some objects are completely missing.

As many object features are missing from the point clouds, it is impossible to use the point clouds for locating the objects and calculating their poses by 3D matching. When 3D matching is used, incorrect matching with the bin bottom is likely to occur.
In such scenarios, although the objects are reflective, their edges are clear in the 2D images. Therefore, you can use the Instance Segmentation module to train the corresponding model and use this model in the deep learning-related Steps in Mech-Vision. The Steps output object masks, on the basis of which object point clouds are extracted. The poses of these point clouds are then calculated and used as the picking pose.
Recognize Patterns and Colored Region on Object Surface
The objects in the following figures are used as an example.
-
2D image: A piece of yellow tape is attached to one side of the aluminum bin, used to mark the orientation of the bin.

-
Point cloud: The point clouds are good, but the yellow tape cannot be reflected by the point clouds.

As the target feature is a colored region and is only visible in the color image, the orientation of the bin cannot be recognized through the point clouds.
In such scenarios, as long as the rough location of the yellow tape is determined, the orientation of the aluminum bin can also be determined. You can use the Object Detection module to train the corresponding model and use this model in the deep learning-related Steps in Mech-Vision to recognize the objects.

Random Picking from Deep Bin
The objects in the following figures are used as an example.
-
2D image: Steel bars are randomly piled in the bin, and some regions of some steel bars reflect light. In addition, the steel bars overlap each other.

-
Point cloud: For objects not overlapped, their point clouds are good. For overlapped objects, it is difficult to render the point cloud of each object by clustering, and the clustering performance is unstable.
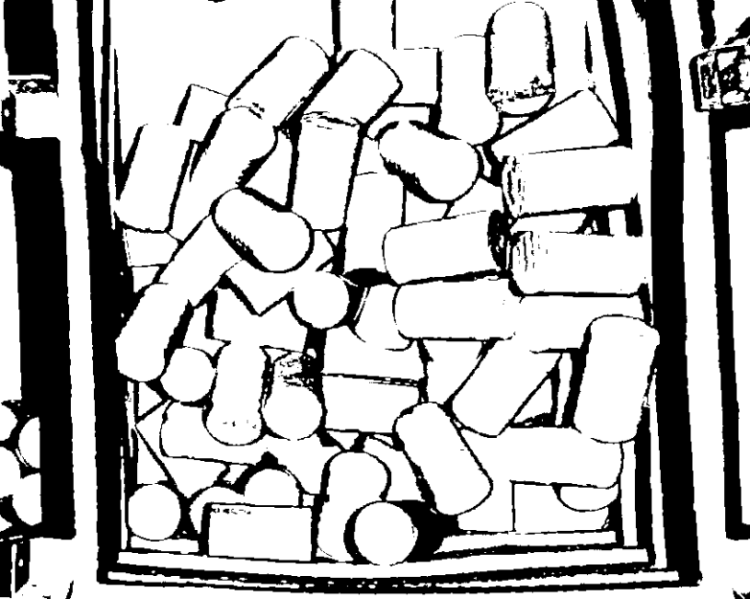
Point cloud clustering cannot stably cluster out the point cloud of each object. It is difficult to train a suitable model for 3D matching in that the orientations of objects vary greatly. 3D matching might also output incorrect matching results, which leads to inaccurate pose calculation. In addition, using only point cloud models for global matching will result in a very long vision cycle time.
In such scenarios, you can use the Instance Segmentation module to train the corresponding model and use this model in the deep learning-related Steps in Mech-Vision to extract the masks of individual objects. Then, extract the point clouds corresponding to the masks and then use the point clouds for the matching of individual objects.

Point Cloud Clustering Fails to Separate Point Clouds of Overlapped Objects
The objects in the following figures are used as an example.
-
2D image: The obtained 2D images are too dark, and object edges may not be discernible. After the image brightness is enhanced, the object edge, size, and grayscale value can be obtained.

-
Point cloud: The point clouds are good, but the objects are in contact with each other. Therefore, the edges of different objects may not be correctly separated.

Although the point clouds are good, but the point clouds of objects stick to each other, so point cloud clustering cannot be used to segment the point clouds of individual objects. Global 3D matching might output incorrect matching results or even matching to the bin.
In such scenarios, you can use the Instance Segmentation module to train the corresponding model. The trained model can be used in the deep learning-related Steps in Mech-Vision to extract the object point clouds and then perform matching.

Recognize and Pick Objects of Different Types
The objects in the following figures are used as an example.
-
2D images: The image on the left is obtained at the station where the objects are randomly placed. The image on the right is obtained at the station where secondary judgment is performed. The quality of the 2D images at both stations is good, and the features of different types of objects are distinctive.

-
Point cloud: The point clouds are good, and the shape features of the objects are clearly reflected in the point clouds.

For cylindrical objects, however, the point clouds cannot reflect the orientation or the type of the object, so using only 3D matching cannot distinguish the object orientation and type.
For the above 2D image on the left, you can use the Instance Segmentation module to train the corresponding model and use the model in the deep learning-related Steps in Mech-Vision to recognize and segment the objects. The Steps will output the corresponding object masks, which can be used for subsequent point cloud processing.

For the above 2D image on the right, you can use the Instance Segmentation module to recognize individual objects and then use the Object Detection module to determine the orientations of objects according to the shape and surface features. (The left figure below shows the instance segmentation result, and the right figure below shows the object detection result of determining the orientations of objects.)
