텍스트 감지 모듈 사용방법
LED 데이터(다운로드)를 예로 들어, 이 부분에서는 텍스트 감지 모듈을 사용해 이미지 내 텍스트 영역을 감지하는 방법을 설명합니다. 텍스트 감지 모듈 뒤에 텍스트 인식 모듈을 추가하면, 감지된 영역에서 숫자, 문자, 특수 기호 등을 인식해 출력할 수 있습니다.
| 또한, 사용자가 직접 준비한 데이터를 사용할 수도 있습니다. 프로세스는 동일하지만, 레이블링 방법에 차이가 있습니다. |
준비 작업
-
새 프로젝트 생성 및 '텍스트 감지' 모듈 추가 : Mech-DLK를 실행한 뒤 시작 화면에서 새로운 프로젝트를 클릭합니다. 프로젝트 경로를 선택하고 프로젝트 이름을 입력해 프로젝트를 생성합니다. 메인 화면에서 입력 모듈 아래의 + 버튼을 클릭하고, 모듈 추가 창에서 텍스트 감지 모듈을 선택합니다.
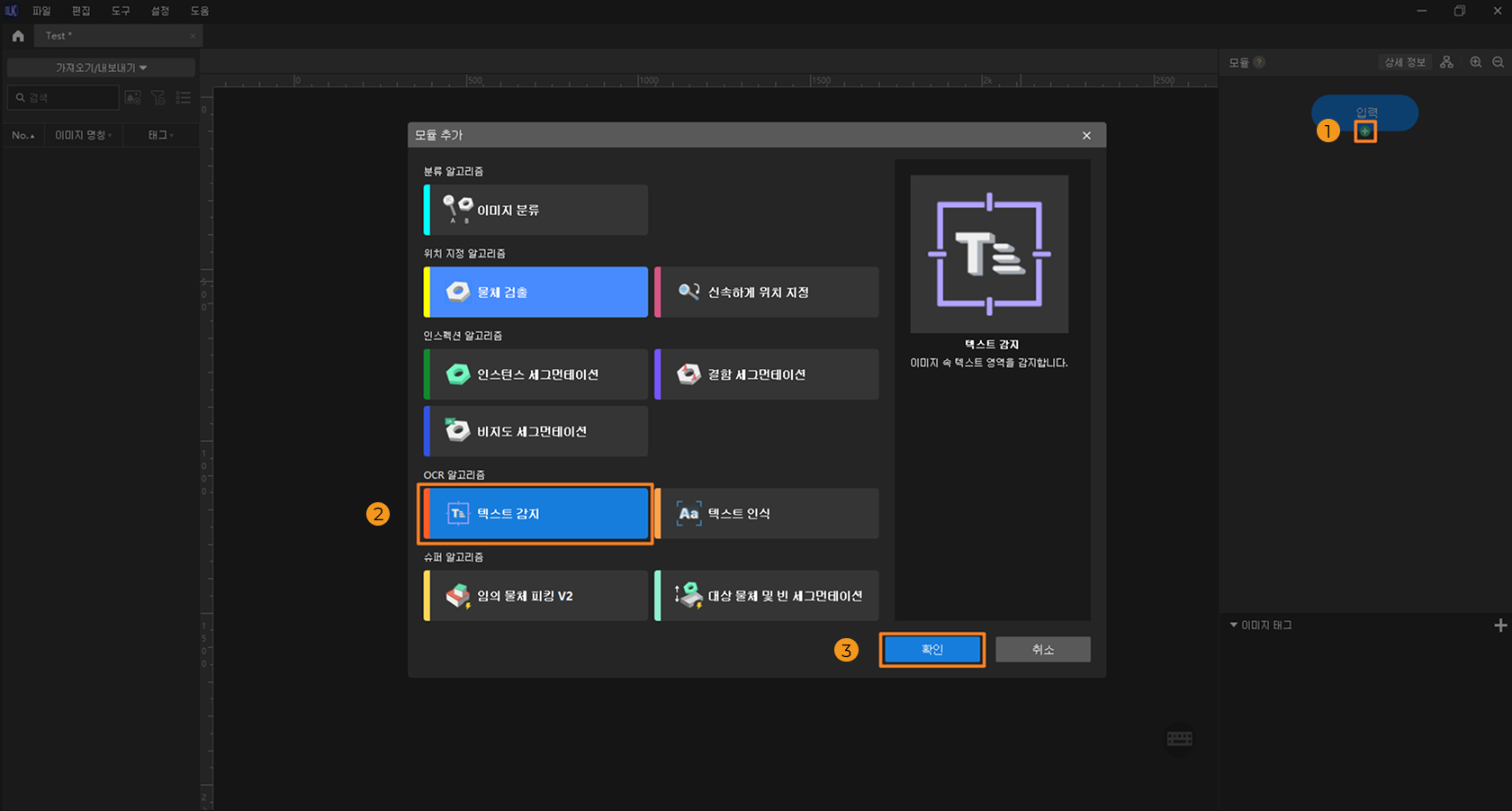
-
이미지 데이터 가져오기 : 수집한 이미지 데이터를 가져오거나 본문에서 제공한 압축 데이터를 해제해 가져옵니다. 다음 방식으로 이미지 데이터 가져오기를 수행할 수 있습니다.
-
방법 1
이미지 또는 폴더를 이미지 목록 영역으로 드래그하여 가져옵니다. 드래그 방식으로는 데이터세트를 가져올 수 없습니다.
-
방법 2
이미지 목록 상단에서 가져오기/내보내기 버튼을 클릭합니다. 데이터 유형에 따라 가져오기 옵션을 선택합니다.
-
이전 모듈에서 가져오기: 이전 모듈의 이미지를 가져옵니다.
-
이미지 가져오기: 단일 또는 다수 이미지를 가져옵니다.
-
폴더 가져오기: 폴더 내 모든 이미지를 가져옵니다(하위 폴더 제외).
-
데이터세트 가져오기: Mech-DLK에서 내보낸 DLKDB 형식(.dlkdb) 데이터세트를 가져옵니다.
-
-
-
ROI 선택 : ROI 도구 버튼(
 )을 클릭한 뒤, 프레임을 조절해 전체 텍스트 영역을 ROI로 지정합니다. 이후, ROI 영역 오른쪽 하단에 있는
)을 클릭한 뒤, 프레임을 조절해 전체 텍스트 영역을 ROI로 지정합니다. 이후, ROI 영역 오른쪽 하단에 있는  버튼을 클릭하여 설정을 저장합니다. ROI를 설정하는 목적은 불필요한 배경의 간섭을 줄이는 것입니다.
버튼을 클릭하여 설정을 저장합니다. ROI를 설정하는 목적은 불필요한 배경의 간섭을 줄이는 것입니다.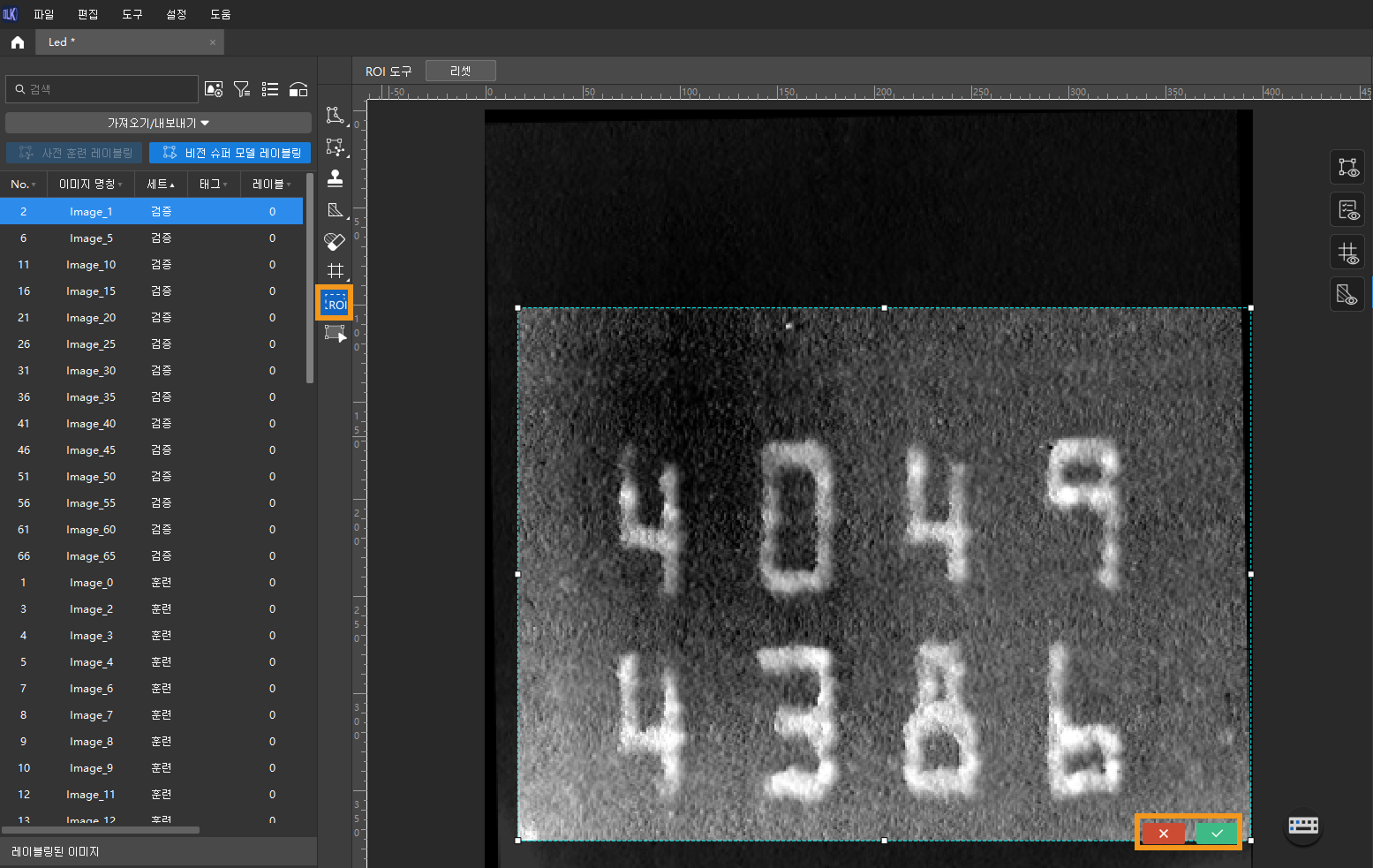
-
훈련/검증 세트의 비율 조정 : 기본적으로 데이터 세트 이미지의 80%는 훈련 세트로, 나머지 20%는 검증 세트로 분할됩니다.
 을 클릭하고 슬라이더를 드래그하여 원하는 비율로 조정할 수 있습니다. 조정된 훈련 세트와 검증 세트에는 감지해야 할 모든 텍스트 영역이 포함되어야 하며, 서로 다른 텍스트 방향을 가진 이미지들도 균형 있게 구성되어야 합니다.
을 클릭하고 슬라이더를 드래그하여 원하는 비율로 조정할 수 있습니다. 조정된 훈련 세트와 검증 세트에는 감지해야 할 모든 텍스트 영역이 포함되어야 하며, 서로 다른 텍스트 방향을 가진 이미지들도 균형 있게 구성되어야 합니다.
이 조건을 충족하지 않는 경우, 이미지 이름을 마우스 오른쪽 버튼으로 클릭한 뒤 훈련 세트로 옮기기 또는 검증 세트로 옮기기를 선택하여 데이터 세트를 조정할 수 있습니다.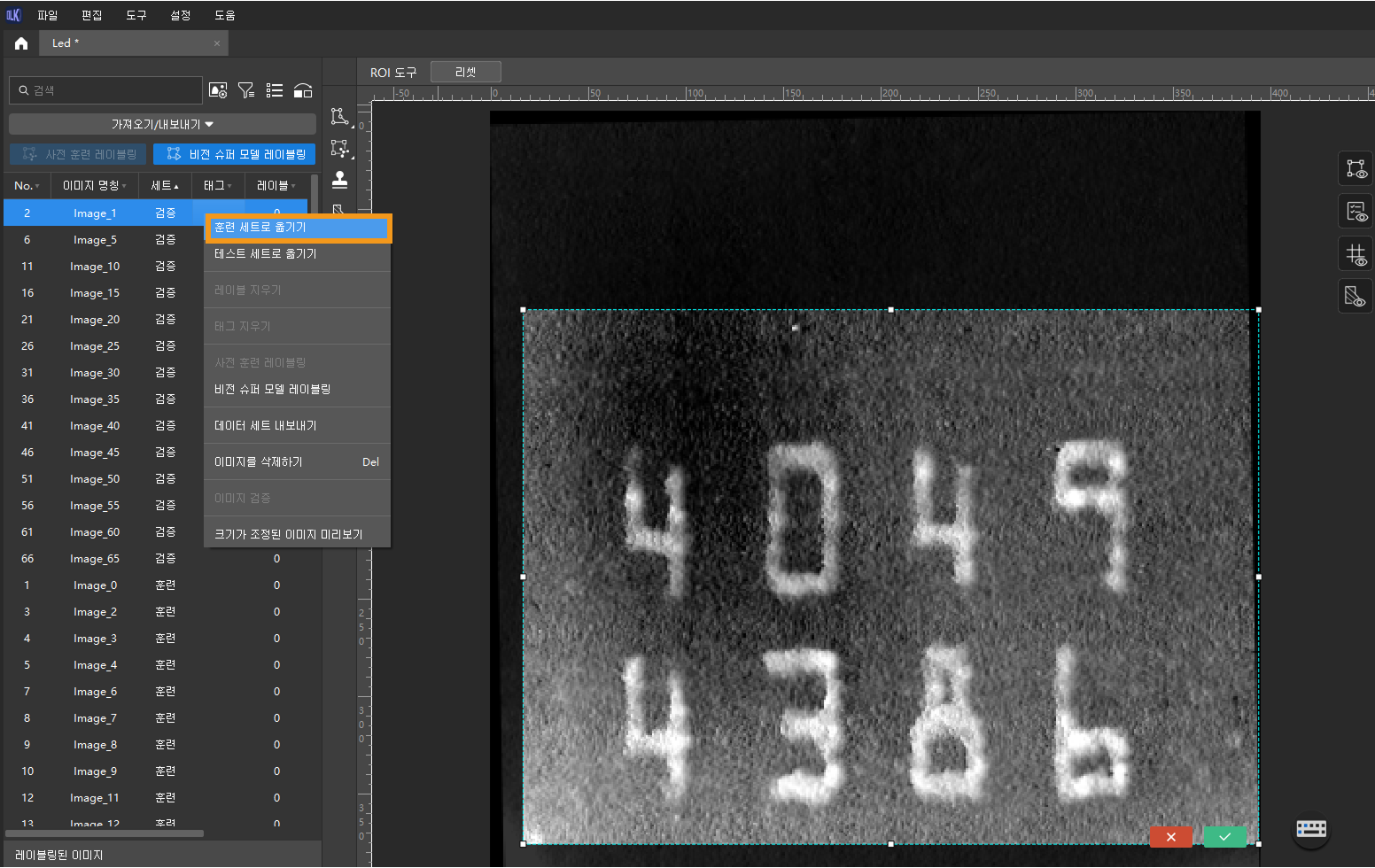
데이터 레이블링
레이블링 툴 바에서 합당한 도구를 선택해 이미지를 레이블링합니다. 레이블링 시, 바운딩 박스는 최대한 텍스트의 경계에 맞춰 설정해야 하며, 텍스트 일부가 누락되거나 바운딩 박스가 너무 커지는 문제를 피해야 합니다.
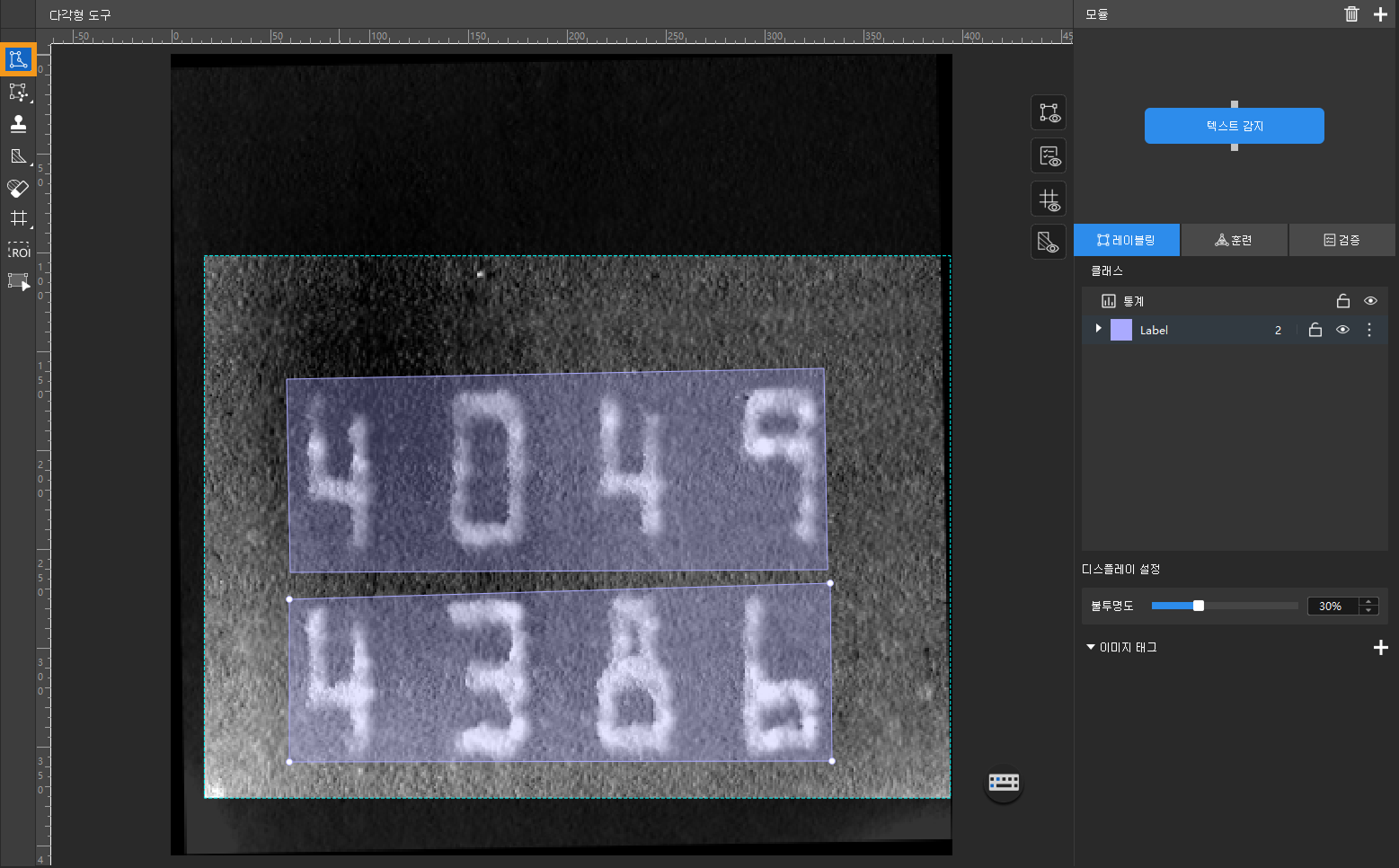
|
모델 훈련
-
모델 훈련 : 기본 파라미터 설정을 사용하며, 훈련 버튼을 클릭하면 모델 훈련이 시작됩니다.
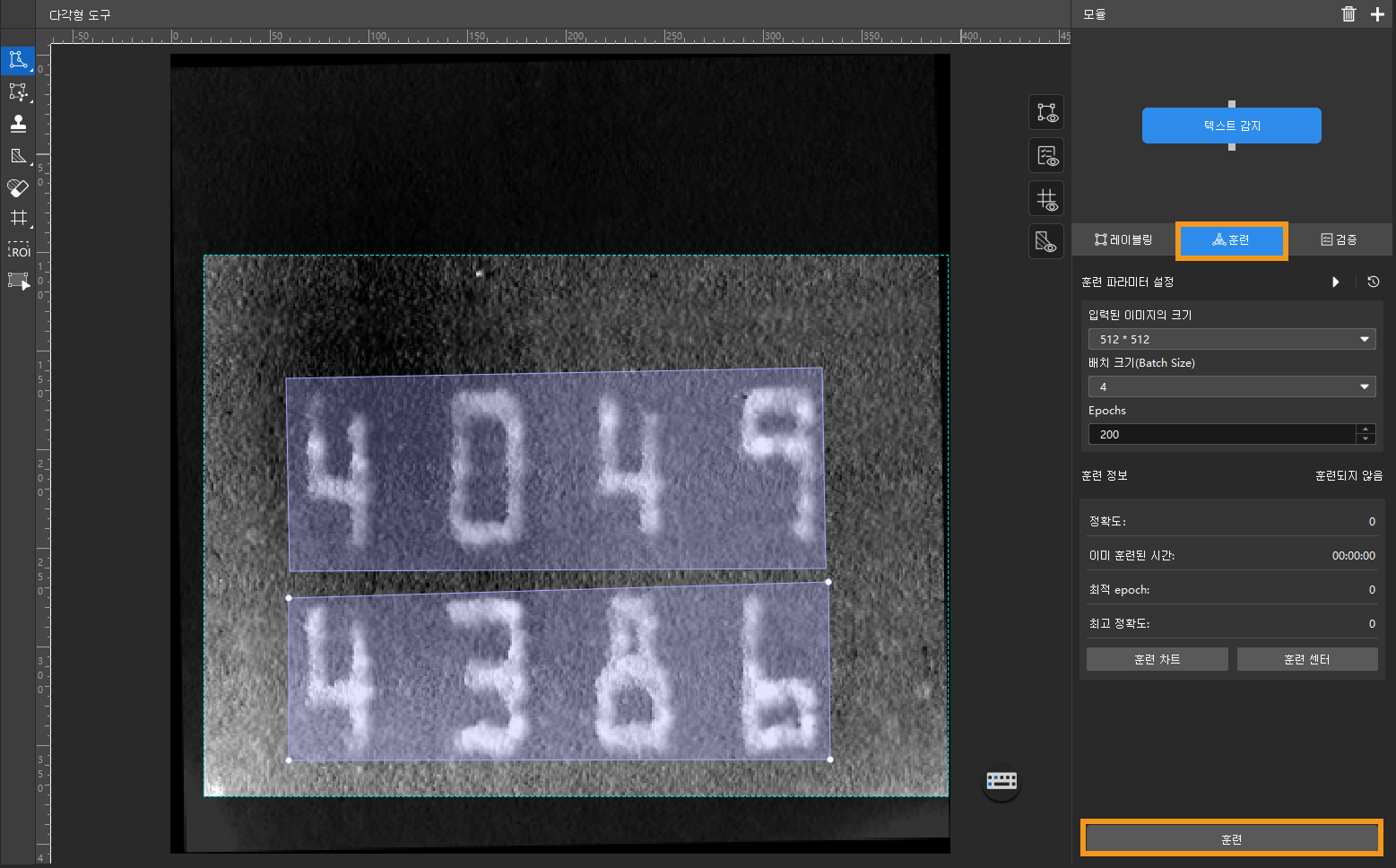
-
훈련 정보를 통해 훈련 상태 확인 : 훈련 탭 아래의 훈련 정보 패널에서 실시간으로 모델 훈련 정보를 확인할 수 있습니다.
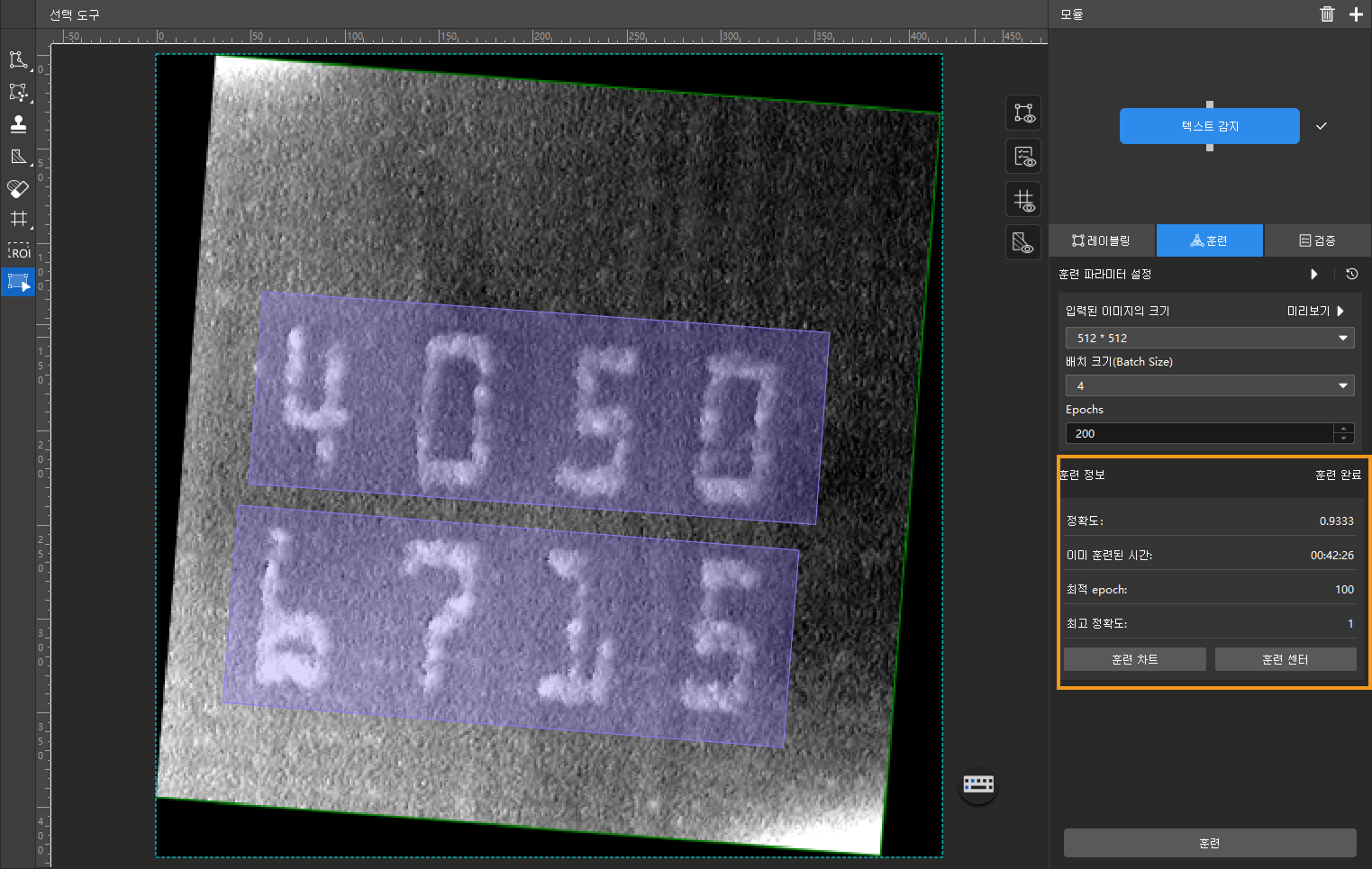
-
'훈련 차트’를 통해 훈련 상태 확인 : 훈련 탭에서 '훈련 차트' 버튼을 클릭하면서, 모델 훈련 과정 중 정확도 곡선과 손실 곡선의 변화를 실시간으로 확인할 수 있습니다. 정확도 곡선이 전반적으로 상승하고, 손실 곡선이 전반적으로 하락하는 추세를 보이면 현재 훈련이 정상적으로 진행되고 있음을 의미합니다.
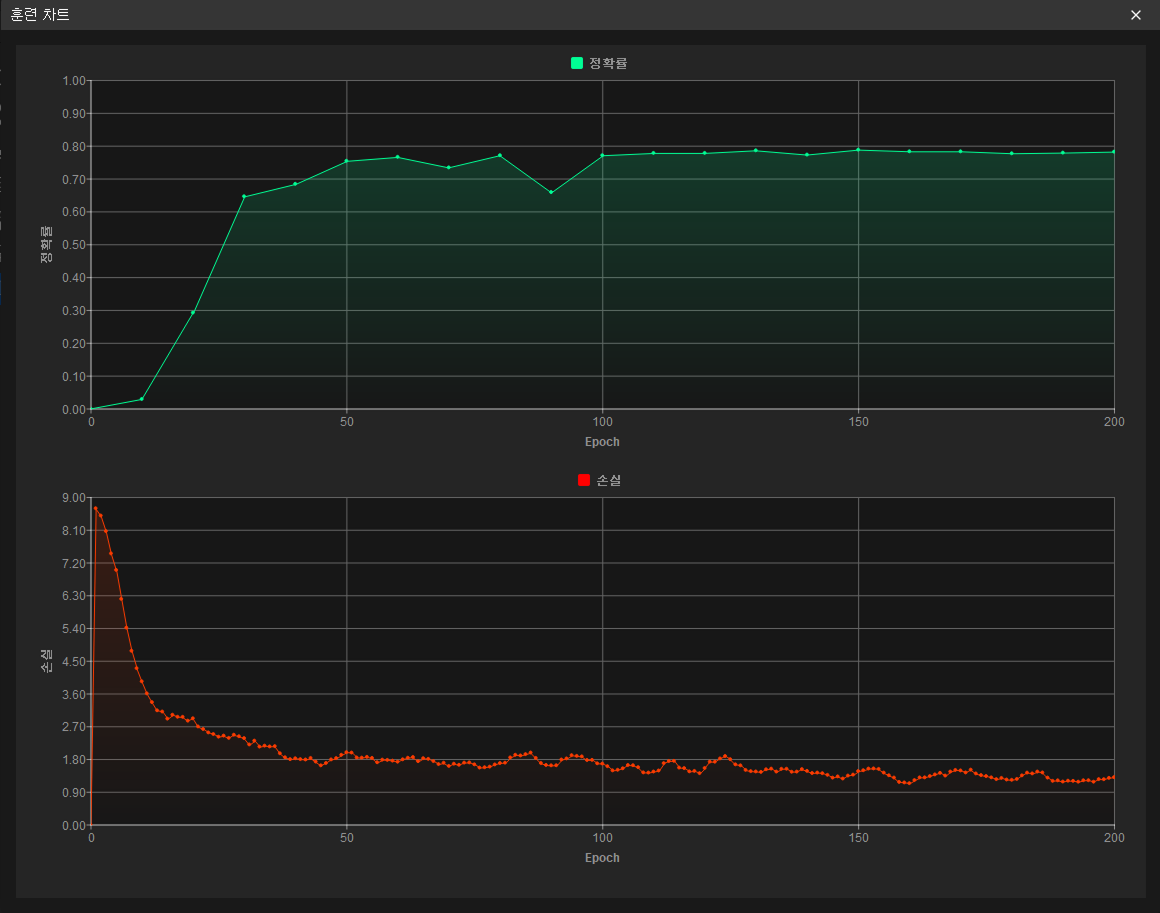
-
실제 상황에 따라 훈련 조기 종료 (선택 사항) : 모델 정확도가 요구 수준에 도달한 경우, 시간을 절약하기 위해 훈련을 조기에 종료할 수 있습니다. 사용자는 [훈련 센터] 버튼을 클릭한 후, 작업 목록에서 해당 프로젝트를 선택하고,
 버튼을 클릭하여 훈련을 중단할 수 있습니다. 또한, 사용자는 훈련이 완료될 때까지 기다린 후, 최고 정확도 및 기타 훈련 파라미터를 확인하여 모델 성능을 사전에 평가할 수도 있습니다.
버튼을 클릭하여 훈련을 중단할 수 있습니다. 또한, 사용자는 훈련이 완료될 때까지 기다린 후, 최고 정확도 및 기타 훈련 파라미터를 확인하여 모델 성능을 사전에 평가할 수도 있습니다.여러 라운드 진행 후에도 정확도 곡선이 상승 추세를 보이지 않는 경우, 현재 모델 훈련에 문제가 있을 수 있습니다. 이 경우, 모델 훈련을 종료한 후 파라미터 설정이 적절한지, 훈련 세트에 누락되었거나 잘못된 레이블이 포함되어 있는지 확인하고 수정한 뒤 훈련을 다시 시작하시기 바랍니다.
모델 검증
-
모델 검증 : 훈련이 완료되면 검증 버튼을 클릭하여 모델을 검증하고 결과를 확인합니다.
-
모델 검증 결과 확인 : 검증이 완료되면, 검증 탭의 검증 통계에서 검증 결과를 확인할 수 있습니다.
-
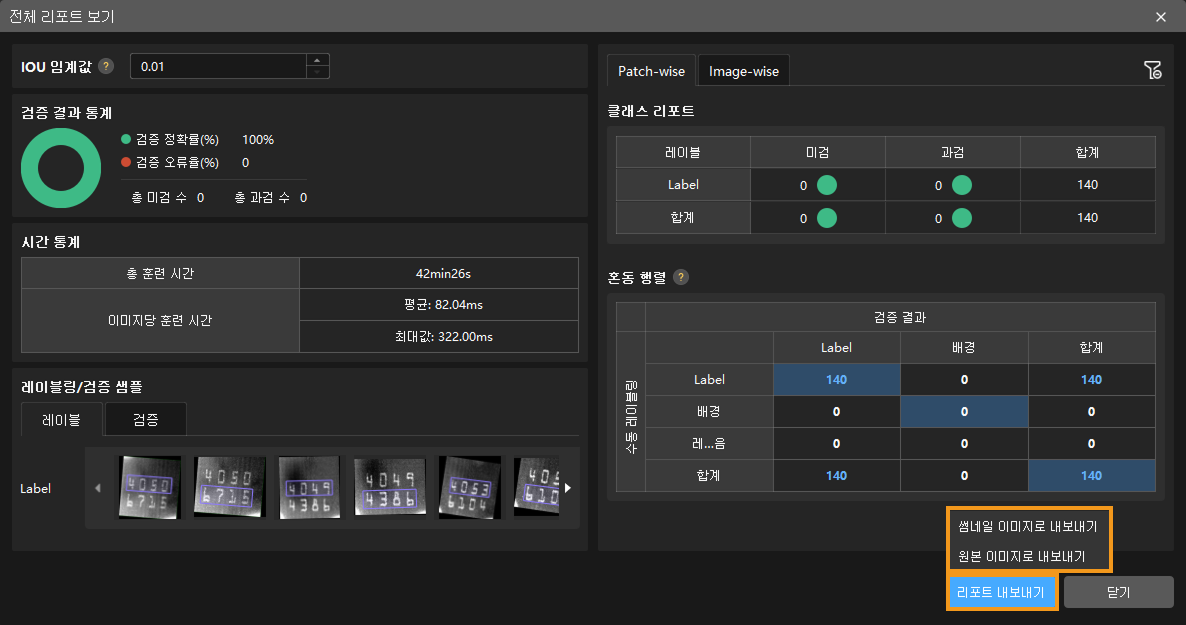
전체 리포트 보기 버튼을 클릭하면 보다 상세한 검증 통계 결과를 확인할 수 있습니다.
-
리포트의 혼동 행렬(Statistical matrix)은 모델의 추론 결과와 실제 레이블 간의 관계를 시각화한 것으로, 각 클래스에 대해 모델이 얼마나 정확하게 예측했는지를 평가하는 데 사용됩니다. 이 혼동 행렬에서 세로축은 실제 레이블을, 가로축은 예측 결과를 나타냅니다.
-
파란색 셀은 예측과 실제가 일치한 경우를, 다른 셀은 불일치한 경우를 나타내며, 모델의 성능과 개선 방향에 대한 인사이트를 제공합니다.
-
또한, 행렬 내 수치 결과 셀을 클릭하면 메인 화면의 이미지 목록이 해당 값에 해당하는 이미지로 자동 필터링되어, 관련된 데이터를 빠르게 확인할 수 있습니다.
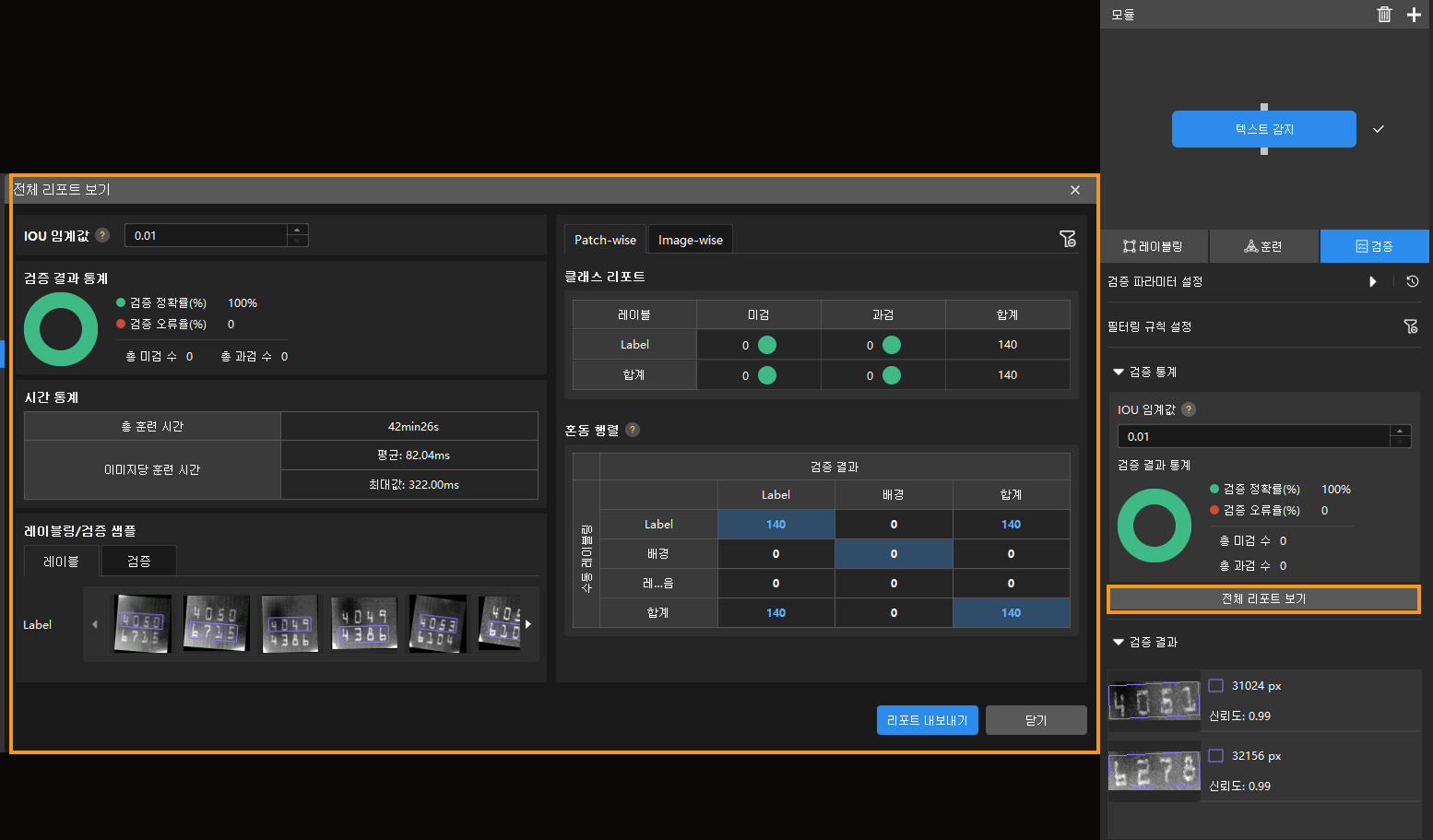
검증 결과에 미검 또는 과검이 있는 경우, 이는 모델 훈련 효과가 충분하지 않음을 의미합니다. 이 경우, 레이블을 점검하고 훈련 파라미터를 조정한 뒤 모델을 다시 훈련해야 합니다. 전체 리포트 보기 창의 오른쪽 하단에 위치한 리포트 내보내기 버튼을 클릭하면, 썸네일 이미지 또는 원본 이미지 형태로 리포트를 내보낼 수 있습니다.
테스트 세트의 모든 미검·과검 이미지를 전부 다시 레이블링하여 훈련 세트로 포함시킬 필요는 없습니다. 일부 이미지만 추가 레이블링해 훈련 세트에 포함한 후, 모델을 재훈련 및 검증하세요. 나머지 이미지는 참고용으로 사용하여 검증 결과를 관찰함으로써 모델 반복 효과를 점검할 수 있습니다. -
-
훈련 재시작 : 새로 레이블링한 이미지를 훈련 세트에 추가한 후, 훈련 버튼을 클릭하여 훈련을 다시 시작합니다.
-
모델 검증 결과 재확인 : 훈련 완료 후, 검증 버튼을 다시 클릭하여 모델을 검증하고, 각 데이터 세트에서의 검증 결과를 다시 확인합니다.
-
모델 파인튜닝(선택 사항) : 개발자 모드를 활성화한 후, 훈련 파라미터 설정에서 모델 파인튜닝 기능을 사용할 수 있습니다. 자세한 내용은 모델 반복 섹션을 참조하세요.
-
모델 지속 최적화 : 모델이 실제 사용 요구 사항을 충족할 때까지, 위의 단계를 반복하여 모델 성능을 지속적으로 최적화합니다.
검증 결과를 조정해야 하는 경우 다음 단계를 따르세요. 검증 탭에서 필터링 규칙 설정을 클릭합니다. 열린 필터링 규칙 설정 창에서 수정 항목을 추가하여 모델의 검증 결과를 조정합니다.
모델 내보내기
검증 탭에서 내보내기를 클릭합니다. 내보내기 창에서 저장 경로와 내보내기 파라미터를 선택합니다. 이미지에 여러 줄의 텍스트가 포함된 경우, 내보내기 파라미터의 결과 정렬 순서 옵션을 사용하여 모델 내보내기 시 텍스트의 출력 순서를 지정할 수 있습니다.
모델은 설정된 정렬 순서에 따라 결과를 다음 모듈로 전달합니다. 내보내기 버튼을 클릭하여 모델을 내보냅니다.

내보낸 모델은 Mech-DLK SDK에서 사용할 수 있습니다. 자세한 내용은 여기를 클릭하여 확인하세요.