高精度なモデルを得るため
本節では、最もモデルの品質に影響を与えるいくつかの要因および高品質なモデルをトレーニングする方法について紹介していきます。
画像の品質を確保する
画像の 露出過度、露出不足、ぼやけ、遮蔽 を回避します。これらが発生したら、ディープラーニングモデルが依存する画像の特徴が失われ、モデル学習の効果に影響を与える可能性があります。
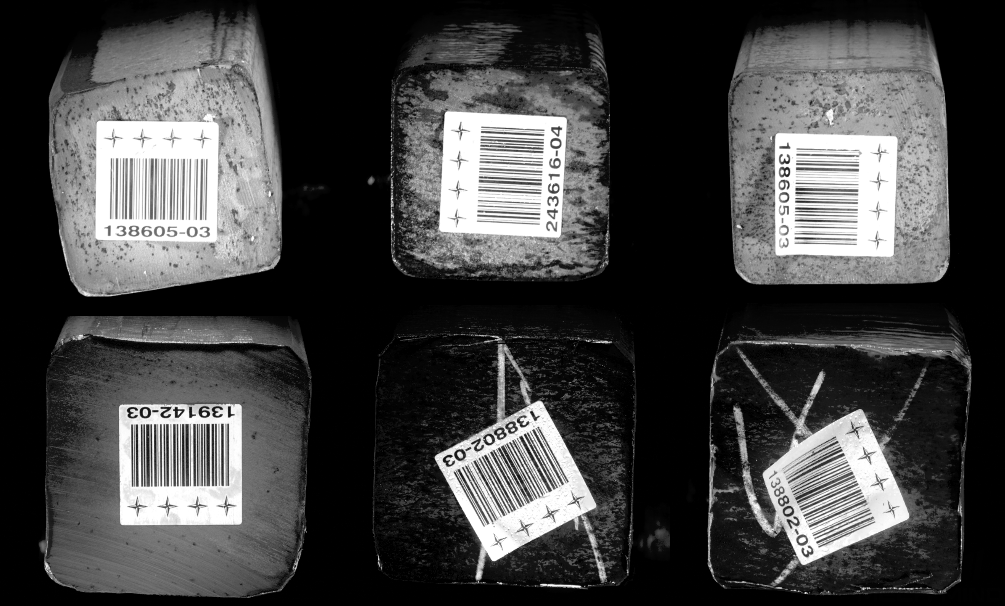
| 画像品質低下:テキスト領域に遮蔽があるため検出の邪魔になり、そのあとのテキスト認識段階で正確に認識できない恐れがあります。 | |
|---|---|
|
|
改善案:テキスト領域に遮蔽がないようにします。 |
|
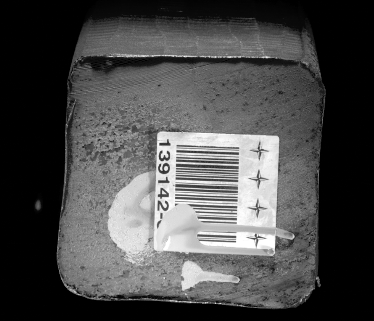

| 画像品質低下:露出過度 | 画像品質低下:露出不足 |
|---|---|
|
|
改善案:遮光・補光を行います。 |
|