テキスト検出モジュールの使用例
LED ディスプレイのデータ(ダウンロード先)を例に、テキスト検出モジュールの使用方法を説明します。テキスト認識モジュールと合わせて使用することで画像のテキスト(文字、数字、記号)を検出してエクスポートします。
| また、お手元のデータも使用できます。ラベル付けの段階に多少異なりますが、全体の操作はほぼ同じです。 |
事前準備
-
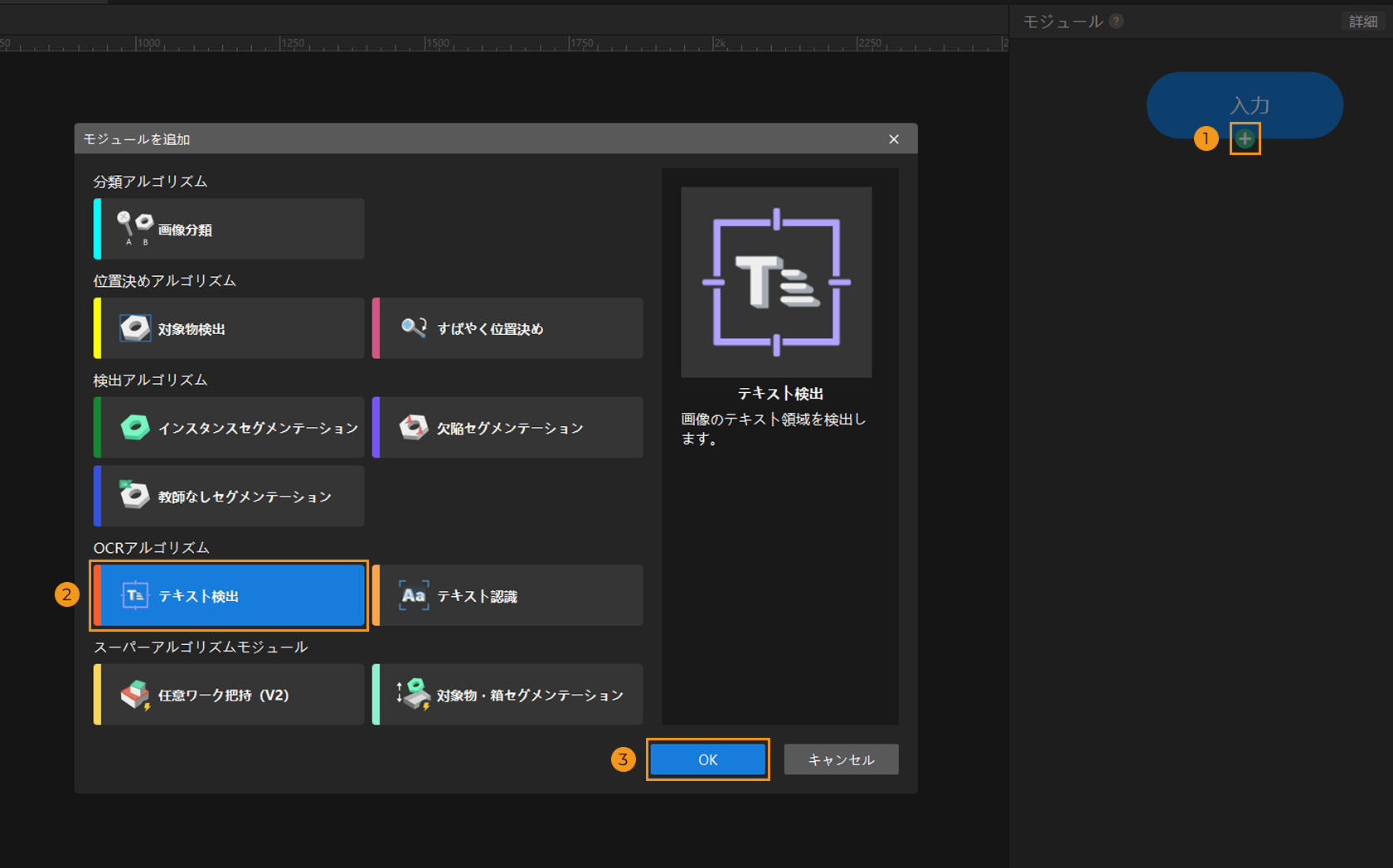
プロジェクトを新規作成してテキスト検出モジュールを追加:Mech-DLK を起動し、ホーム画面のプロジェクトを新規作成をクリックします。保存パスを選択し、プロジェクト名を入力して新しいプロジェクトを作成します。メイン画面の右上にあるモジュールバーで、入力モジュール下の + ボタンをクリックし、モジュール追加ウィンドウでテキスト検出モジュールを選択します。
-
画像をインポート:取得した画像データをインポートするか、前述のデータ圧縮ファイルを解凍して使用します。以下の方法で画像をインポートしてください。
-
方法 1
画像またはフォルダを画像リストにドラッグします。ドラッグによるデータセットのインポートには対応していません。
-
方法 2
画像リストの上のインポート/エクスポートボタンをクリックします。データの種類に応じてインポートオプションを選択します。
-
前のモジュールからインポート:前のモジュールの画像をインポートします。
-
画像をインポート:一枚または複数枚の画像をインポートします。
-
フォルダをインポート:フォルダにある全ての画像をインポートします(サブフォルダー内の画像を除く)。
-
データセットをインポート:Mech-DLK からエクスポートしたDLKDB 形式(.dlkd)のデータセットをインポートします。
-
-
-
ROI 設定:ROI ツールのアイコン
 をクリックして、画像のテキストを納める範囲を ROI としてドラッグで指定します。その後、ROI 枠の右下にある確定アイコン
をクリックして、画像のテキストを納める範囲を ROI としてドラッグで指定します。その後、ROI 枠の右下にある確定アイコン  をクリックして適用します。これは不要な背景による干渉を削減するためです。
をクリックして適用します。これは不要な背景による干渉を削減するためです。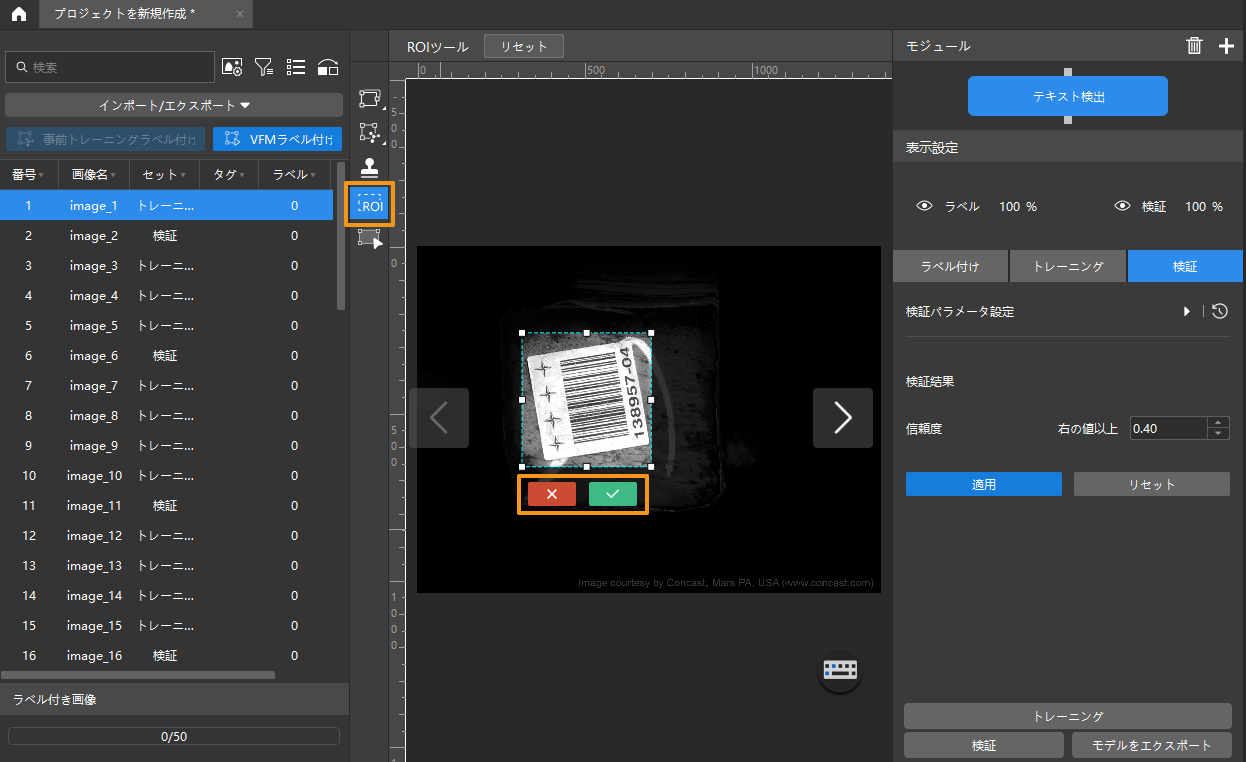
-
トレーニングセットと検証セットの振り分け:ソフトウェアはデフォルトでデータセットの 80% をトレーニングセットに、20% を検証セットに分けます。トレーニングセット/検証セット分割アイコン
 をクリックしてスライダーをドラッグすることで比率を調整できます。トレーニングセットと検証セットにはすべてのカテゴリーのテキスト画像が含まれることを確認してください。トレーニングセットにおいて、向きが異なるテキストが含まれる画像の割合を均等にしてください。デフォルトのデータ分配が上記の条件を満たさない場合、画像名を右クリックし、トレーニングセットに移動または検証セットに移動を選択して画像の所属を変更することができます。
をクリックしてスライダーをドラッグすることで比率を調整できます。トレーニングセットと検証セットにはすべてのカテゴリーのテキスト画像が含まれることを確認してください。トレーニングセットにおいて、向きが異なるテキストが含まれる画像の割合を均等にしてください。デフォルトのデータ分配が上記の条件を満たさない場合、画像名を右クリックし、トレーニングセットに移動または検証セットに移動を選択して画像の所属を変更することができます。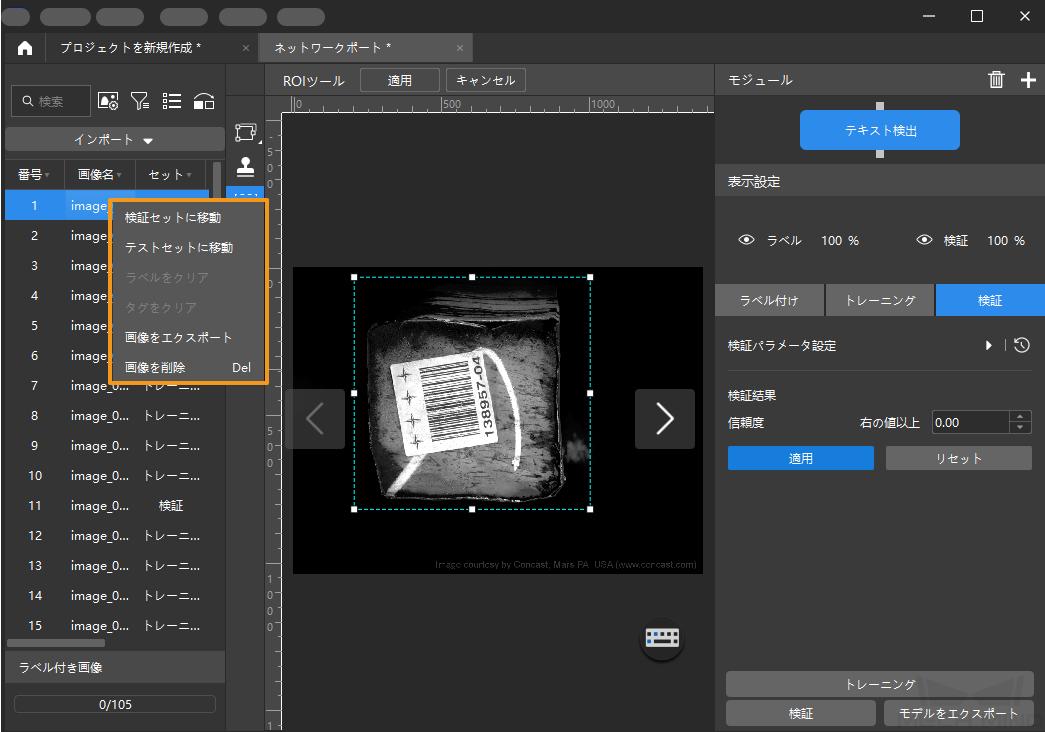
データのラベル付け
画像の左側のツールバーから使用するツールを選択してラベルを付けます。ラベル付けを実行するとき、目標領域の端に近づけ、不要な背景がなくて対象領域が完全に収まるようにしてください。
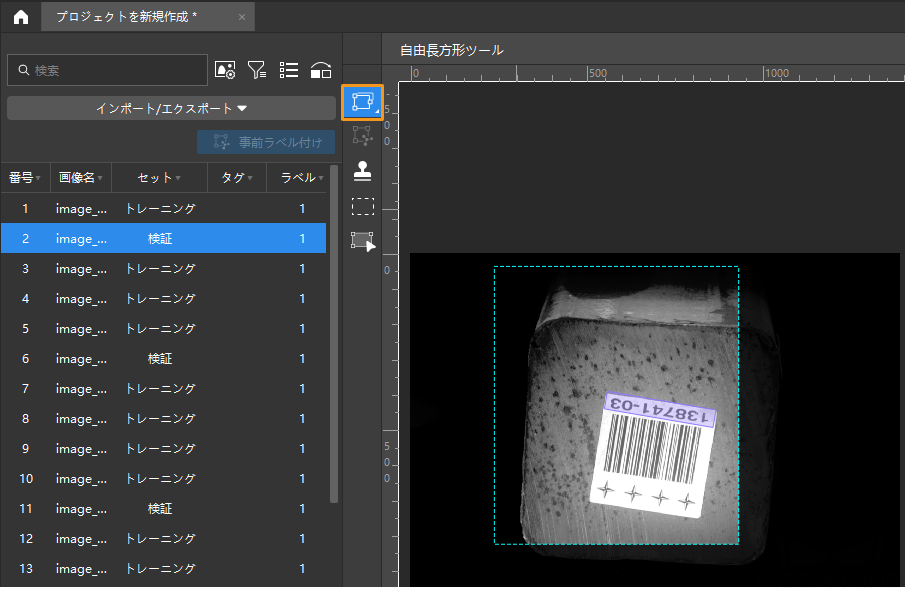
|
モデルのトレーニング
-
モデルトレーニング:デフォルトのパラメータを使って、トレーニングをクリックしてモデルのトレーニングを開始します。
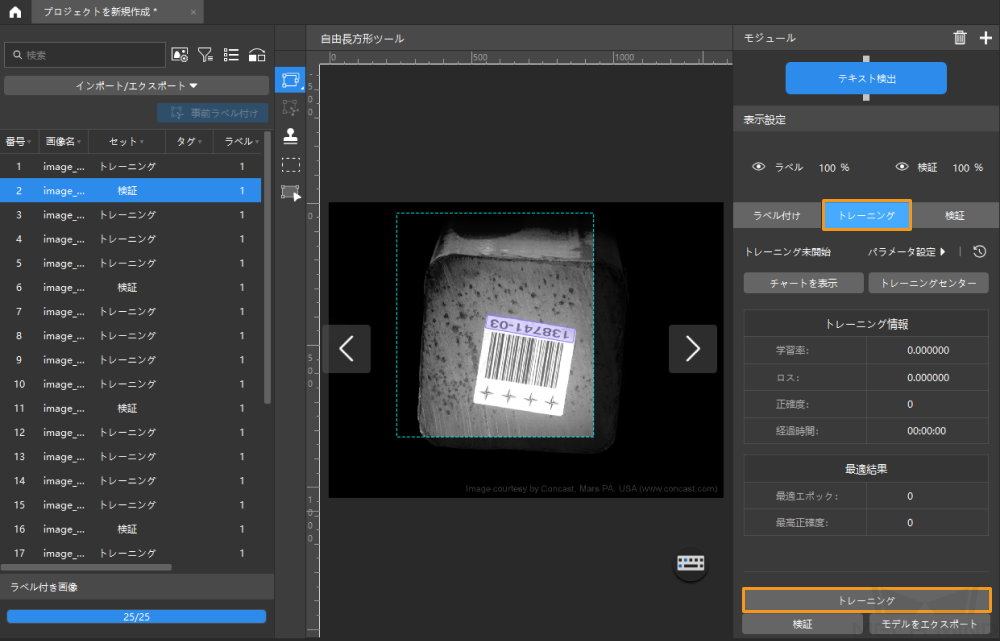
-
トレーニング状況確認:トレーニングパネルからモデルのトレーニング状況をリアルタイムで確認できます。
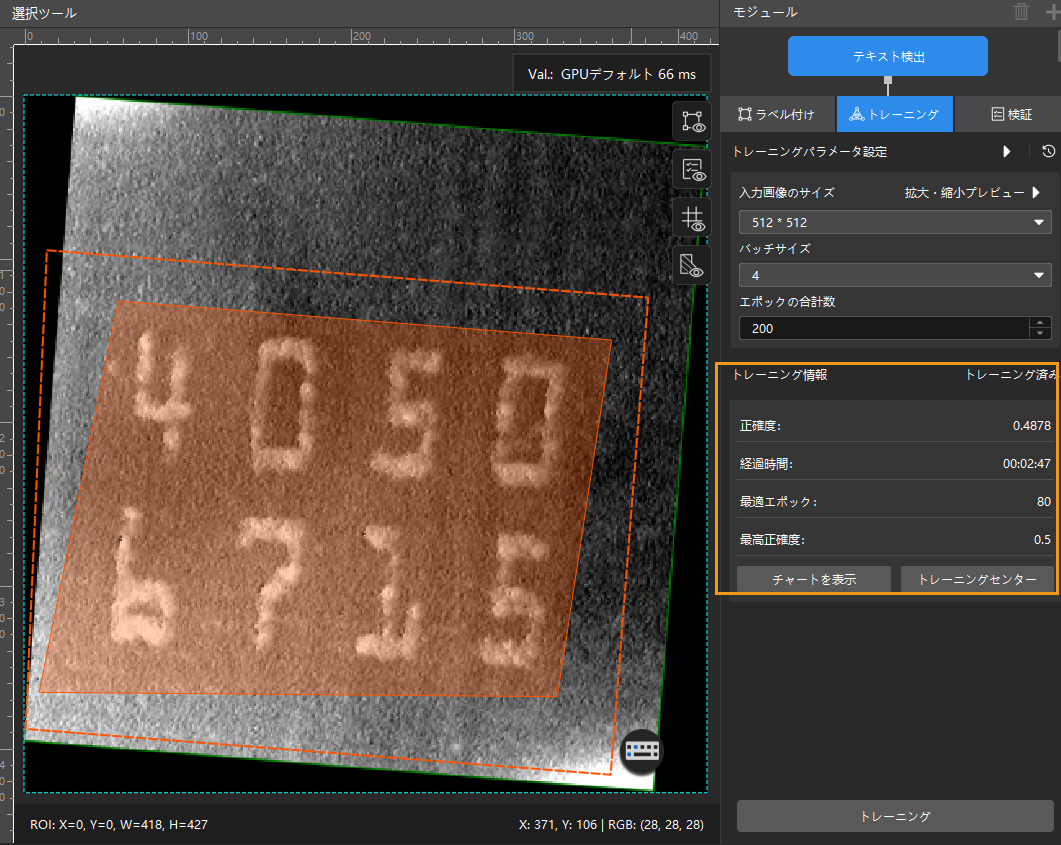
-
「トレーニングチャート」から状況確認:トレーニングタブのチャートを表示ボタンをクリックしてトレーニングチャートを表示して、曲線の変化から精度の推移を把握します。正確度曲線が全体的に上昇傾向、損失曲線が全体的に低下傾向になると、トレーニングが正常に進行していることになります。
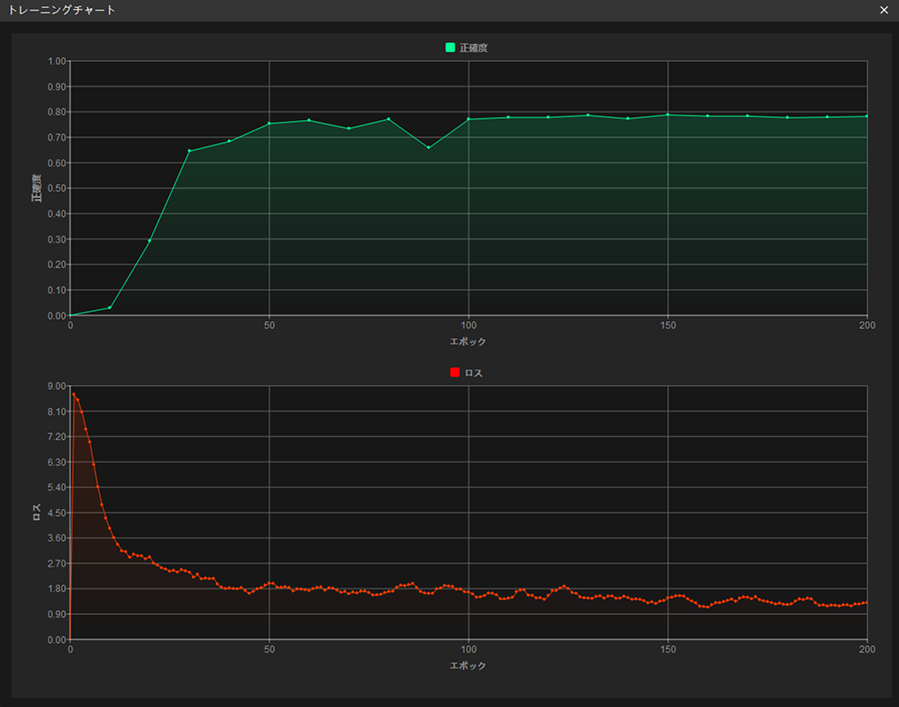
-
実際の状況に応じてトレーニングを中止(オプション):モデルの正確度が要求水準に達した場合、時間節約のため「トレーニングセンター」ボタンをクリックし、タスクリストから対象プロジェクトを選択して
 をクリックすると、トレーニングが中止されます。また、トレーニングの完了まで待ち、正確度の推移を観測して初歩的にモデルの効果を評価することもできます。
をクリックすると、トレーニングが中止されます。また、トレーニングの完了まで待ち、正確度の推移を観測して初歩的にモデルの効果を評価することもできます。エポックを重ねても正確度曲線に上昇傾向が見られない場合は、トレーニングに問題がある可能性があります。トレニンーグを中止し、各パラメータ設定を確認した上で、データセットにおけるラベル抜けや誤りの有無をチェックし、修正後にトレニンーグを再開してください。
モデルの検証
-
モデル検証:モデルトレーニング終了後、検証 をクリックして結果を確認します。
-
トレーニングセットのモデル検証結果を確認:検証終了後、検証タブの検証統計から検証の結果を確認できます。
-
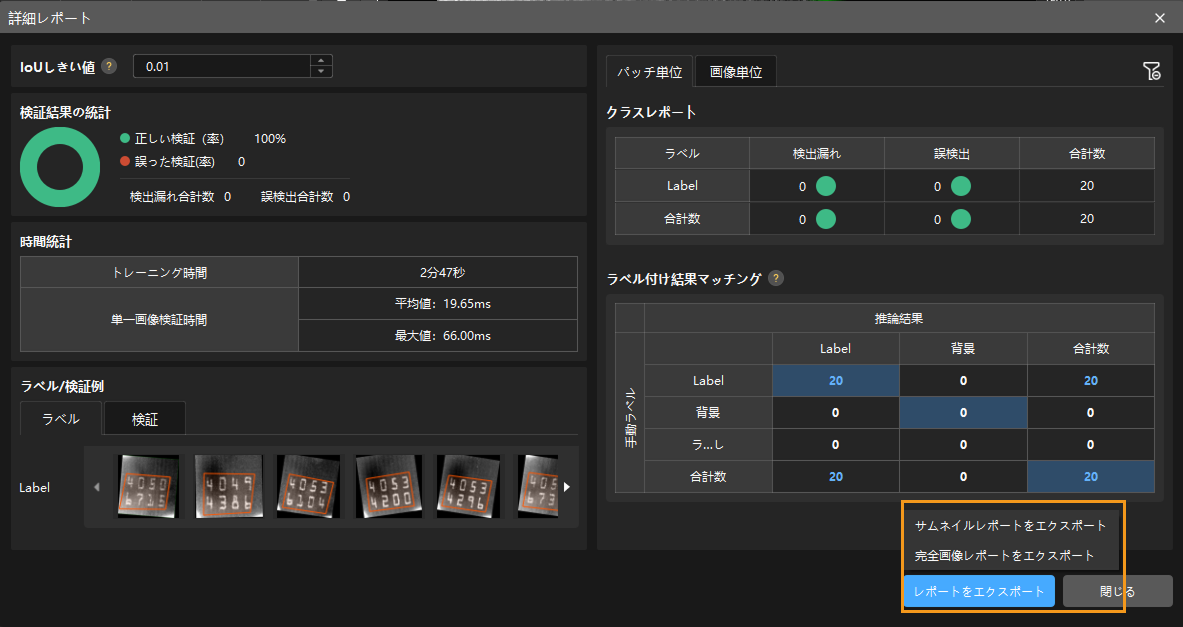
詳細レポートをクリックして詳細レポートウィンドウを開いて詳細な結果データを確認します。
-
レポートのラベル付け結果マッチングには、モデル推論(検証)の結果と手動ラベルとのマッチング関係を示します。表の縦は手動で付けたラベル、横は推論の結果です。
-
青いセルは両方が一致していることを示します。その他のセルは不一致が存在することを示しており、モデル最適化の参考になります。
-
セルのデータをクリックすると、ソフトウェアのメイン画面の画像リストに対応する画像のみが表示されます。
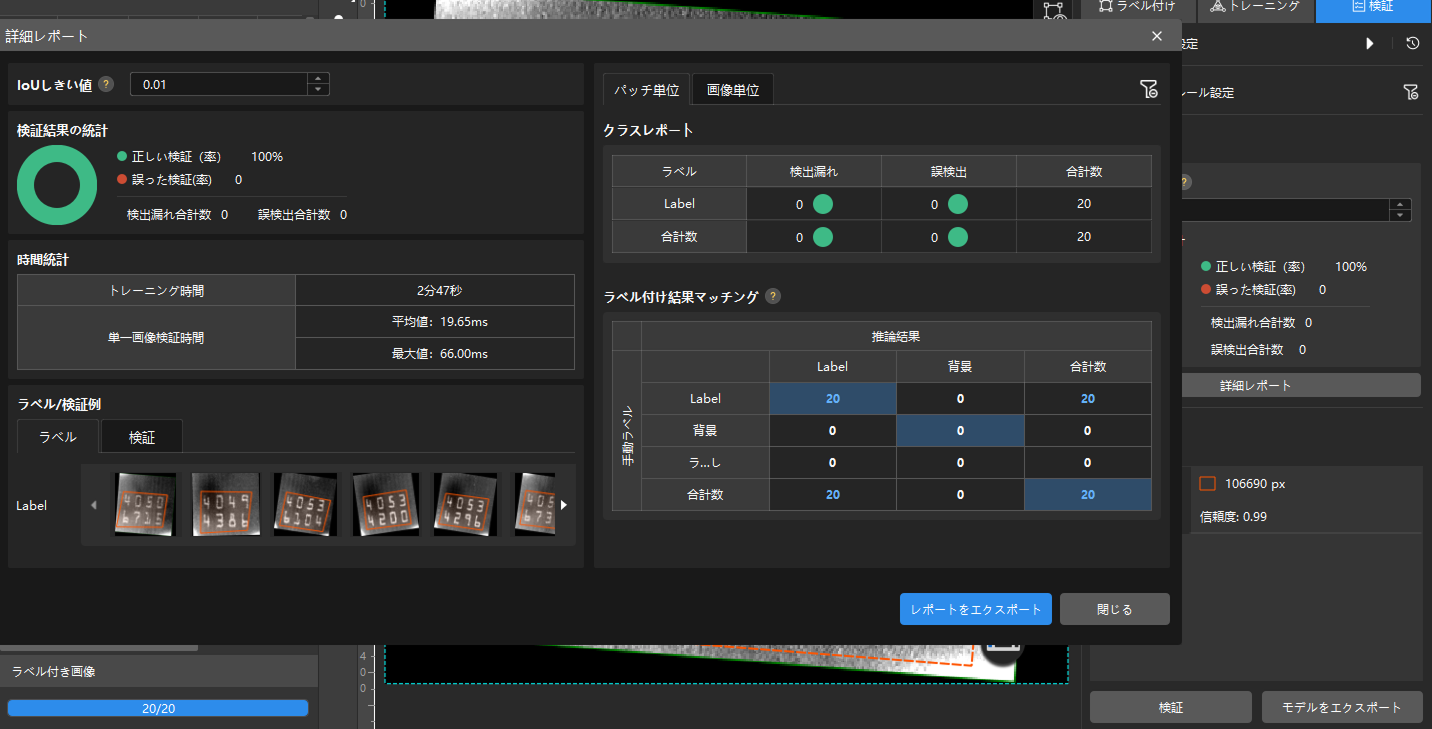
検証結果に見逃しや誤検出がある場合、トレーニング効果を改善する必要があります。ラベル付けをチェックしてトレーニングパラメータを調整してから再トレーニングを行ってください。 詳細レポートウィンドウの右下にあるレポートをエクスポートボタンをクリックし、サムネイルレポートまたは完全画像レポートをエクスポートすることが選択できます。
テストセット内の見逃しや誤検出がある画像を全て手動的にラベル付けしてトレーニングセットに移動する必要はありません。一部の画像を追加でラベル付けしてトレーニングセットに加えてモデルを再トレーニング・検証します。残りの画像は検証の参照として使用されます。 -
-
再トレーニング:新たにラベル付けした画像をトレーニングセットに追加してから、トレーニングボタンをクリックして、再トレーニングを開始します。
-
モデル検証結果の再チェック:再トレニンーグ終了後、再び検証ボタンをクリックしてモデルの検証を行い、各データセットにおけるモデルの検証結果を確認します。
-
モデルの微調整(オプション):開発者モードをオンにしてトレーニングパラメータ設定でモデルを微調整することが可能です。詳細な説明は、モデルの追加学習をご参照ください。
-
モデルの最適化:モデルが使用要件を満たすまで上記の手順を繰り返します。
検証の結果を修正したい場合、以下の手順に従ってください:検証タブでフィルタリングルール設定を実行してフィルタリングルール設定ウィンドウでルールを編集します。
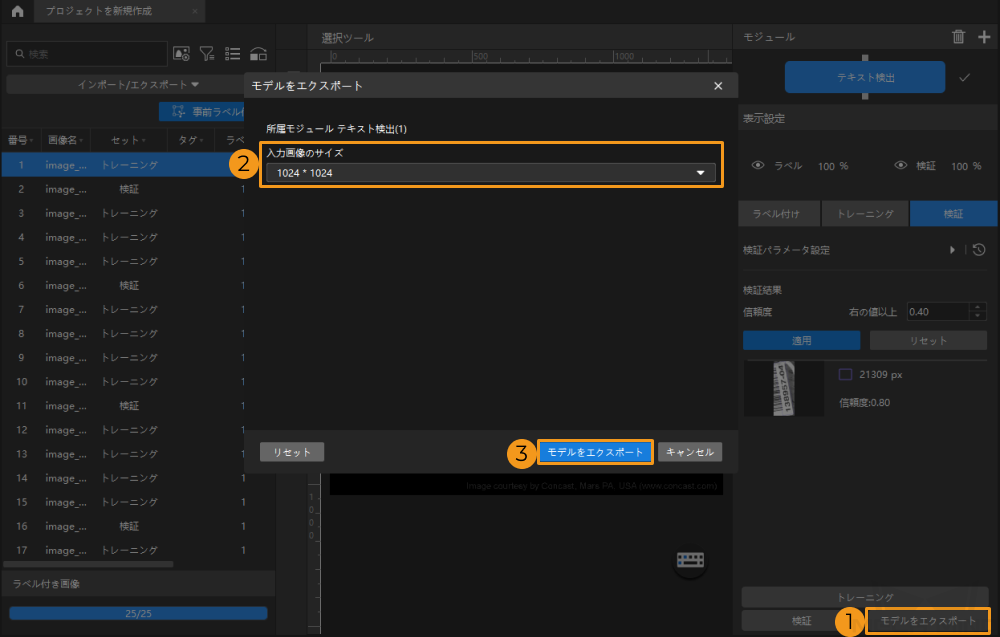
モデルのエクスポート
モデルをエクスポートをクイックします。モデルをエクスポートウィンドウで保存パスとパラメータを設定します。画像に複数行テキストに対しては、エクスポートする時にテキスト組合せ方式を指定することができます。モデルをエクスポートをクリックします。
エクスポートされたモデルは Mech-DLK SDK に使用できます。クリックして詳細な説明を確認します。