インスタンスセグメンテーションモジュールの使用例
本節では、ダウンロード先異形金属板金データ()を提供し、インスタンスセグメンテーションモジュールの使用方法を説明します。データ収集、データ処理、ラベル付け、モデルのトレーニング、モデルの検証、モデルのエクスポートと、6つの手順で実行します。
| また、お手元のデータも使用できます。ラベル付けの段階に多少異なりますが、全体の操作はほぼ同じです。 |
データ収集
データ収集ルールに従って必要な画像を取得してください。現場のニーズに応じて 2D 露出とホワイトバランスを設定して画像品質を改善します。また、モデルの汎用性を確保するために手動でワークの位置と姿勢を変更したりする必要もあります。その後、取得した画像から品質が高くて現場の照明などの条件の変化を反映する画像を選択します。


データ処理
-
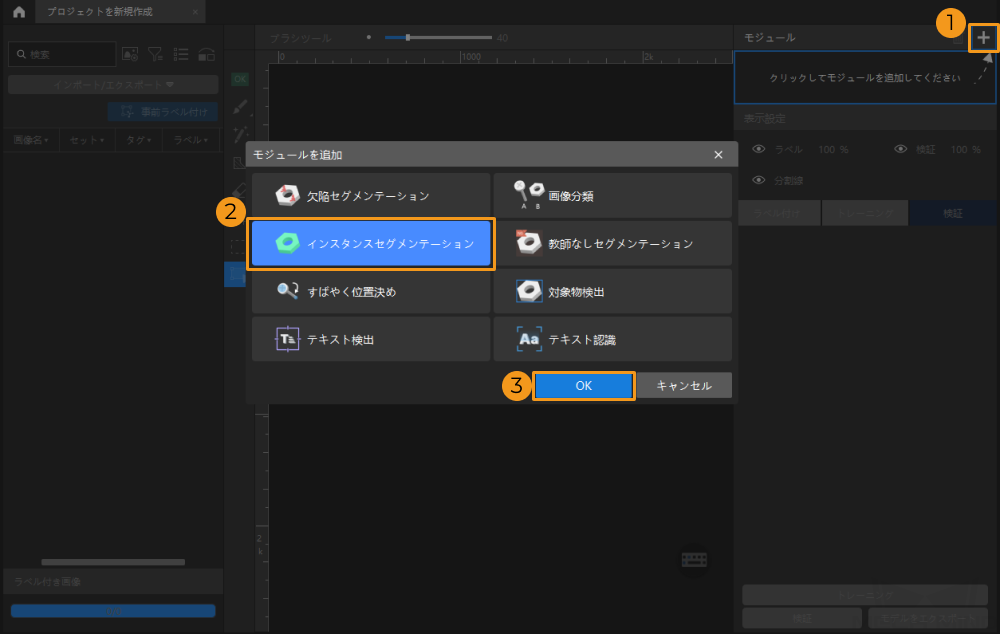
プロジェクトを新規作成してインスタンスセグメンテーションモジュールを追加:Mech-DLK を起動し、ホーム画面のプロジェクトを新規作成をクリックします。保存パスを選択し、プロジェクト名を入力して新しいプロジェクトを作成します。メイン画面の右上にあるモジュールバーで、入力モジュール下の + ボタンをクリックし、モジュール追加ウィンドウでインスタンスセグメンテーションモジュールを選択します。
-
画像をインポート:取得した画像データをインポートするか、前述のデータ圧縮ファイルを解凍して使用します。以下の方法で画像をインポートしてください。
-
方法 1
画像またはフォルダを画像リストにドラッグします。ドラッグによるデータセットのインポートには対応していません。
-
方法 2
画像リストの上のインポート/エクスポートボタンをクリックします。データの種類に応じてインポートオプションを選択します。
-
前のモジュールからインポート:前のモジュールの画像をインポートします。
-
画像をインポート:一枚または複数枚の画像をインポートします。
-
フォルダをインポート:フォルダにある全ての画像をインポートします(サブフォルダー内の画像を除く)。
-
データセットをインポート:Mech-DLK からエクスポートしたDLKDB 形式(.dlkd)と COCO 形式のデータセットをインポートします。
-
-
-
ROI 設定:ROI ツールのアイコン
 をクリックして、画像から部品箱を ROI としてドラッグで指定します。その後、ROI 枠の右下にある確定アイコン
をクリックして、画像から部品箱を ROI としてドラッグで指定します。その後、ROI 枠の右下にある確定アイコン  をクリックして適用します。これは、不要な背景の情報による干渉を減少するためです。
をクリックして適用します。これは、不要な背景の情報による干渉を減少するためです。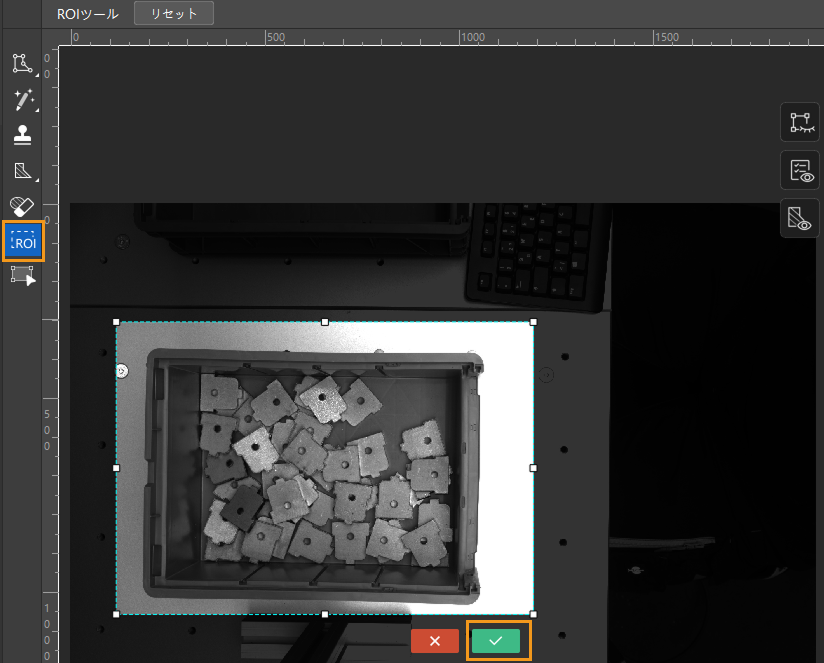
-
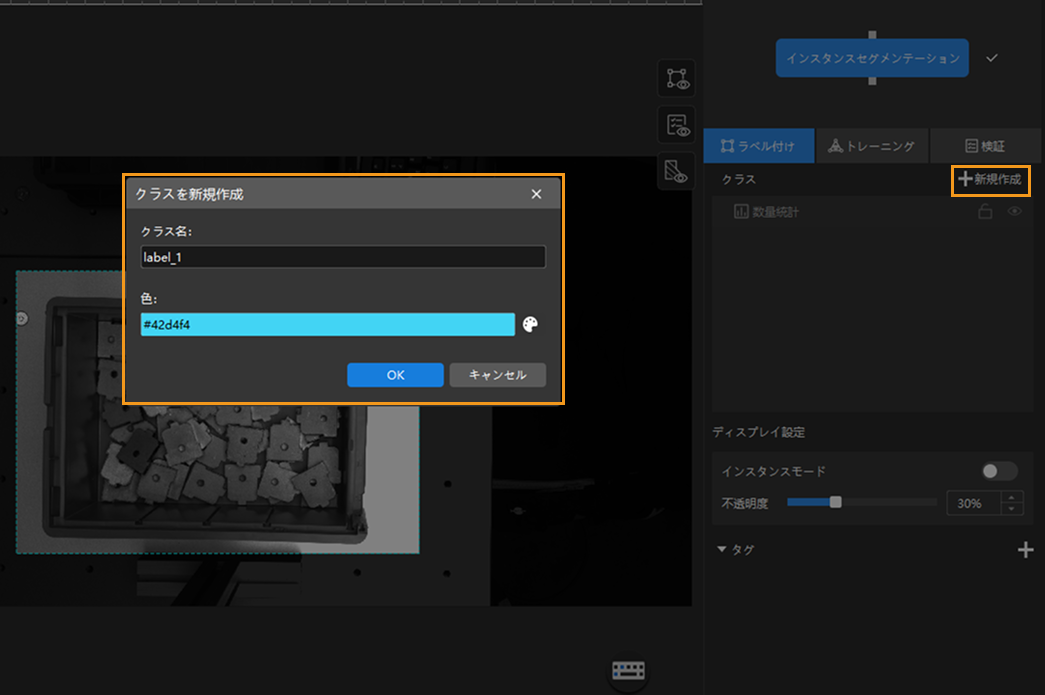
クラスを作成:右側の「ラベル付け」パネルにある + 新規作成をクリックし、対象物の名前や特徴によってクラスを作成します。この事例では認識対象のワークが1種類のみで、表裏の判別も不要なのでクラスを 1つだけ作成すればいいです。複数種類のワークを処理する場合にワークそれぞれの特徴によってクラスを作成して命名します。
クラスを右クリックして右へマージを選択してデータを別のクラスに変更することができます。モデルをトレーニングしてからクラスをマージした場合に、モデルを再度トレーニングしてください。 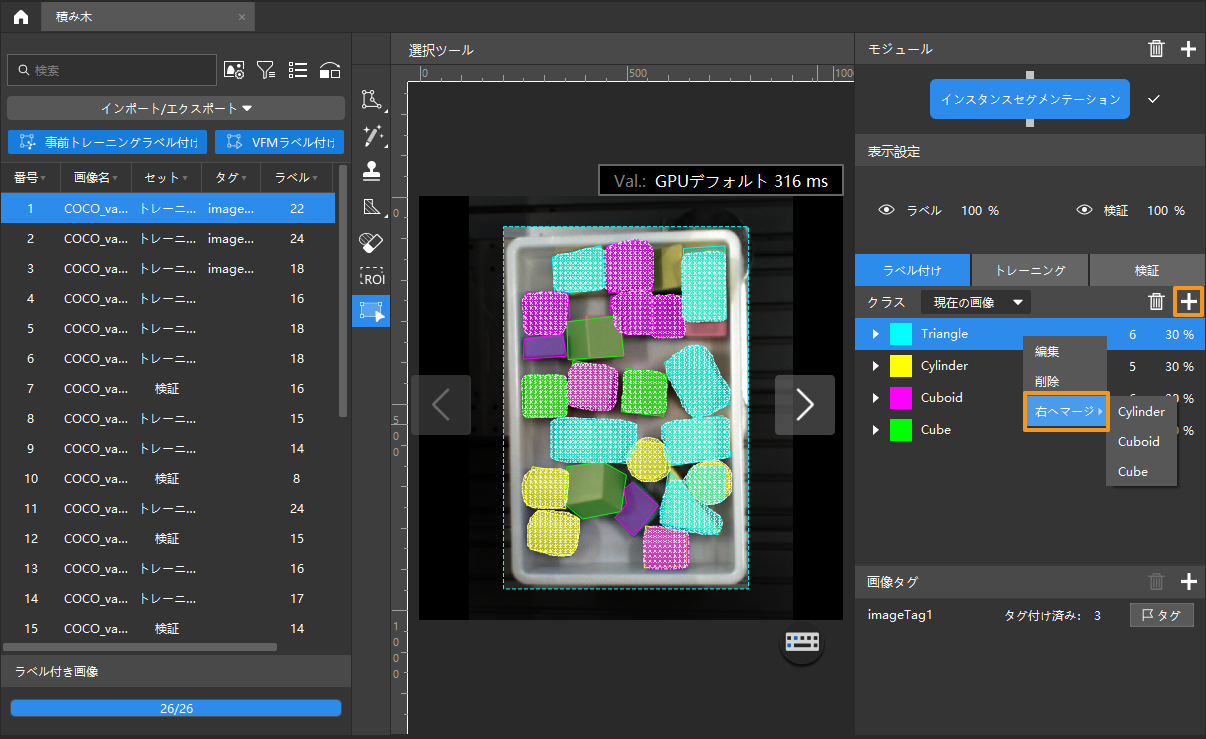
データのラベル付け
データラベル付けルールに従ってください。
-
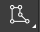
ラベル付けのルールを明確に:ここでは、最上段のワークだけをラベル付けします。把持点とエッジはほとんど見られ、把持点が箱の壁に密着することもありません。
Ctrl を押したままホイールを奥に回せば画像を拡大できます。 -
ラベル付け:マウスの左ボタンを長押し、または画像の左側にあるツールバーのポリゴンツールのアイコン
 を右クリックして使用するラベル付けツールを選択します。
を右クリックして使用するラベル付けツールを選択します。この事例では、ワークの形状が複雑なのでポリゴンを選択します。複数のアンカーポイントを定義することでポリゴンラベルを作成します。画像の枚数が多いですがいちいちラベル付けする必要はありません。10 枚程度の画像をラベル付けしてトレーニングしてみます。また、ワークの位置など、特徴の差が明らかな画像をラベル付けします。
より詳細なラベル付けツールの説明は、ラベル付けツールをお読みください。 -
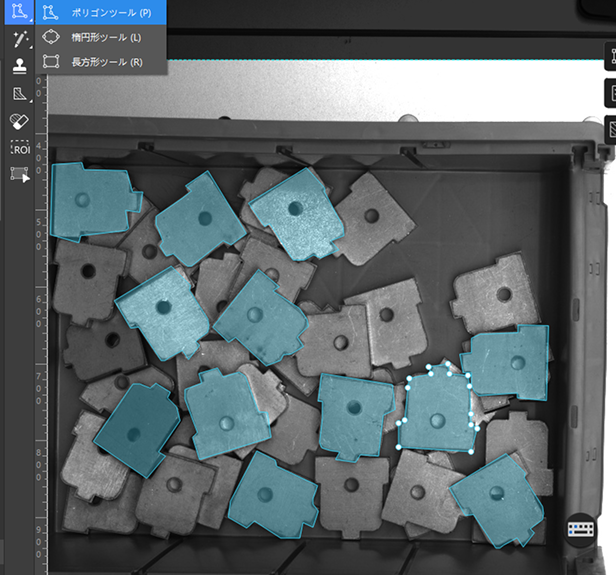
トレーニングセットと検証セットの振り分け:ラベル付け済みの画像をトレーニングセットに移動してトレーニングセットと検証セットを分割します。通常の場合、80%をトレーニングセットに、残りの20%を検証セットに割り当てることを推奨します。トレーニングセットに移動された画像を自動的に振り分け、ユーザーは割合を指定すればいいです。
モデルのトレーニング
-
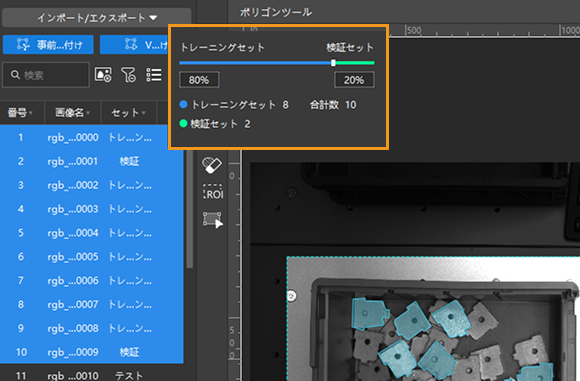
データ拡張パラメータ設定:現場のあらゆる条件を再現するデータが必要です。この事例では、現場の照明の変化を反映する画像を使用します。
-
ここで使用する画像は、現場の照明が明るい時に取得したものなので、暗い時の画像を再現するために輝度を調整します。
-
ワークと背景とは色が近いのでより精確に認識できるようにコントラストも調整します。
-
あらゆる姿勢のワークを認識するために並進、回転、左右反転、上下反転を調整します。
-
また、この事例に使用する画像にはサイズがほぼ同じワークがあるのでスケーリングも調整します。
-
-
トレーニングパラメータ設定:
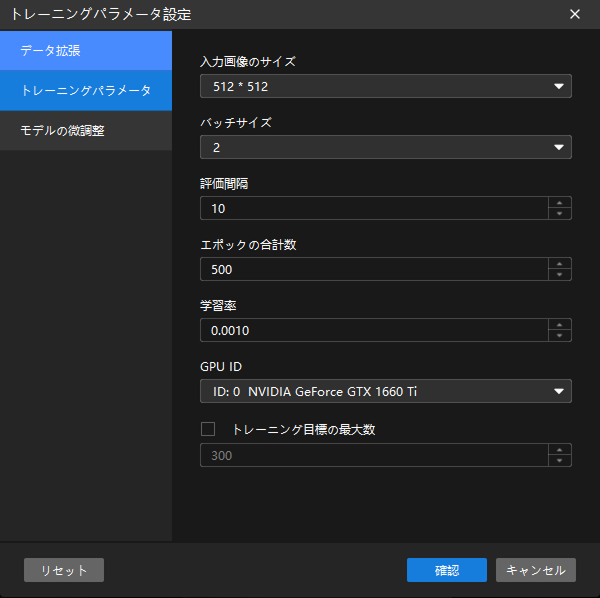
-
モデルタイプとは、トレーニング時に使用するモデルのタイプを指します。インスタンスセグメンテーションモジュールのみ表示されます。
-
統合モデル:ほとんどの一般的なシーンに適しています。
-
密集配置の長い対象物モデル:ワークが密集して配置されているシーンや、細長い形状のワークが含まれるシーンに適しています。
-
-
入力画像のサイズはトレーニング時にモデルに入力する画像のサイズ(ピクセル単位)。値が高いほどモデルの精度は向上しますがトレーニング時間は長くなります。ラベルとワークの特徴が見える限りに画像のサイズを低くすることを推奨します。ここでは初期値のままでいいです。
-
エポック合計数はモデルのトレーニングエポック数です。この事例のワークの形状が複雑なのでこのパラメータ値を高くします。
-
その他のパラメータは初期値のままでいいです。
-
この事例では、モデルの微調整は適用しません。
-
確認 をクリックして設定内容を保存します。
詳細なパラメータ説明は、パラメータの説明をお読みください。
-
入力画像のサイズが小さいほどトレーニングと推論のスピードがアップします。
-
サイズが大きいが画像のほうは、精度のより高いモデルが取得できますがトレーニングと推論の速度は下がります。
-
-
-
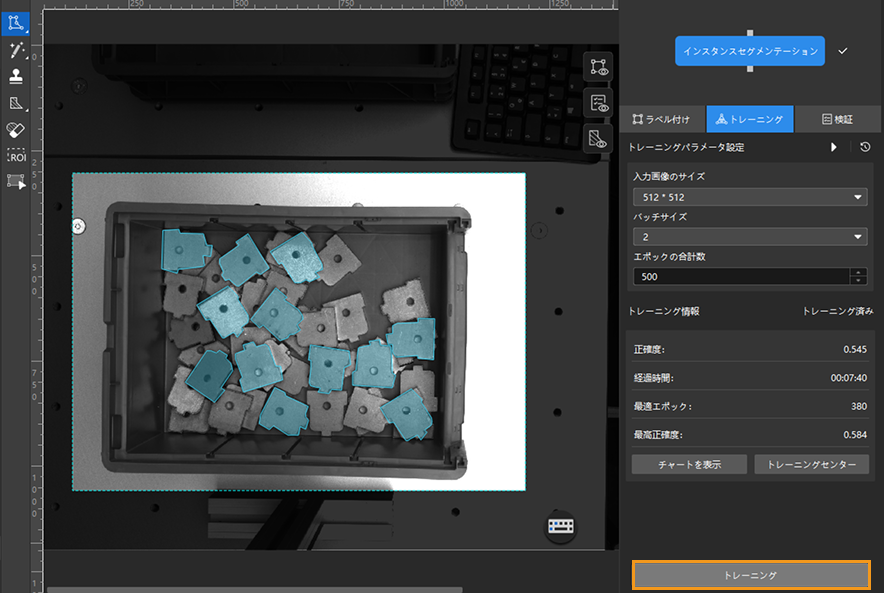
トレーニング実行:トレーニングパネルのトレーニングをクリックしてトレーニングを開始します。
-
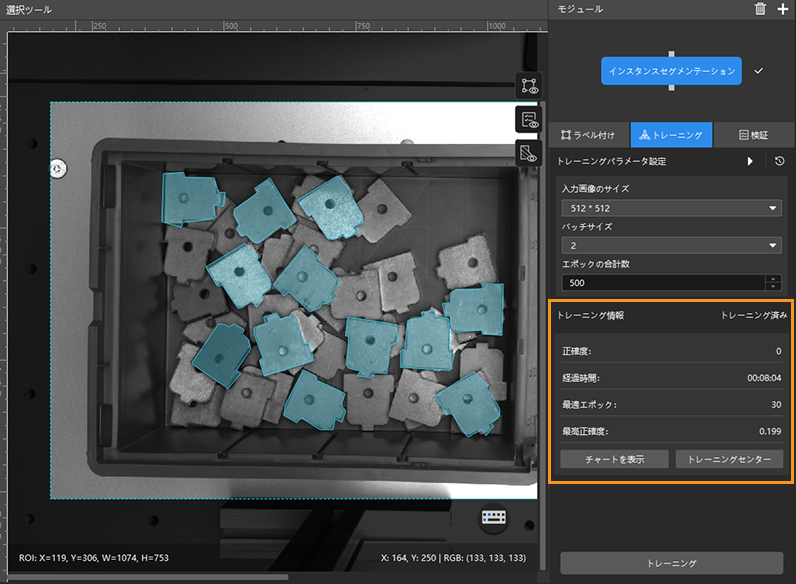
トレーニング状況確認:トレーニングパネルからモデルのトレーニング状況をリアルタイムで確認できます。
-
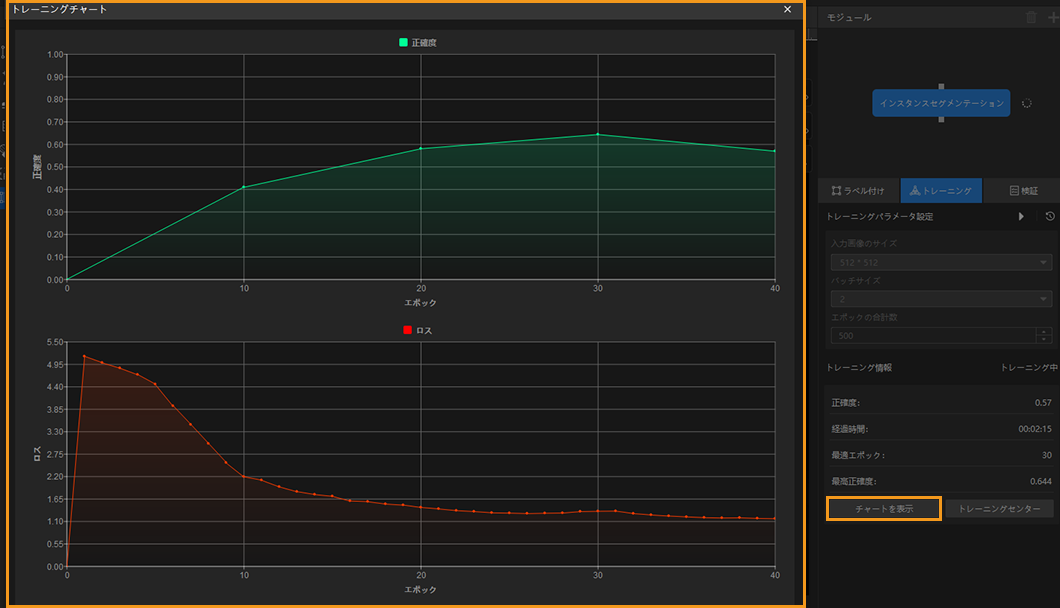
トレーニングチャートから状況確認:トレーニングパネルのチャートを表示ボタンとトレーニングセンターボタンをクリックしてトレーニングチャートを表示して、曲線の変化から精度の推移を把握します。トレーニングの完了まで待ち、最高正確度を確認し、テストデータ検証結果エリアを観測して初歩的にモデルの効果を評価することもできます。正確度曲線が全体的に上昇傾向、損失曲線が全体的に低下傾向になると、トレーニングが正常に進行していることになります。
モデルの検証
-
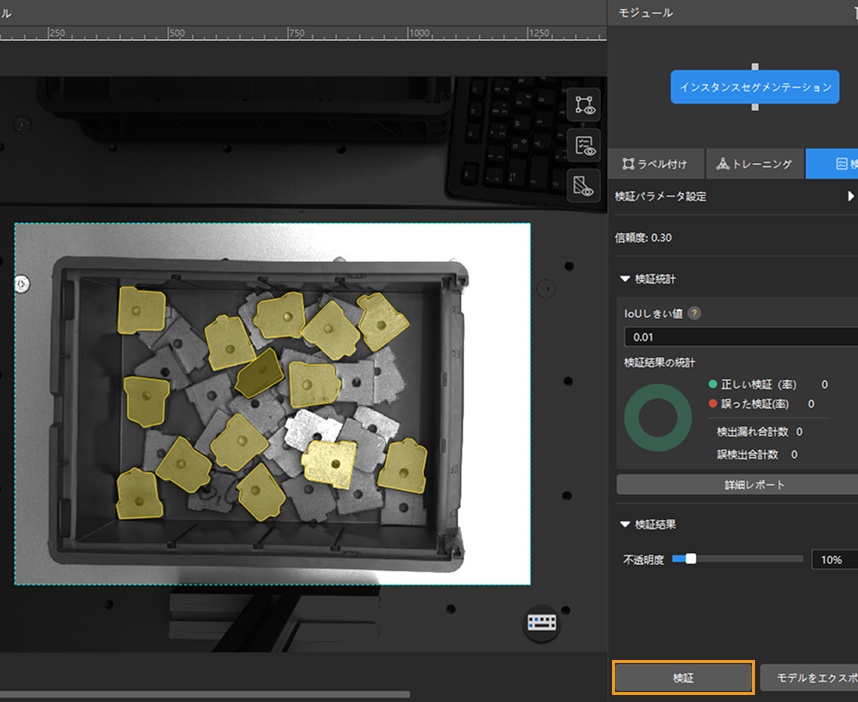
モデル検証:トレーニング終了後、検証パネルに切り替えて検証ボタンをクリックし、モデルの検証を行います。
-
トレーニングセットのモデル検証結果を確認:検証終了後、検証パネルの検証統計から検証の結果を確認できます。
-
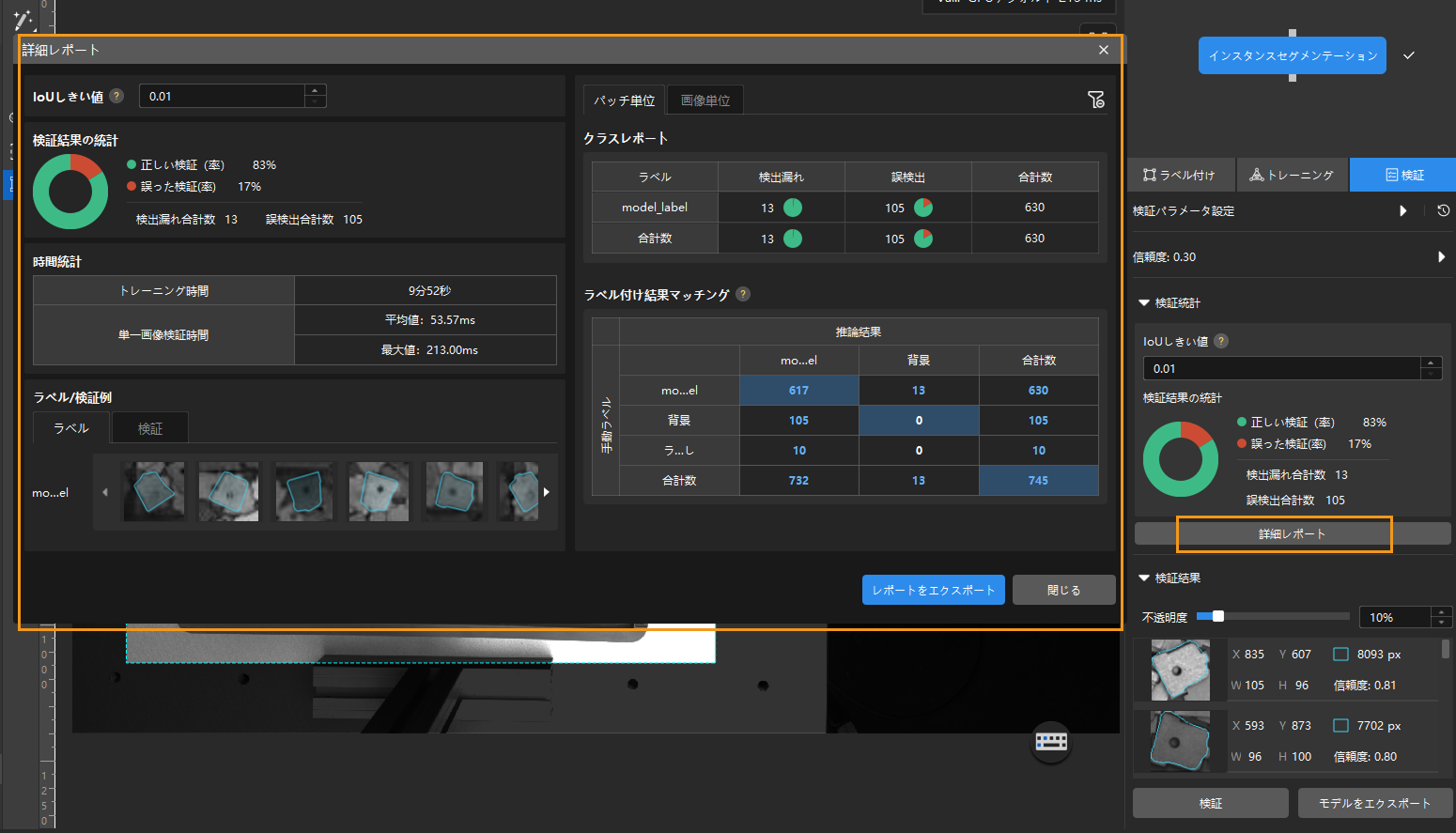
詳細レポートをクリックして詳細レポートウィンドウを開いて詳細な結果データを確認します。
-
レポートのラベル付け結果マッチングには、モデル推論(検証)の結果と手動ラベルとのマッチング関係を示します。
-
表の縦は手動で付けたラベル、横は推論の結果を示します。青いセルは、両方が一致している結果で、その他は最適化が必要な結果です。
-
セルのデータをクリックすればソフトウェアのメイン画面の画像リストに対応する画像だけが表示されます。
-
トレーニングセットと検証セットを検査します。さらに、テストセットは検証におけるモデル汎用性を評価しますので真剣に検査してください。
-
検出漏れに対しては、ラベルを追加して改善できます。ただし、その画像の検出できたエリアと検出できなかったエリアと、全部ラベル付けしてからその画像をトレーニングセットに移動してください。
-
誤検出に対しては、後処理方法で改善します。モデルを適用する時に信頼度を設定することでデータをフィルタリングします。
-
-
トレーニング・検証後に誤検出も検出漏れもない場合に適用可能で汎用性が高いモデルができたことになります。
テストセット内の検出漏れと誤検出がある画像を全て手動的にラベル付けしてトレーニングセットに変更する必要はありません。一部の画像を追加でラベル付けして、トレーニングセットに追加しモデルを再トレーニング・検証します。残りの画像を検証のために使用されます。 詳細レポートウィンドウの右下にあるレポートをエクスポートボタンをクリックし、サムネイルレポートまたは完全画像レポートをエクスポートすることが選択できます。 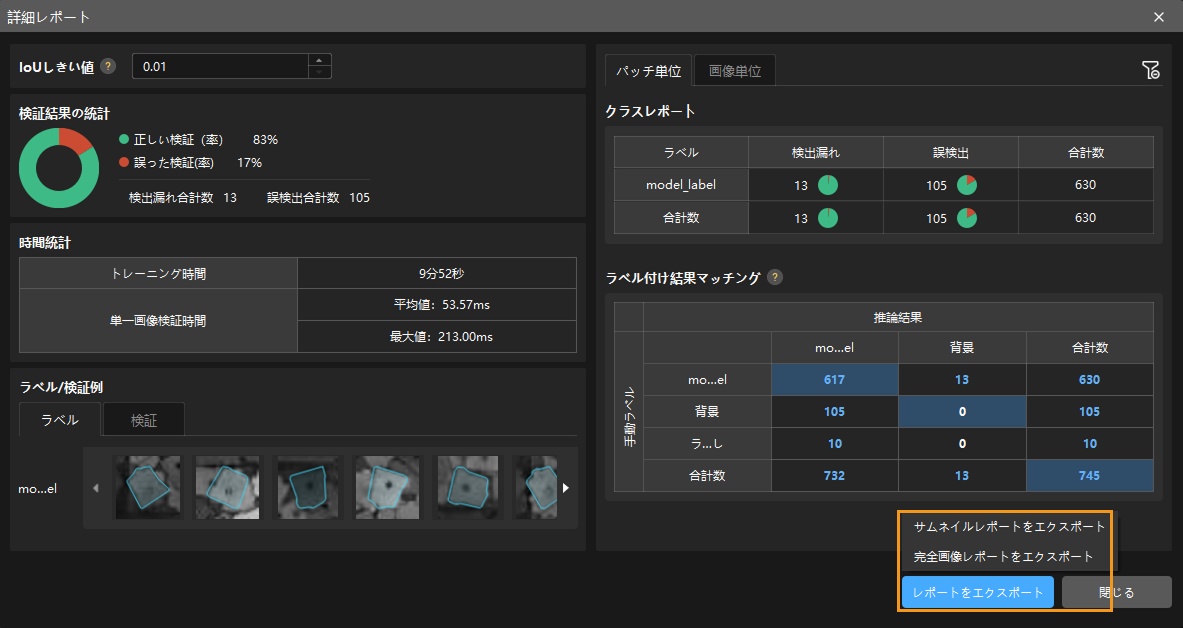
-
-
再トレーニング:新たにラベル付けした画像をトレーニングセットに追加してから、トレーニングボタンをクリックして、再トレーニングを開始します。
-
モデル検証結果の再チェック:再トレーニング終了後、再び検証ボタンをクリックしてモデルの検証を行い、各データセットにおけるモデルの検証結果を確認します。
-
モデルの微調整(オプション):開発者モードをオンにしてトレーニングパラメータ設定でモデルを微調整することが可能です。
-
モデルの最適化:モデルが使用要件を満たすまで上記の手順を繰り返します。
モデルのエクスポート
モデルをエクスポートをクリックします。表示されたウィンドウで保存場所を指定し、モデルをエクスポートをクリックします。

エクスポートされたモデルは Mech-Vision とMech-DLK SDK、Mech-MSR に使用できます。クリックして詳細な説明を確認します。