高度な使用例:大きな画像から微細欠陥の検出
大きな画像にある小さい欠陥を検出する方法については、ここでは Mech-DLK に使用するパソコン筐体画像(クリックでダウンロード)を提供し、欠陥セグメンテーションモジュールを使用しながら説明していきます。データ収集、データ処理、ラベル付け、モデルのトレーニング、画像サイズ設定、モデルのトレーニング、モデルの検証、モデルのエクスポートと、7つの手順で実行します。
| また、お手元のデータも使用できます。ラベル付けの段階に多少異なりますが、全体の操作はほぼ同じです。 |
事前準備
-
プロジェクトを新規作成して欠陥セグメンテーションモジュールを追加:Mech-DLK を起動し、ホーム画面のプロジェクトを新規作成をクリックします。保存パスを選択し、プロジェクト名を入力して新しいプロジェクトを作成します。メイン画面の右上にあるモジュールバーで、入力モジュール下の + ボタンをクリックし、モジュール追加ウィンドウで欠陥セグメンテーションモジュールを選択します。
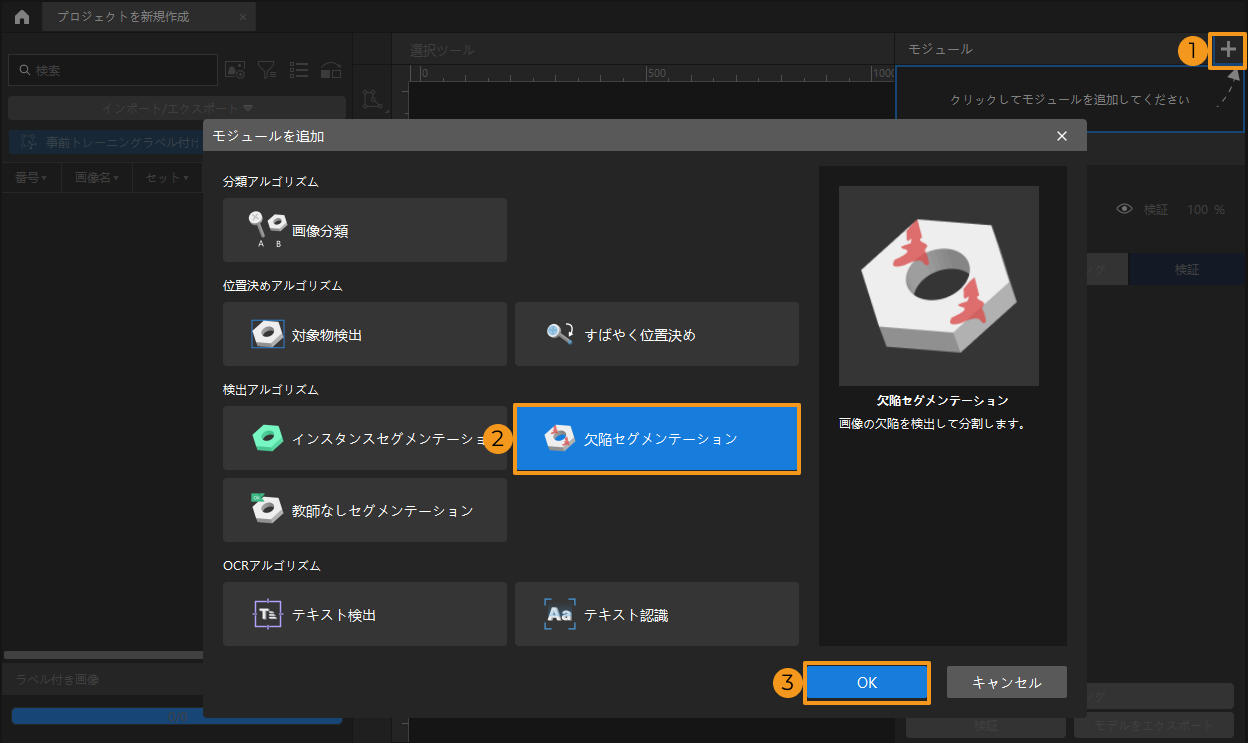
-
画像データをインポート:ダウンロードした圧縮フォルダを解凍し、左上の インポート/エクスポートをクリックし、フォルダをインポートを選択して、ダウンロードした画像データセットをインポートすることができます。
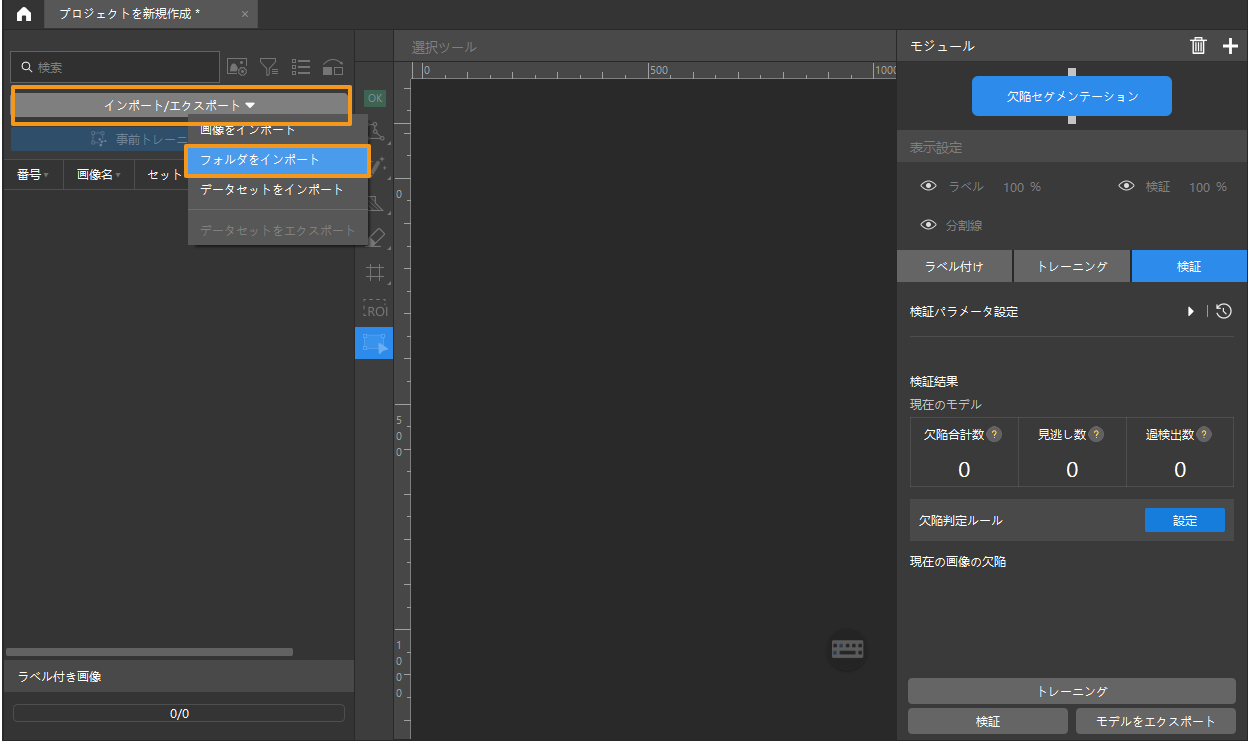
-
画像を閲覧して欠陥の特徴と位置を把握:インポートされたすべての画像を閲覧し、欠陥の特徴および位置を分析します。パソコン筐体の光沢の斑点は欠陥であり、本プロジェクトにおける検出対象です。各画像における欠陥は小さく、位置も一定でないため、ROI 設定やマスクツールを使用することはできません。

データのラベル付け
-
クラスの新規作成:このプロジェクトでは欠陥は一種類しかないのでクラスを 1つ作成します。
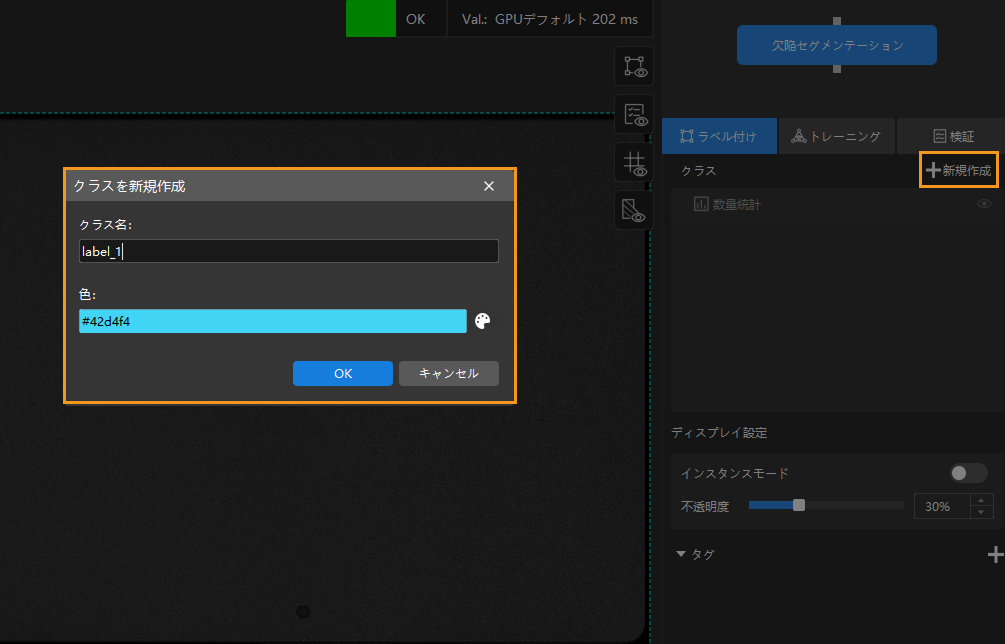
-
画像のラベル付け:欠陥が非常に微細なので、ブラシツールを使用してラベルを付けます。また、ブラシのサイズも小さく調整します(2 に設定)。ラベルを付ける時、欠陥の形状に沿うようにしてください。画像の枚数が多いですが。10 枚程度をラベル付けしてトレーニングしてみます。
Ctrl を押したままホイールを奥に回せば画像を拡大できます。 -
トレーニングセットと検証セットの振り分け:ラベル付けした画像をトレーニングセットに移動します。欠陥のない画像をOK 画像としてトレーニングセットに移動することもできます。そうすると欠陥と OK 画像の識別に役立ちます。これからトレーニングセットと検証セットを分けます。普通、80%をトレーニングセットに、残りの 20%を検証セットに振り分けます。トレーニングセットに移動された画像を自動的に振り分け、ユーザーは割合を指定すればいいです。
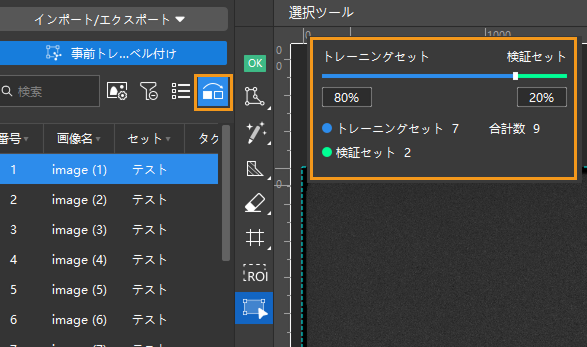
画像のサイズ設定
-
画像を拡大:元画像のサイズが大きくて対象欠陥が非常に小さいので、入力画像のサイズパラメータを使用して画像を拡大表示して欠陥をよりはっきり見えるようにします。トレーニングパネルの拡大・縮小プレビューをクリックしてウィンドウを開き、画像のラベルがきれいに見えるように拡大します。
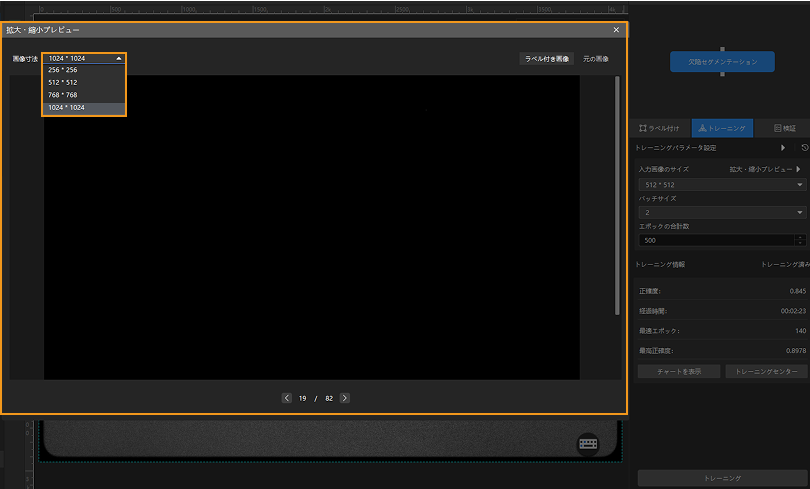
-
グリッド線ツールを使用:グリッド線ツールで画像を数枚の子画像に分割して欠陥ラベルを容易に見られるようにします。ラベルツールバーからグリッド線ツールツールアイコンをクリックします。行数・列数を設定します。適用すると画像が同じサイズの小さな画像に分割されます。例えば行数・列数を3に設定すると以下のようになります。
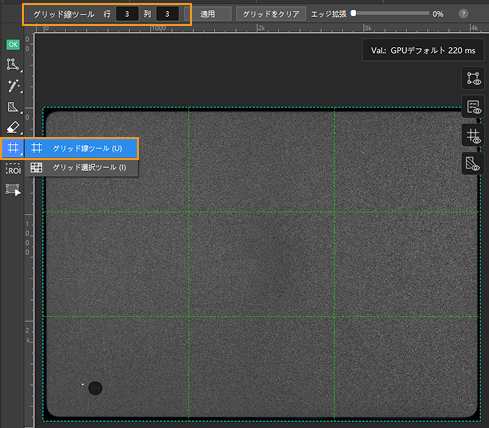
ラベル付け完了後に使用してください。 -
入力画像のサイズをプレビュー・調整:適用をクリックすると画像サイズは分割された、モデルに入力する画像のサイズになります。子画像を確認するには、再度拡大・縮小プレビューウィンドウを開いて指定した行数・列数を入力してください。この例では、画像は 9 枚の画像に分割されます。小さい画像でも欠陥がよく見えるので入力画像のサイズに問題はありません。
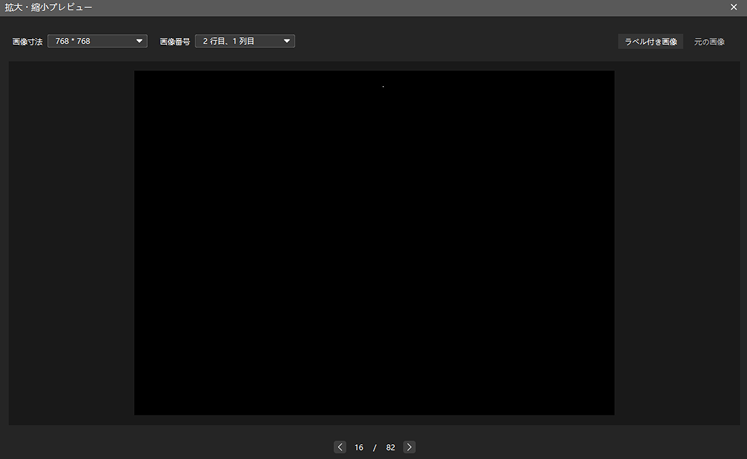
-
エッジ拡張(オプション):ラベルが異なる画像に分割された場合にエッジ拡張機能を使用してラベルが 1 枚の画像に収まるようにします。拡張は全部の画像に適用されます。

-
グリッド選択ツールを使用:画像を分割してからトレーニングに使用する画像の数はおおくなり、トレーニングの所要時間が長くなります。トレーニング時間を短縮するために、ラベルツールバーの
 をクリックしてグリッド選択ツールを選択し、トレーニング工程に使用する子画像を選択します。下図に示します。
をクリックしてグリッド選択ツールを選択し、トレーニング工程に使用する子画像を選択します。下図に示します。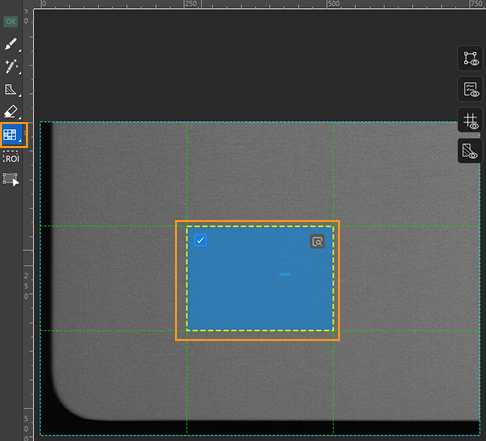
| デフォルトでは欠陥ラベル付きの画像、また OK 画像が分割された小さい画像は自動的にトレーニングに使用されます。 |
モデルのトレーニング
-
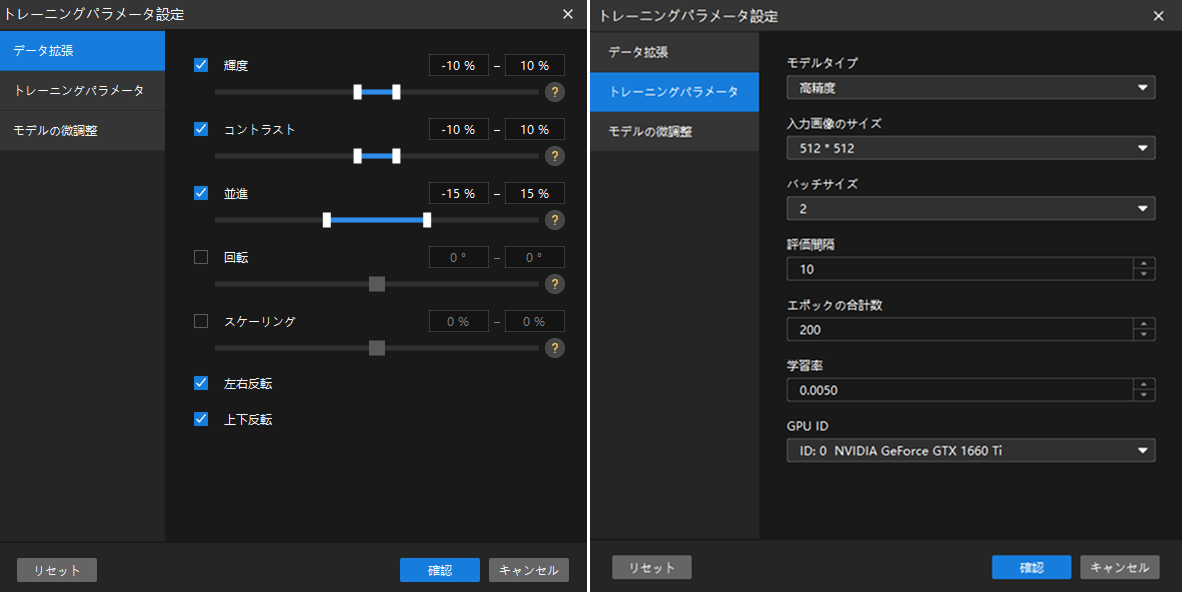
データ拡張パラメータ設定:高精度なモデルを取得するには現場の条件を反映するデータが必要です。本プロジェクトでは、あらゆる照明を再現する画像が必要なので輝度を調整します。また、色がパソコン筐体に近い欠陥もあり、輝度とコントラストも調整します。ただ、子画像のエッジにあるか周囲の色に近い欠陥があるので回転やスケーリングパラメータを使用しません。トレーニングパネルのトレーニングパラメータ設定の右の
 をクリックしてデータ拡張パラメータを設定します。
をクリックしてデータ拡張パラメータを設定します。モデルトレーニングを参考にしてください。
-
トレーニングパラメータ設定:一般的なプロジェクトでは、評価間隔間隔、学習率、GPU ID などは、初期値のままでいいです。
-
モデルタイプ:画像のサイズが大きくて欠陥が微細なので高精度を選択します。
-
エポック合計数:初回のトレーニングに 500 以上に設定し、十分に学習させます。
入力画像のサイズは前の手順で設定したのでここで設定しません。その他のパラメータを調整しなくてもいいです。設定内容を保存します。
-
入力画像のサイズが小さいほどトレーニングと推論のスピードがアップします。
-
サイズが大きいが画像のほうは、精度のより高いモデルが取得できますがトレーニングと推論の速度は下がります。
-
-
-
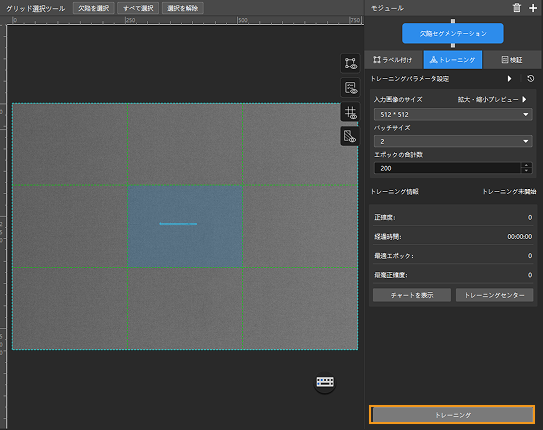
トレーニング実行:パラメータ設定後、トレーニングパラメータのトレーニングをクリックしてトレーニングを開始します。
-
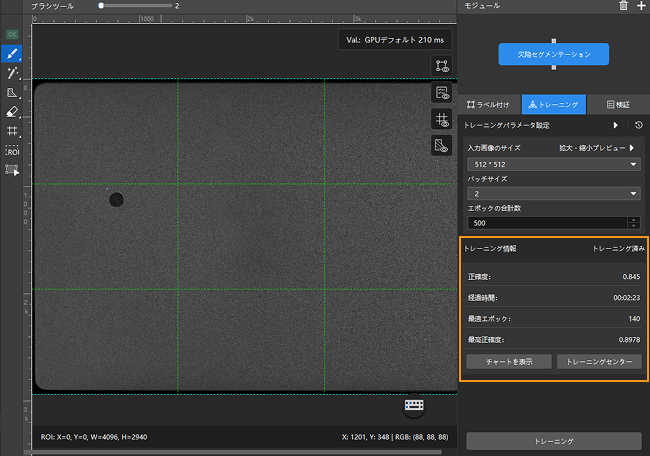
トレーニング状況確認:トレーニングパネルからモデルのトレーニング状況をリアルタイムで確認できます。
-
トレーニングチャートから状況確認:トレーニングパネルのチャートを表示ボタンとトレーニングセンターボタンをクリックしてトレーニングチャートを表示して、曲線の変化から精度の推移を把握します。トレーニングの完了まで待ち、最高正確度を確認し、テストデータ検証結果エリアを観測して初歩的にモデルの効果を評価することもできます。正確度曲線が全体的に上昇傾向、損失曲線が全体的に低下傾向を示すことから、現在のトレーニングプロセスが正常に進行していることがわかります。
-
トレーニング中止(オプション):
-
実際の状況に応じてトレーニングを中止(オプション):モデルの正確度が要求水準に達した場合、時間節約のためトレーニングを中止することができます。また、モデルトレーニングの完了まで待ち、正確度の最大値などのパラメータを観測することで、トレーニングの効果を初期的に判断できます。
-
モデル効果が良くない場合は、トレニンーグを中止してトラブルシューティングを行った後、再度トレニンーグしてください。
-
モデルの検証
-
モデル検証:トレニンーグ終了・中止後、検証パネルに切り替えて検証ボタンをクリックし、モデルの検証を行います。
-
モデルを最適化する時にトラブルシューティング後に再度トレーニング:検出漏れや誤検出が多発した場合にフィルタリングルール設定機能を使用し、ラベルを追加してから再度トレーニング・検証を行います。
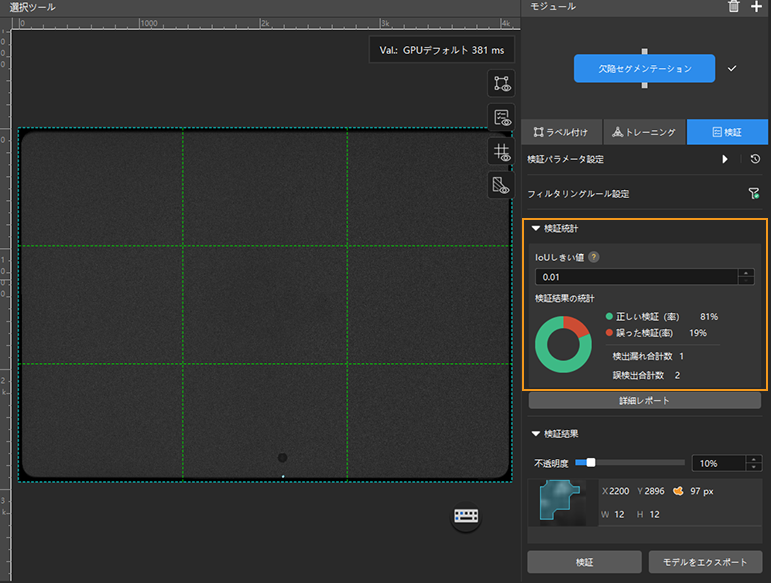
テストセットに検出漏れと誤検出が発生した画像については、ラベルを追加してトレーニングセットに移動し、次回のトレーニングに使用します。 トレーニング・検証後に誤検出も検出漏れもない場合に適用可能で汎用性が高いモデルができたことになります。
テストセット内の検出漏れと誤検出がある画像を全て手動的にラベル付けしてトレーニングセットに変更する必要はありません。一部の画像を追加でラベル付けして、トレーニングセットに追加しモデルを再トレーニング・検証します。残りの画像を検証のために使用されます。 -
モデルをエクスポート:モデルをエクスポートをクリックします。表示されたウィンドウで保存場所を指定し、モデルをエクスポートをクリックします。
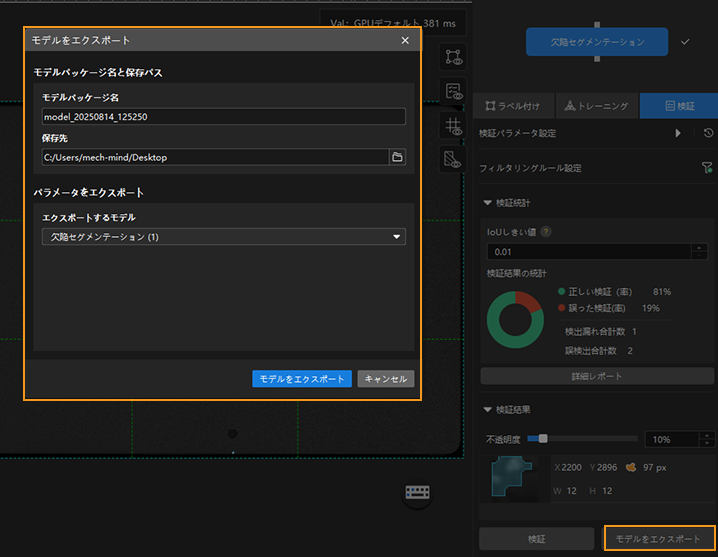
エクスポートされたモデルは Mech-Vision とMech-DLK SDK に使用できます。クリックして詳細な説明を確認します。