Process Images
This topic describes how to preprocess the imported images, filter images, switch the image view mode, and partition training and validation sets, helping you easily view the images and improve the accuracy of model training and validation.
Mech-DLK provides the following image processing tools:
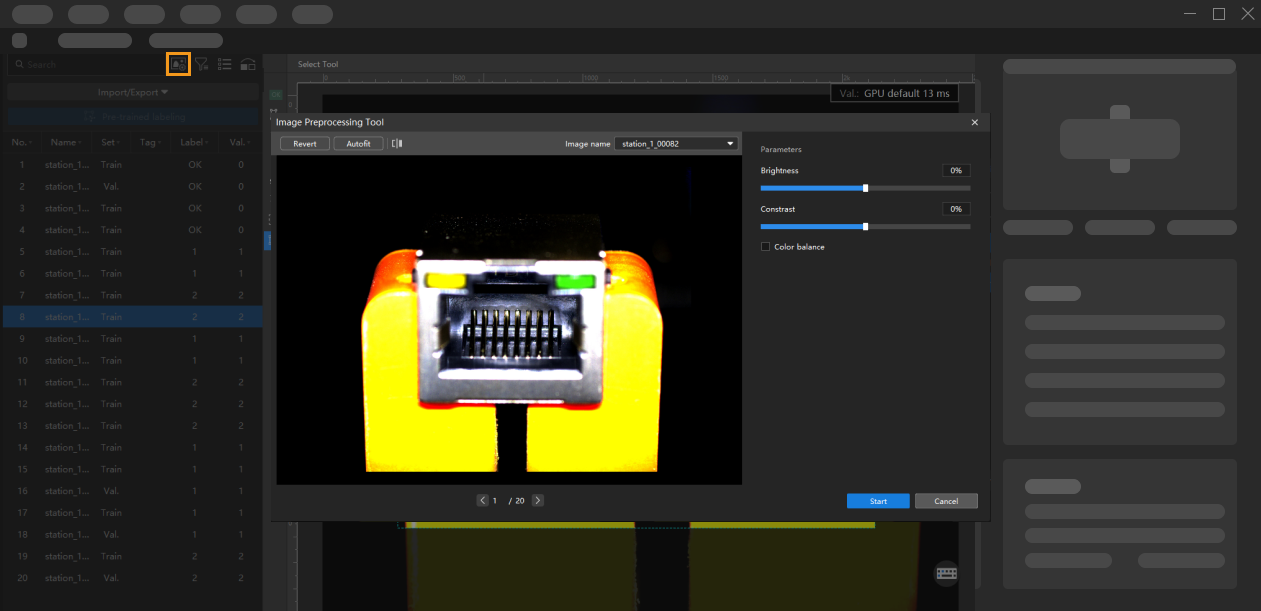
Image Preprocessing
You can adjust the brightness, contrast, and color balance of images.
Typical Usage Scenarios
The original images acquired by the camera might be dark or too bright, or don’t have obvious object features due to lighting or other factors, resulting in poor recognition results. In such cases, you can preprocess images for better results.
Steps
-
On the upper part of the image list, click
 to open the Image Preprocessing Tool.
to open the Image Preprocessing Tool. -
Adjust the parameters to satisfy your needs.
-
Click Start and wait for the processing to complete.
-
Click OK in the pop-up window.
|
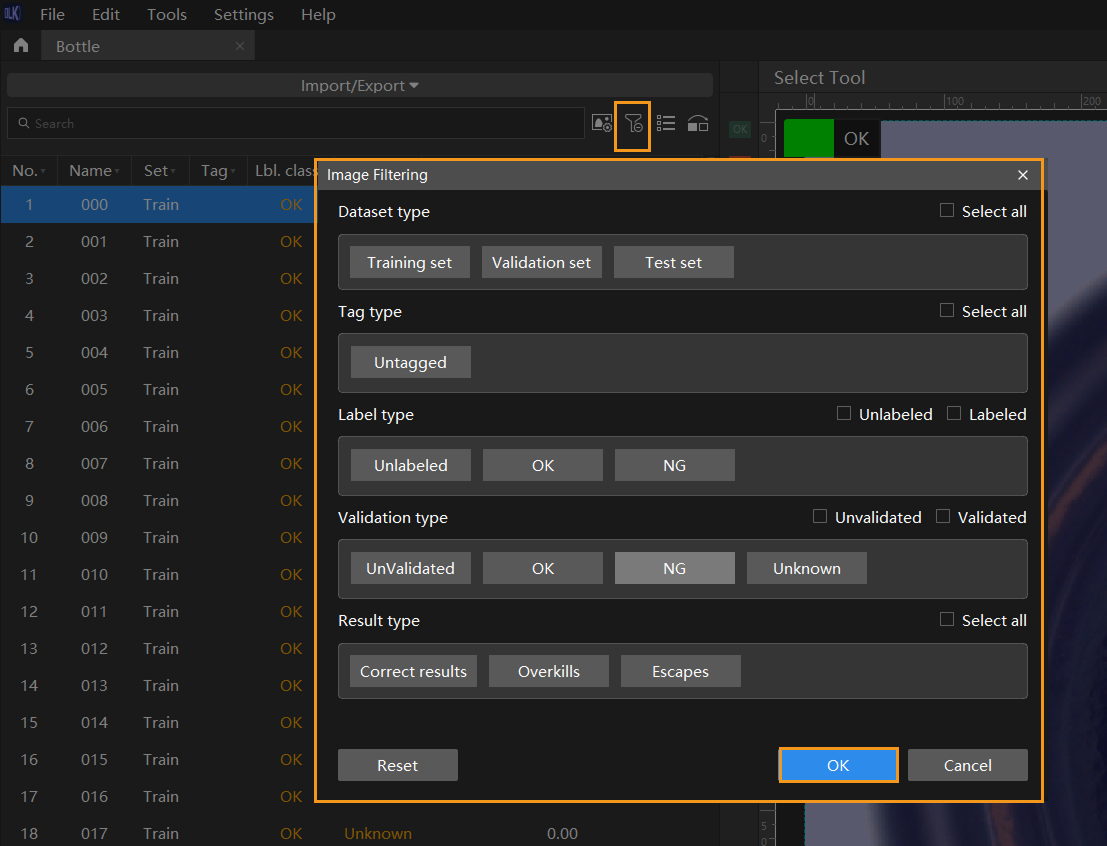
Filter Images
You can set the filtering conditions to conveniently select specific images from datasets.
Typical Usage Scenarios
-
View the results of the dataset division. When the images are divided into different datasets, you can filter images by dataset type to view the content of each dataset and check whether the division results need to be adjusted.
-
Check the data labeling results. During labeling, you can view the labeling progress and labeling results by data type.
-
Check the model prediction results. After validation, you can view the validation results by result type. For example, when a Defect Segmentation model makes an incorrect prediction, you can filter the images by selecting Overkills and Escapes for the result type and do a quick check. The incorrect prediction might result from wrong labels.
Switch to Preview Mode
The list view mode is the default mode, and you can click ![]() to view preview images.
You can drag the slider to change the display size of preview images. Click it again to display the list.
to view preview images.
You can drag the slider to change the display size of preview images. Click it again to display the list.
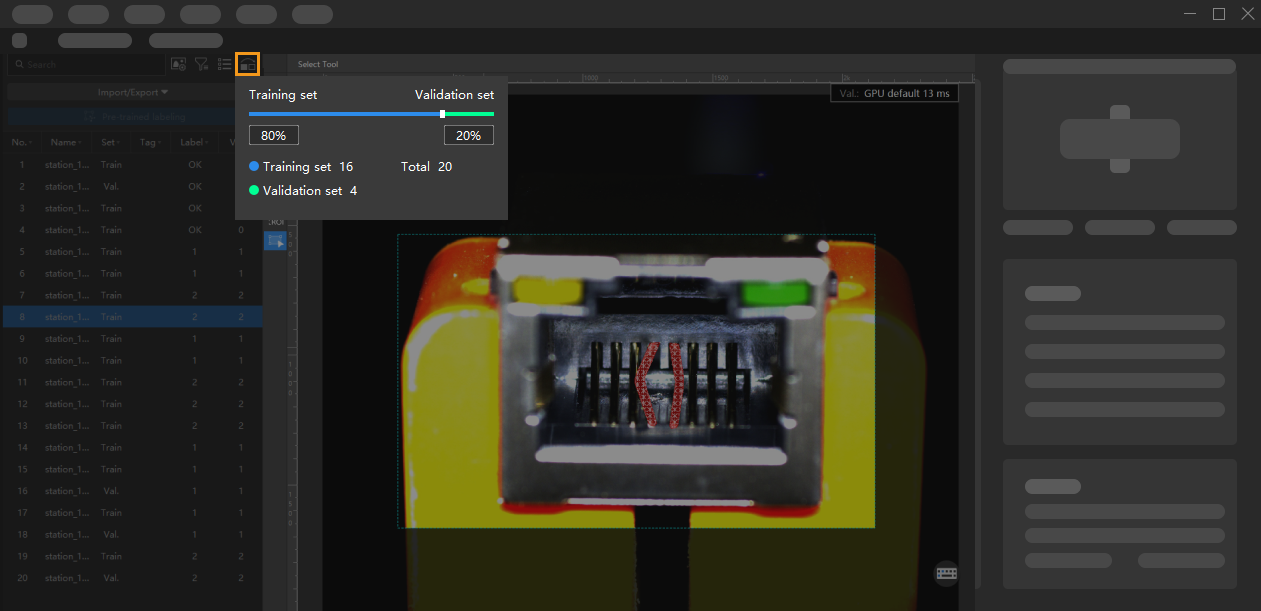
Partition Training and Validation Sets
By default, 80% of the images in the dataset will be split into the training set, and the rest 20% will be split into the validation set. Please make sure that both the training set and validation set include images in all different classes, which will guarantee that the model can learn all different features and validate the images of different classes properly.
-
Training set
The training set is the dataset used to train the model. It usually accounts for the majority of the dataset and contains input data along with correct labels for that data. The model learns patterns and rules from this data and adjusts its parameter settings to accomplish specific tasks.
-
Validation set
The validation set is used to evaluate the model’s performance during training, check for overfitting, ensure the model’s generalization capability, and select the optimal model.
-
Test set
The test set is used to evaluate the model’s generalization capability after training is complete, that is, to assess its performance on new data.
-
Total
The total number of data samples involved in model training, which is the sum of the images in the training set and validation set.
| In Mech-DLK, training can only start after images in the training and validation sets have been labeled. |
Steps
-
On the upper part of the image list, click
 .
. -
Drag the slider to adjust the proportion of the training set and validation set.
Right-click the image and click Switch to training set, Switch to validation set, or Switch to test set on the pop-up menu to modify the set to which the current image belong.
| The test set is used during model validation to evaluate the generalization capability of a model. It is not involved in the training process. |