テキスト認識モジュールの使用例
識別コードのデータ(ダウンロード先)を例に、「テキスト認識」モジュールの使用方法を説明します。画像のテキスト(文字、数字、記号)を認識してエクスポートします。
| また、お手元のデータも使用できます。ラベル付けの段階に多少異なりますが、全体の操作はほぼ同じです。 |
-
プロジェクトを新規作成して「テキスト認識」モジュールを追加:ホーム画面の プロジェクトを新規作成 をクリックし、プロジェクトディレクトリを選択してプロジェクト名を入力し、新しいプロジェクトを作成します。右上の
 をクリックし、「テキスト認識」モジュールを選択します。
をクリックし、「テキスト認識」モジュールを選択します。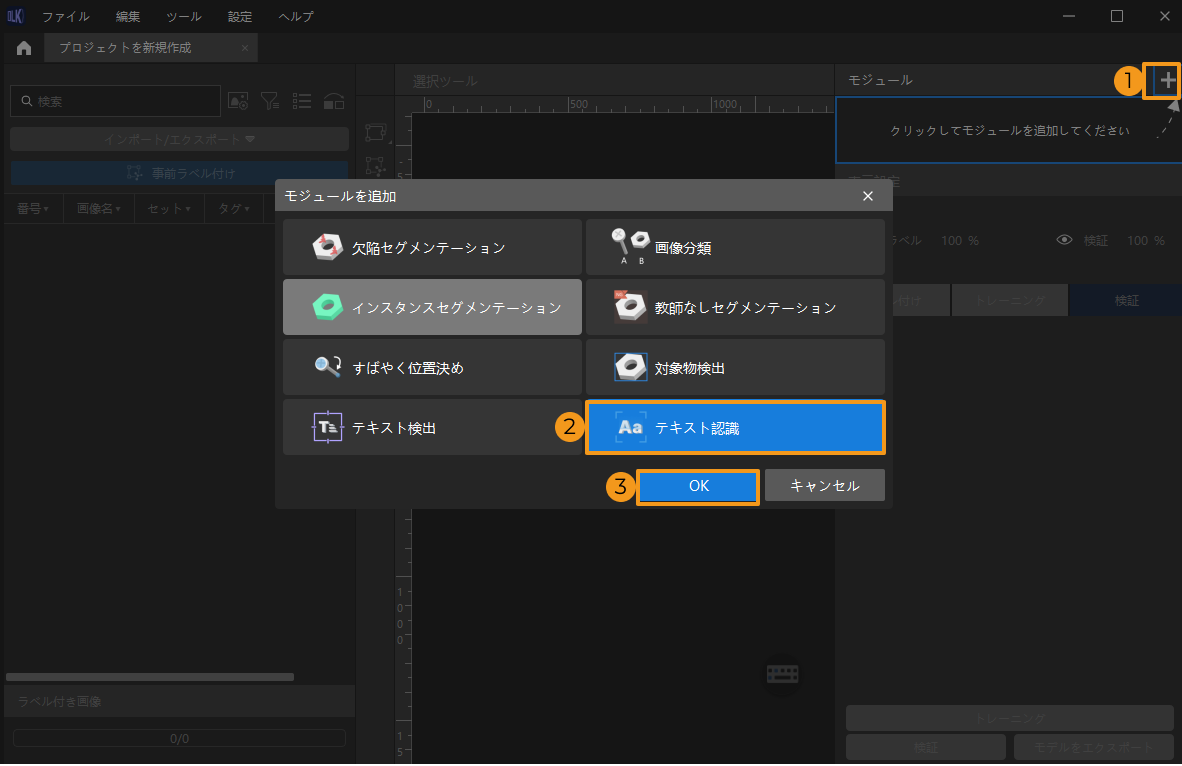
-
ワーク画像データをインポート:ダウンロードした圧縮フォルダを解凍し、左上の インポート/エクスポートをクリックし、フォルダをインポートを選択して、ダウンロードした画像データをインポートすることができます。
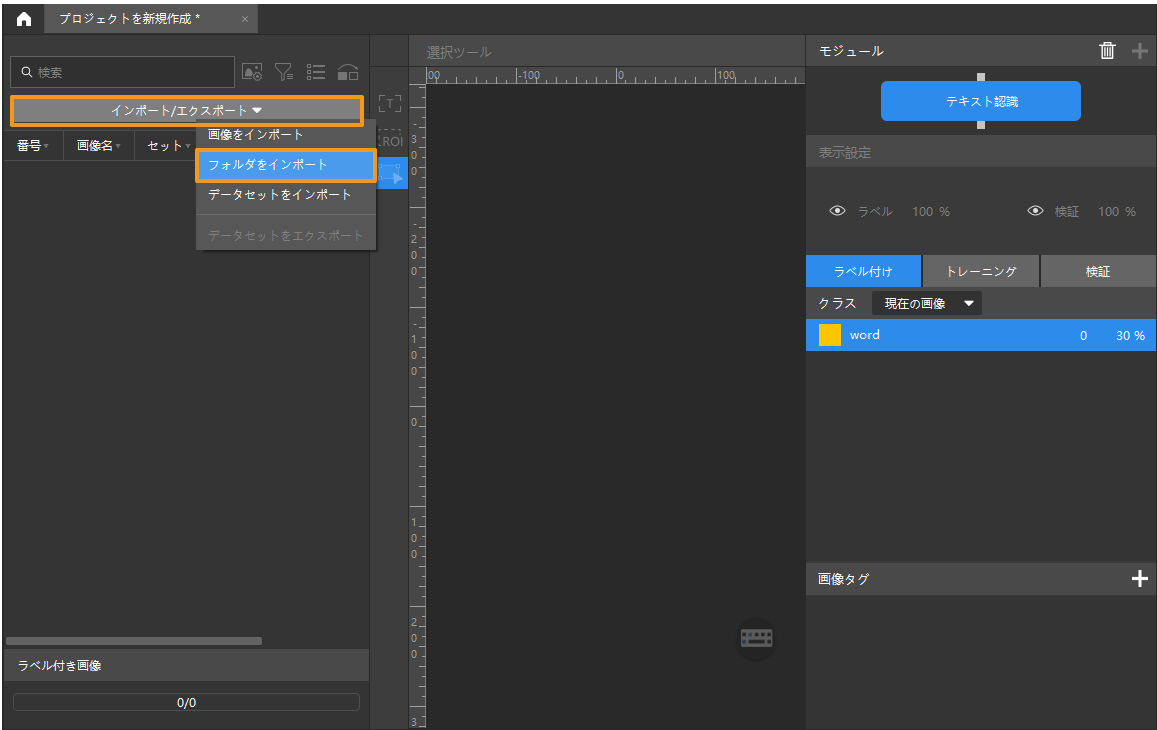
-
テキスト方向が前向き(0°)の画像をインポートしてください。
-
「テキスト認識」モジュールの前に「テキスト検出」または「対象物検出」モジュールを使用し、モデルの効果を向上させることができます。ただ、を選択してください。
-
「テキスト検出」モジュールを前に接続する場合、インポートする時は、「画像補正」機能がオンになっていることを確認してください(デフォルトではオンになっている)。普通、「画像補正」機能は画像を上向き(0°)にしますが上向き画像を180°回転することもあります。実際に応じて使用してください。
-
-
データセットをインポートを選択すると、DLKDB 形式(.dlkd)のデータセット、すなわち Mech-DLK からエクスポートされたデータセットにのみ対応できます。
-
-
ROI を設定:ROI ツール
 をクリックし、画像のテキストを納める領域を設定し、画像の上の
をクリックし、画像のテキストを納める領域を設定し、画像の上の をクリックして適用します。ROI を選択するのは、不要な背景の情報を除去するためです。
をクリックして適用します。ROI を選択するのは、不要な背景の情報を除去するためです。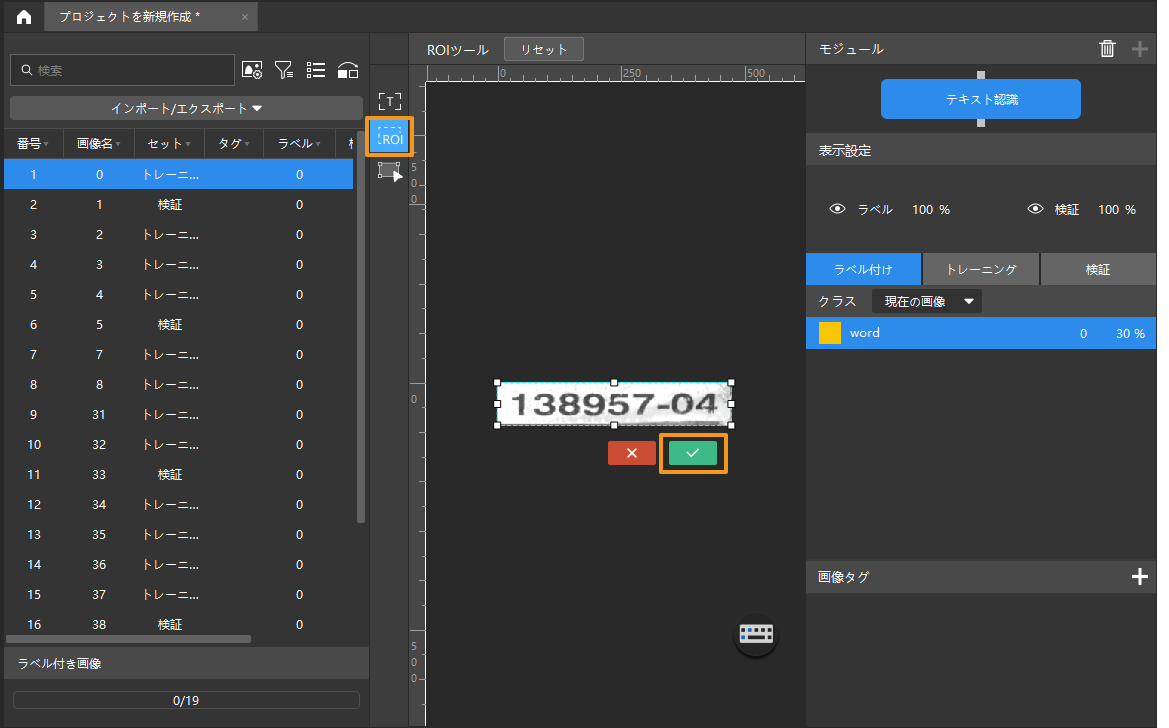
-
画像のラベル付け:画像の左側のツールバーから「テキスト認識ツール」を選択してラベルを付けます。「テキスト認識ツール」を使用してテキスト領域を選択すると認識結果が自動的に生成されます。その後手動で確認します。このように、正確なラベル付けと結果の確認は大事です。
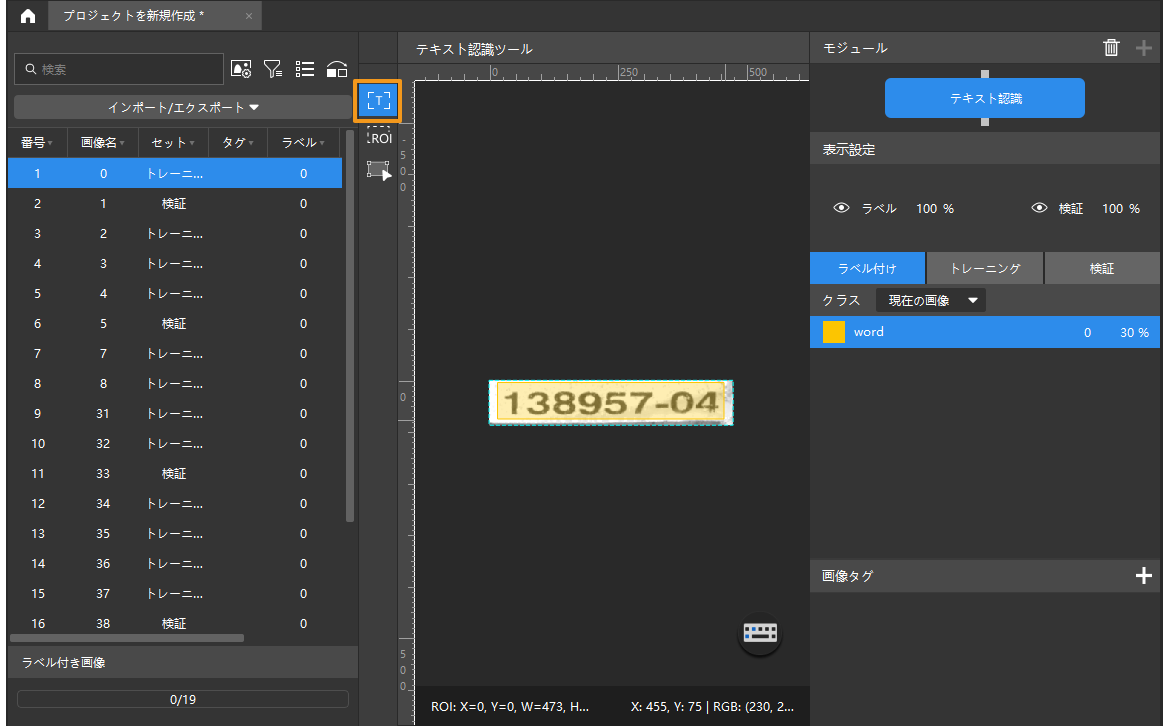
-
トレーニングセットと検証セットを分ける:ソフトウェアでは、デフォルトの設定として、データセットの 80% をトレーニングセット、残りの 20% を検証セットに分けます。
 をクリックし、スライダをドラッグしてその割合を調整することができます。トレーニングセットも検証セットもすべてのカテゴリーのテキスト画像が含まれることを確認してください。そうでなければ画像の名前を右クリックして「トレーニングセットに移動」あるいは「検証セットに移動」をクリックして画像のカテゴリーを変更することができます。
をクリックし、スライダをドラッグしてその割合を調整することができます。トレーニングセットも検証セットもすべてのカテゴリーのテキスト画像が含まれることを確認してください。そうでなければ画像の名前を右クリックして「トレーニングセットに移動」あるいは「検証セットに移動」をクリックして画像のカテゴリーを変更することができます。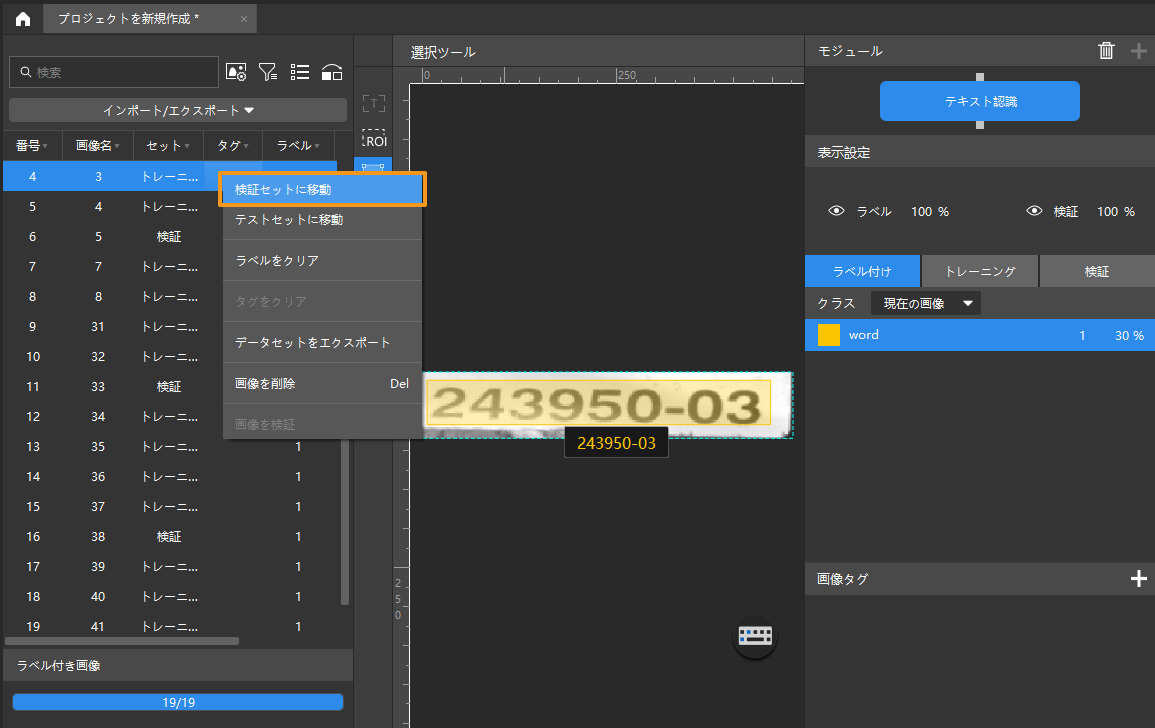
-
モデルトレーニング:デフォルトのパラメータを使って、トレーニング をクリックしてモデルのトレーニングを開始します。
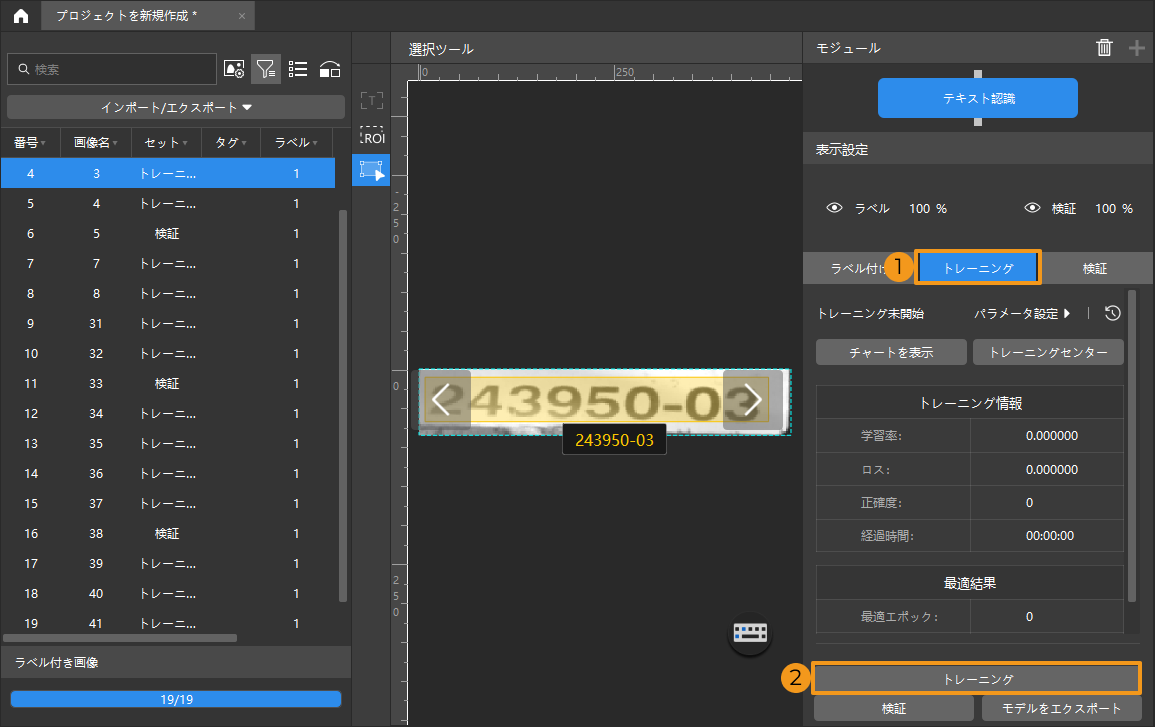
-
モデル検証:モデルトレーニング終了後、検証 をクリックして結果を確認します。
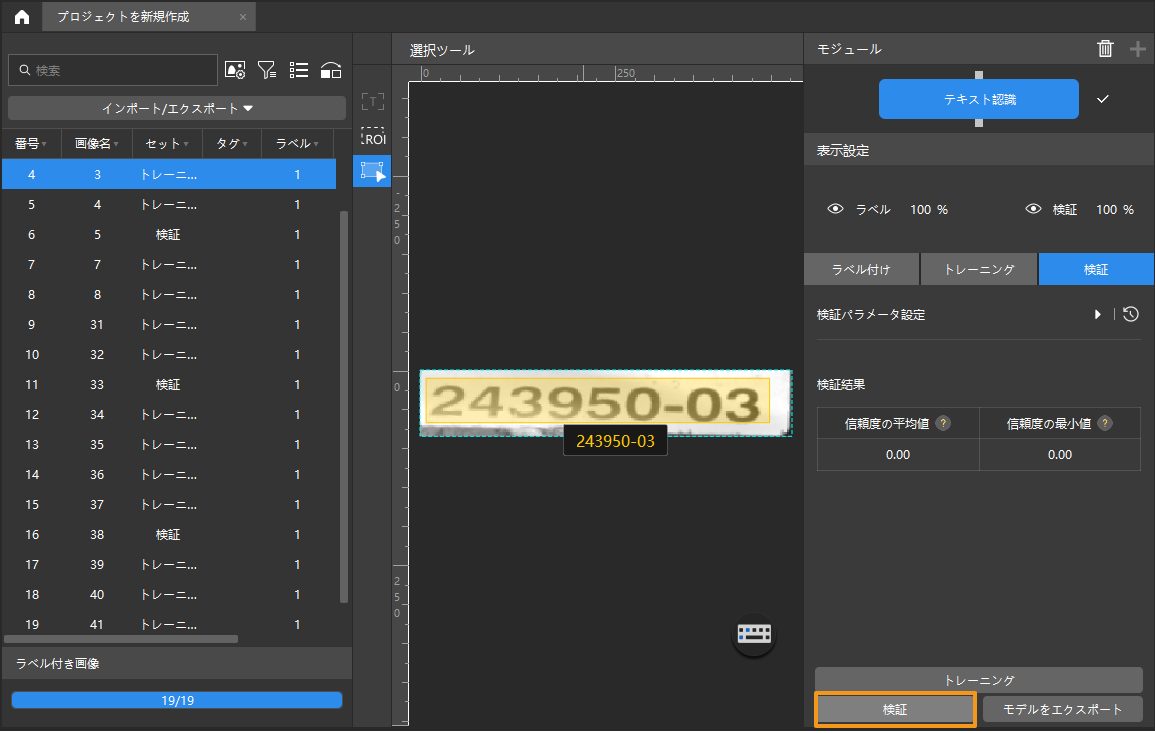
-
モデルをエクスポート:モデルをエクスポートをクリックして保存場所を指定してからモデルをエクスポートします。
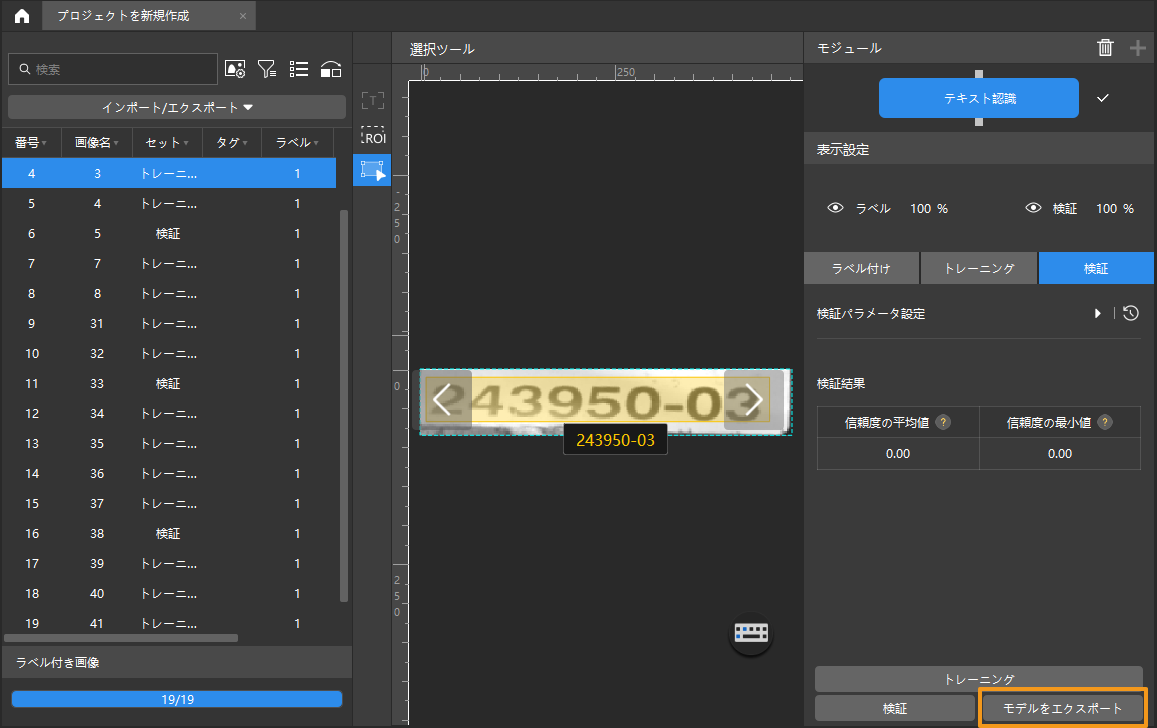
エクスポートされたモデルは Mech-Vision と Mech-DLK SDK に使用できます。クリックして詳細な説明を確認します。