データ収集ルール
ディープラーニングモデルをトレーニングする時、モデルによって学習対象画像から対象物の特徴(色や輪郭の形状、位置情報など)を抽出します。画像の露出オーバー、露出アンダー、色ずれ、ぼやけ、遮蔽などが発生すると、ディープラーニングモデルが必要とする特徴が失われ、モデルトレーニングの効果に影響を与える可能性があります。
本節では、高品質の画像を取得してモデルの精度を確保するために、画像収集前の事前準備や収集中の注意事項、及び画像収集後のフィルタリングについて説明します。
事前準備
現場の照明状況を改善する
Mech-DLK を使用することで現場の照明からの影響をある程度低減できます。照明が変化する場合にもディープラーニング機能が正常に実現します。ただし、照明が激しく変化していると、取得した画像にある対象物のディテールが失われてしまい、ディープラーニング機能に悪影響が出ます。
以下のように、現場の照明は変化することがあります。
-
晩と昼の照明が大きく変化します。(直射日光、通常の照明、照明なし/低照明)
-
人工光源の明るさが大きく変化します。
-
色温度が大きく変化します。
-
カラー画像のピクセル値に大きな影響を与え得るその他の照明の変化。
照明の変化を避けられない場合には、以下の改善策を講じてください。
-
プロジェクトの要件に合わせた遮光・補光設備を使用します。
-
現場により柔軟に適用できるカメラを使用します。対象物の輪郭を認識するだけのプロジェクトの場合、モノクロカメラを使用します。対象物の色を認識する場合にカラーカメラを使用します。
-
Mech-Eye Viewer では、カメラの 2D パラメータの露出モードとホワイトバランスを調整します。
| ROI 内に異常がなければ、ROI 外に露出オーバーなどが発生しても構いません。 |








データ収集中の注意事項
各種の配置状況は、応用現場に合わせて調整してください。例えば、前工程から供給する時に、横向き、縦向き、ばら積みの可能性が考えられます。横向き、縦向きの画像のみを採取した場合、バラ積みの認識効果は保証できません。つまり、データ取得は 現場のあらゆる可能性を考慮 した方針で行います。以下のことにご注意ください:
-
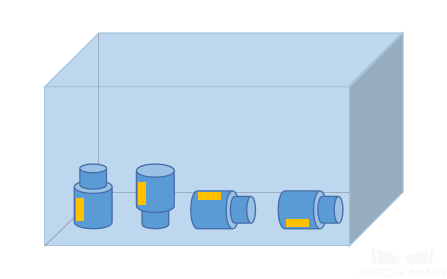
取得したデータに、現場の応用であらゆる 対象物の向き が全部含まれることを確認します。
-
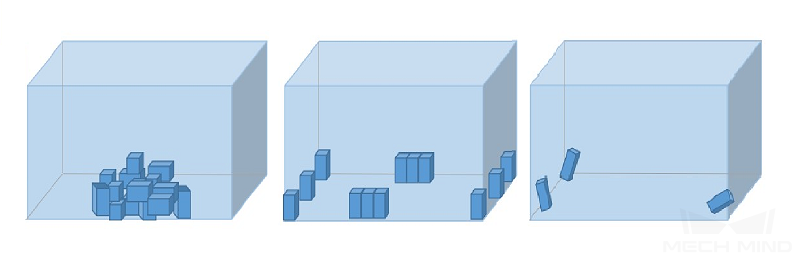
取得したデータに、現場の応用であらゆる 対象物の位置 が全部含まれることを確認します。
-
取得したデータに、現場の応用であらゆる 対象物同士の関係 が全部含まれることを確認します。
| いずれかの配置状況のデータが欠けたら、その状況を学習できず、精度も保証できません。したがって、誤差を低減するために必ずデータの本数と多様性を確保してください。 |
対象物の向き
対象物の位置
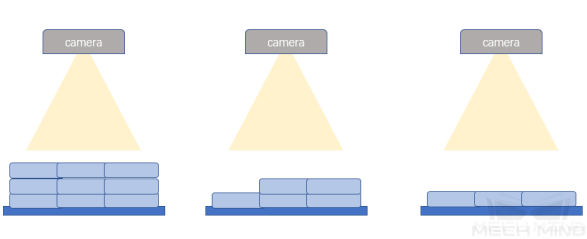
対象物同士の関係
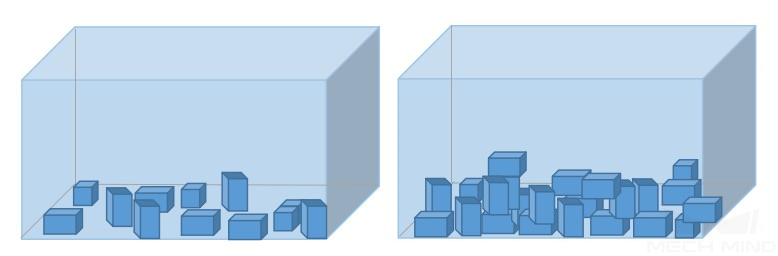

データのフィルタリング
-
トレーニングセットの品質と画像枚数を控える
一部のモジュールを初めて使用する時、トレーニングセットの画像の品質と数を控えることを推奨します。
-
質の高い画像を使用してください。質の低い画像を使用すると、モデルトレーニングに悪い影響を与えます。
-
データ量が多すぎると、トレーニングの時間が長くなり、また後続の改善の妨げになることもあります。
モジュール トレーニングセットの画像の推奨数 インスタンスセグメンテーション
30~50 枚
欠陥セグメンテーション
20~30 枚(欠陥の種類とバラツキに応じて調整すること)
画像分類
30 枚
対象物検出
30 枚
テキスト検出
30~50 枚
教師なしセグメンテーション
OK 画像 30~50 枚
-
-
データの多様性を確保する
-
データセット画像は、検出する対象物の照明環境、色、サイズなどの情報を含んでいる必要があります。
-
照明環境:現場では照明が変化するので、データセットに異なる照明下で取得した画像が含まれている必要があります。
-
色:ワークの色が異なるので、データセットに異なる色の画像が含まれている必要があります。
-
サイズ:ワークのサイズが異なるので、データセットにサイズが異なるワークの画像が含まれている必要があります。
現場のあらゆる状況がトレーニングセットに含まれるように、データ拡張トレーニングのパラメータを調整することでデータセットを補完し、現場でのすべての状況をデータセットに入れます。
-
-
-
各種類のデータを均等な割合で使用する
トレーニングセットに、各カテゴリーや配置状況の画像を均等な割合で使用する必要があります。あるカテゴリーの対象物の画像を 20 枚、別のカテゴリーの画像を 3 枚使用したりしてはいけません。
-
トレーニングセットが使用シーンと一致する
照明環境、ワークの特徴、検査時の背景、視野の広さなど、現場のシーンと一致する背景の画像を使用します。