数据采集规范
进行深度学习模型训练时,模型会提取和学习图像中目标物体的特征,如颜色信息、轮廓形状信息及位置信息等。如果图像出现过曝、过暗、颜色失真、模糊、遮挡等情况,会导致深度学习模型所依赖的特征丢失,影响模型训练效果。
本文介绍图像采集前的准备工作、采集过程中的注意事项与图像采集后的数据筛选标准,帮助您采集高质量图像用于提高模型的识别效果和预测精度。
数据采集前的准备工作
降低光照影响
Mech-DLK 可以在一定程度上抵抗环境光照条件变化的影响。当环境光适度变化时,深度学习功能仍然可以有效工作。但是,如果环境光发生明显变化,不仅光照环境与实际情况不符,图像中目标物体的细节也会丢失,影响模型训练的性能。
环境光的明显变化通常分为以下几种情况:
-
昼夜环境光差距大(阳光直射、正常照明、无照明/低照明)
-
人造光源亮度变化大
-
色温变化大
-
其他可能明显影响彩色图像像素值的光照变化
如果您的工作环境无法避免环境光明显变化,您可以采取以下方式:
-
根据项目要求设计适当的遮光或补充照明解决方案。
-
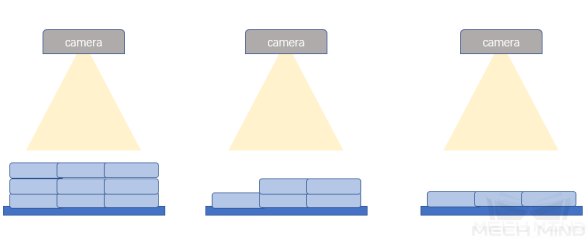
选择适合项目要求的相机类型。如果只需区分工件的轮廓形状,可以使用单色相机。如果同时还需要区分工件的颜色,使用彩色相机可以产生更好的结果。
-
在 Mech-Eye Viewer 中,调整相机的2D参数曝光模式和白平衡,使采集到的图像与实际工作环境保持一致。
| 如果ROI区域外图像出现过曝等情况,而ROI区域内图像正常,则无需进行图像处理。 |








数据采集中的注意事项
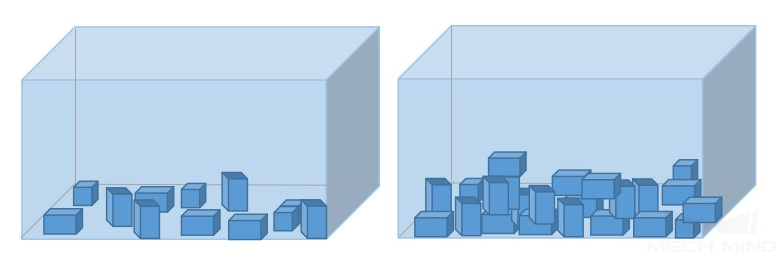
在采集数据的过程中各种摆放情况均需按采集要求合理分配数量,例如实际生产时来料有横向、竖向和散乱堆叠的情况,但只采集了横向和竖向来料的图像数据进行训练,那么无法保证散乱堆叠的识别效果。因此,采集数据时需要能 包含实际生产的各种场景 ,具体包括:
-
确保采集的数据中包含实际应用所有可能出现的 物体朝向 。
-
确保采集的数据中包含实际应用所有可能出现的 物体位置 。
-
确保采集的数据中包含实际应用所有可能出现的 物体间关系 。
| 如果少采集了某种情况,深度学习模型将会缺少对于该情况的学习,会导致模型在该情况下无法有效识别,必须根据情况增加数据样本,降低误差。 |
物体朝向
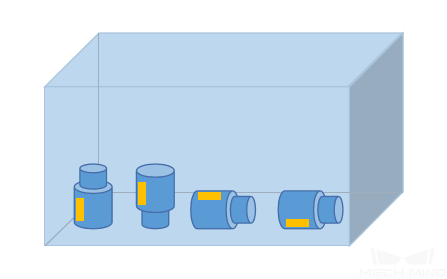
物体位置
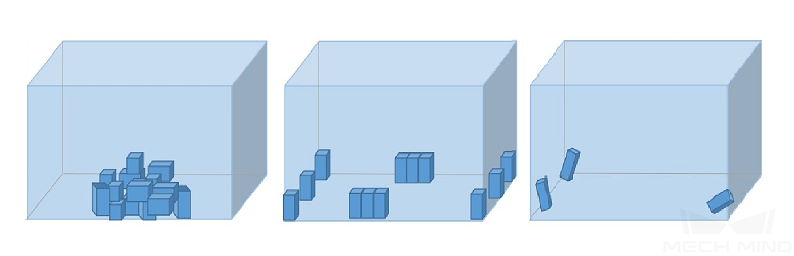
物体间关系

数据采集后的筛选标准
-
训练集质量与数量可控
初次使用部分模块时,建议控制训练集中的图像质量和数量。
-
采用高质量图像,确保导入的每张图像都能有利于模型训练。添加低质量或不相关数据可能会对模型训练产生负面影响。
-
数据量并不是越大越好,前期加入大量无效的数据不利于后期的模型改进,同时还会延长训练时间。
模块 建议训练集图像数量 实例分割
30~50 张
缺陷分割
20~30 张(根据缺陷类别和差异程度适当调整数量)
图像分类
30 张
目标检测
30 张
快速定位
40 张
文本检测
30~50 张
文本识别
40 张
非监督分割
30~50 张 OK 图像
-
-
数据具有代表性
-
图像一定要涵盖待检测目标的所有光照、颜色、尺寸等信息。
-
光照:实际存在光照变化,数据应该包含不同光照情况下的图像。
-
颜色:工件存在不同颜色,数据应该包含所有颜色的图像。
-
尺寸:工件存在不同尺寸,数据应该包含所有不同大小尺寸的图像。
若实际现场工件会出现旋转、缩放、或其他情况,无法采集相应图像数据时,可以通过调整数据增强训练参数的方式来补充数据,以确保现场所有的情况都包含在训练集内。
-
-
-
数据占比均衡
训练集中不同种类或不同摆放方式的图像比例要均衡,否则会影响模型效果。禁止出现一种物体 20 张,另一种物体仅有3张的情况。
-
数据与终端场景保持一致
图像要与最终模型使用的终端场景保持一致,包括光照条件、工件特征、检测背景、视野大小等。