使用实例分割模块
本文提供异型钣金件数据(单击下载),带领用户使用实例分割模块训练模型。整体流程包括六个步骤:数据采集、数据处理、数据标注、模型训练、模型验证、导出模型。
| 用户可使用自己准备的数据。整体使用流程一致,标注环节存在差异。 |
数据采集
请严格遵循数据采集规范采集业务所需图像数据。根据项目需求调节2D曝光和白平衡设置,提升图像质量;此外,为了提升模型的泛化能力,还需要手动调整工件摆放位置和姿态,增强数据的多样性。完成采集后,筛选图像,保留符合要求的高质量图像用于后续的标注和训练。


数据处理
-
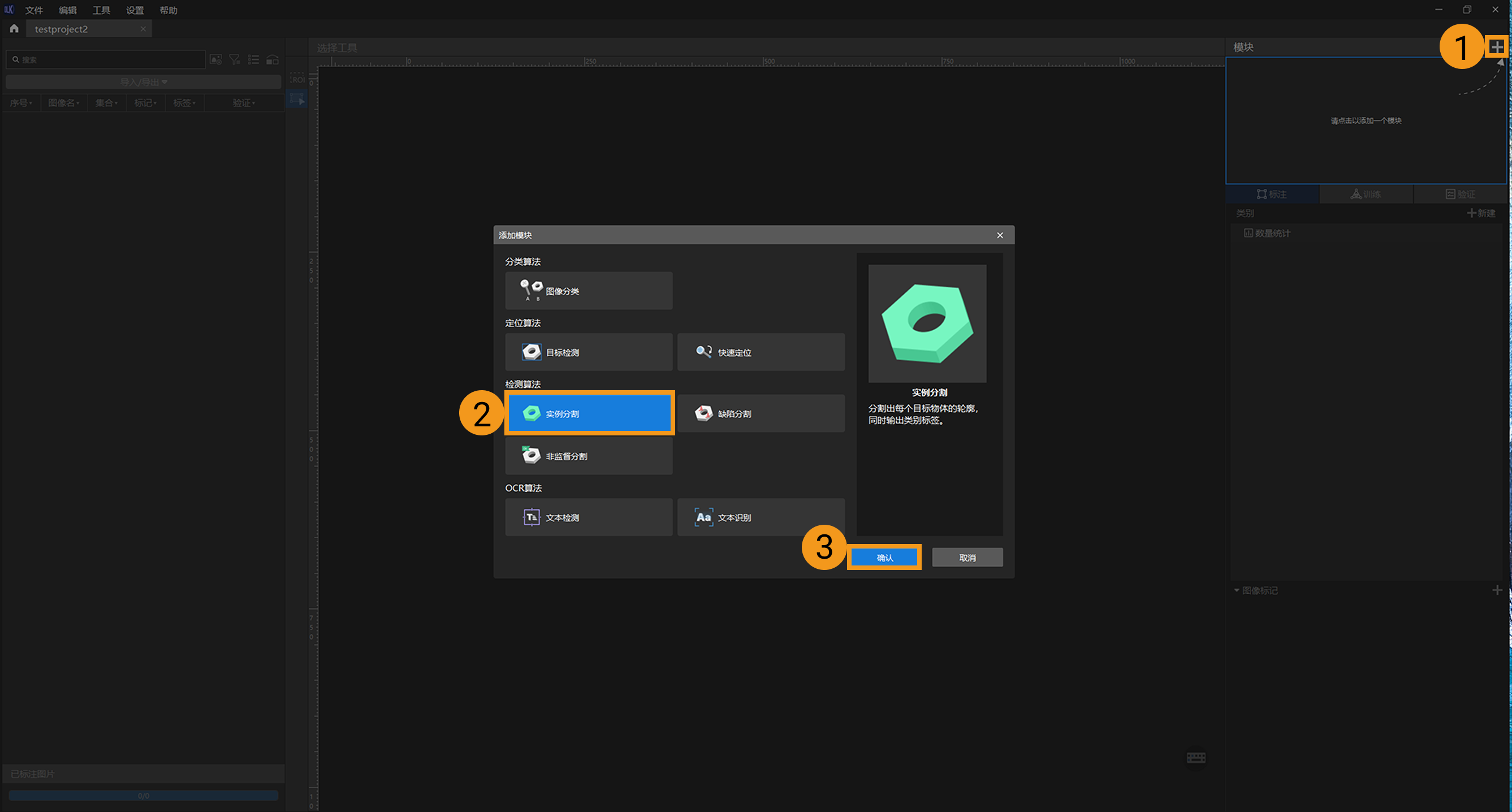
打开 Mech-DLK,单击初始页面上的新建工程 ,选择工程路径并输入工程名以新建一个工程。再单击右上角的 +,选择实例分割模块。
-
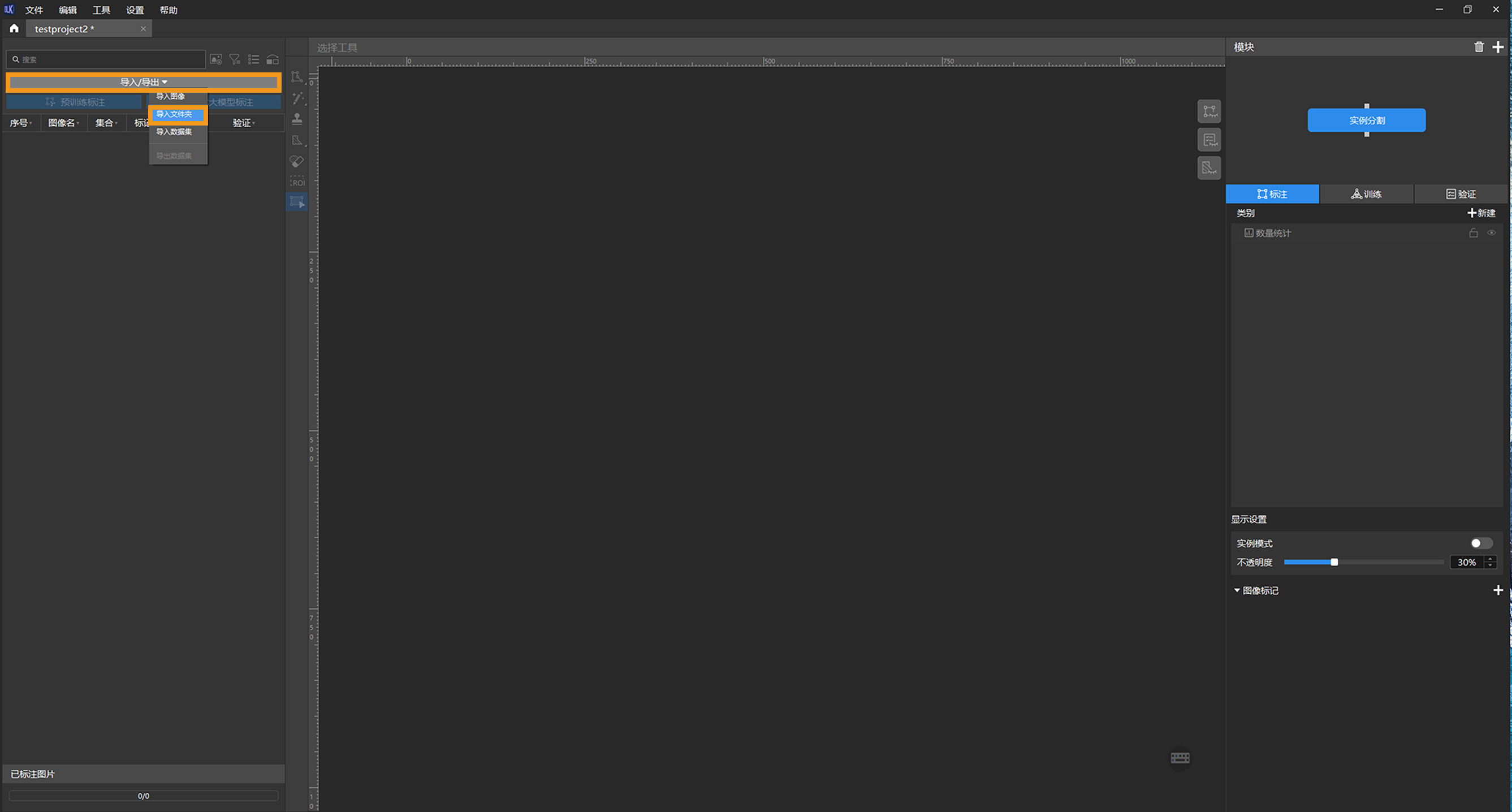
导入图像数据:导入采集得到的图像数据或解本文提供的数据压缩包,单击左上方的 导入/导出 ,选择 导入文件夹 导入图像数据。
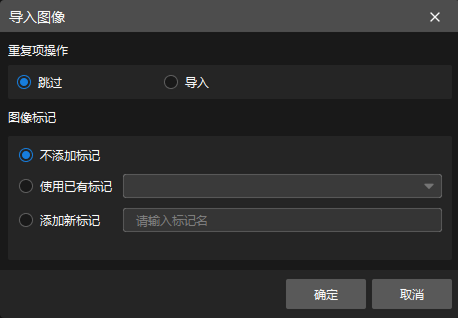
若图像数据中有重复图片,可在弹出的导入图像 对话框中选择跳过或导入、设置标记。由于每张图片只支持一个标记,因此对已有标记的图像添加新标记后,新标记会覆盖旧标记。若导入数据集,可选择是否替换重复图像。
-
选择导入图像、导入文件夹方式时的对话框:
-
选择导入数据集方式时的对话框:
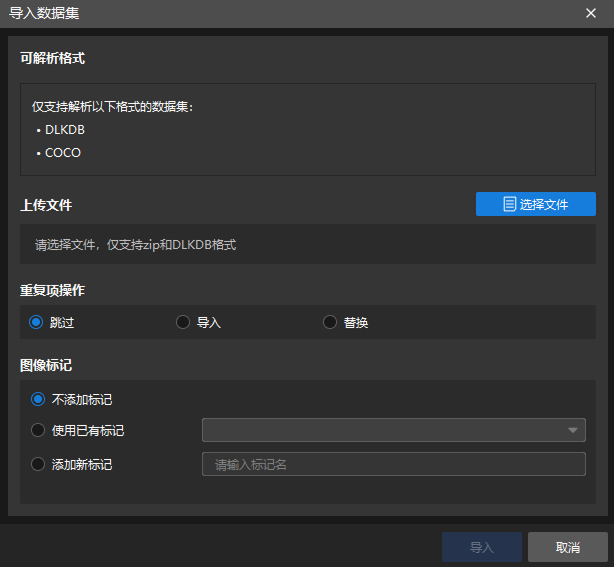
选择导入数据集选项时,此模块支持导入 DLKDB 格式(.dlkdb)和 COCO 格式的数据集(单击下载示例数据集)。
-
-
截取 ROI:单击选项
 从图像中框选料筐作为感兴趣区域,并单击 ROI 边框右下角的
从图像中框选料筐作为感兴趣区域,并单击 ROI 边框右下角的  应用当前ROI。截取 ROI 的目的是减少无关背景信息的干扰。
应用当前ROI。截取 ROI 的目的是减少无关背景信息的干扰。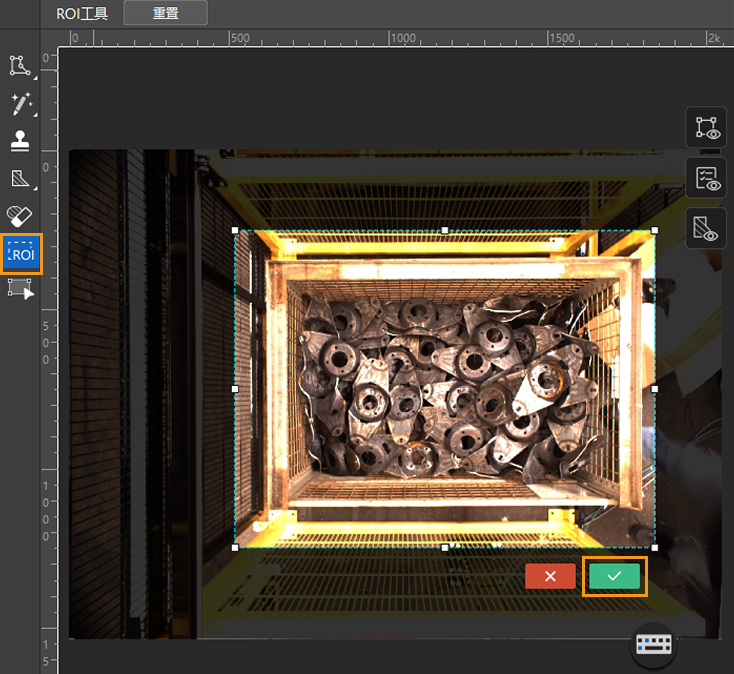
-
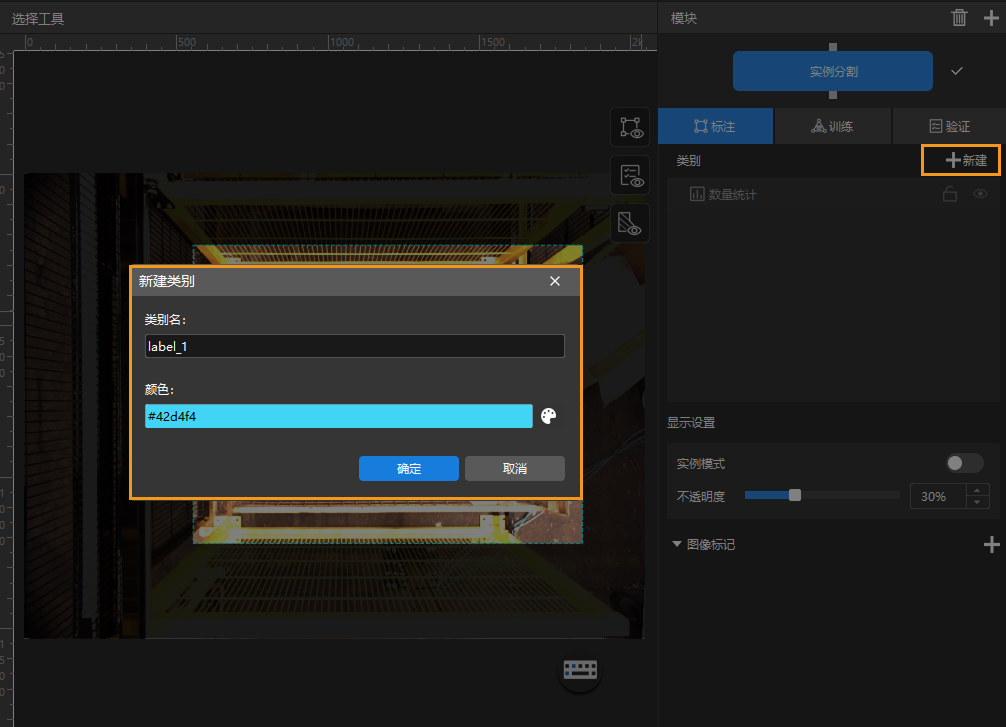
创建类别:单击右侧标注栏下的 +新建,根据物体名称或特征创建对应的类别。本项目中需要识别的工件只有一种,且无正反面区分等特征要求,因此创建一个类别即可。如果需要识别多种工件,可以选择根据工件的特征创建多个类别并分别命名。
选中一个类别后,可右键选择合并至选项,将当前类别下的数据更改为另一类别。若在训练模型后进行了类别合并操作,建议重新训练模型。 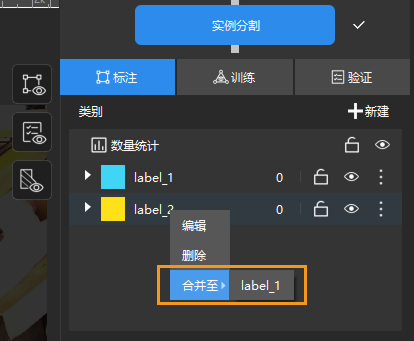
数据标注
请严格遵循数据标注规范进行标注。
-
统一标注规则:本场景中,仅需标注最上层裸露工件,其抓取中心点和两端未被严重遮挡,抓取点未紧贴料筐。
长按Ctrl键并向上滚动鼠标中键可以放大图像,方便更精准地标注。 -
标注数据:鼠标左键长按或右键单击图像左侧工具栏
 ,选择标注工具。
,选择标注工具。本场景中,工件形状不规则,因此选择使用多边形标注工具,设置多个锚点绘制多边形标注。图像数据量较大,无需标注全部数据,可以先准确标注少量数据进行训练(例如在本场景中,选择10张图像进行标注即可)。同时,根据工件位置等特征,优先选择差异较明显的图像数据进行标注。
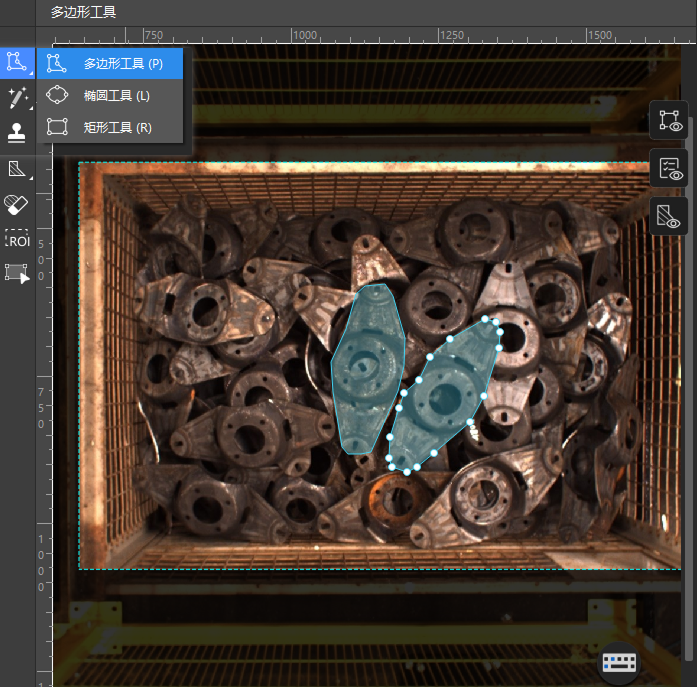
更多标注工具使用详解,请参照 标注工具 。 -
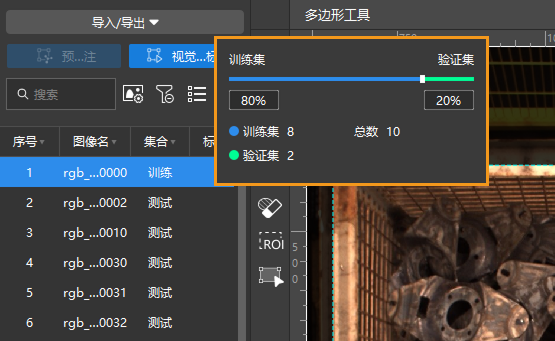
划分训练集和验证集:将标注过的图像移动至训练集中并划分训练集和验证集,一般场景推荐将80%的数据划分为训练集,20%划分为验证集。软件会自动将已经标注完成并移动至训练集中的图像数据进行划分。
训练模型
-
配置数据增强参数:理想的训练数据应该反映实际生产条件中的各种情况,例如在本项目中,图像数据应体现现场多种光照条件。

-
本场景中采集图像时光照较亮,因此可以适当调小亮度,提高模型的稳定性和使用效果。
-
工件与背景色差较小,因此建议调节对比度参数,使模型能够更精准识别工件。
-
料筐内最上层工件散乱堆叠,存在多种平移、旋转和翻转的姿态,因此需要在避免工件特征丢失的前提下,适当调整平移、旋转和水平翻转、垂直翻转参数,确保模型能够识别出各种姿态的工件。
-
本场景使用的图像数据中会出现尺寸相近的工件,因此可以适当调整缩放参数。
-
-
配置训练参数:

-
输入图像尺寸是指训练时输入模型的图像宽高像素数,图像尺寸越大,模型精度越高,但训练速度越慢。因此在保证能够看清楚标注和工件细节的前提下,为了节省训练时间,可以适当降低图像尺寸大小。本场景使用默认值即可。
-
总轮次是指模型训练的总轮次数。由于本场景中工件特征比较复杂,因此需要增加训练轮次。
-
其他参数值保持默认即可。
-
本场景不涉及模型微调,保持默认即可。
-
点击确认保存设置。
请参阅参数说明了解各参数详细说明。
-
在输入图像尺寸满足要求的情况下,较小的输入图像尺寸有助于加快模型训练和推理速度。
-
较大的输入图像尺寸有利于验证区域和缺陷区域轮廓的拟合,提高模型精度,但会增加训练轮次和模型训练时间。
-
-
-
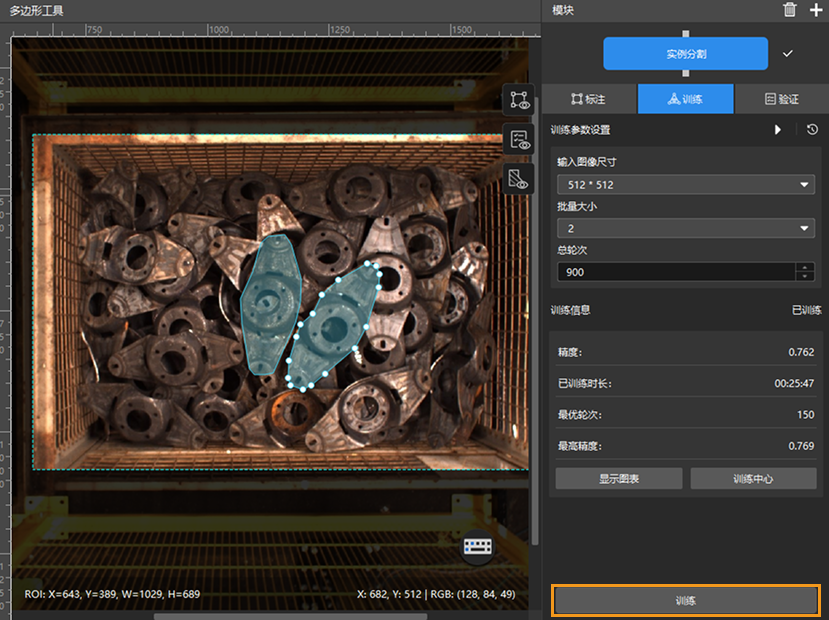
启动训练:单击训练选项卡下的训练按钮,即可开始训练模型。
-
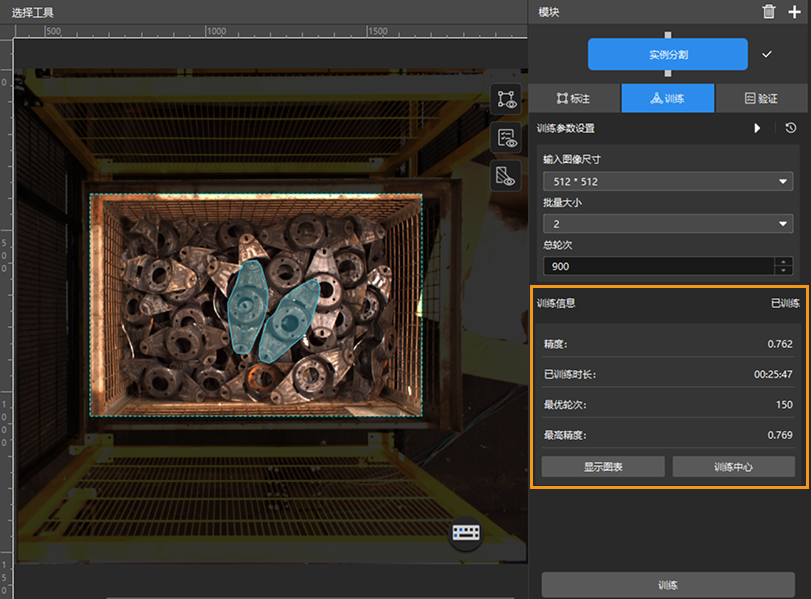
通过训练信息观察训练情况:在训练选项卡下的训练信息栏,可实时查看模型训练信息。
-
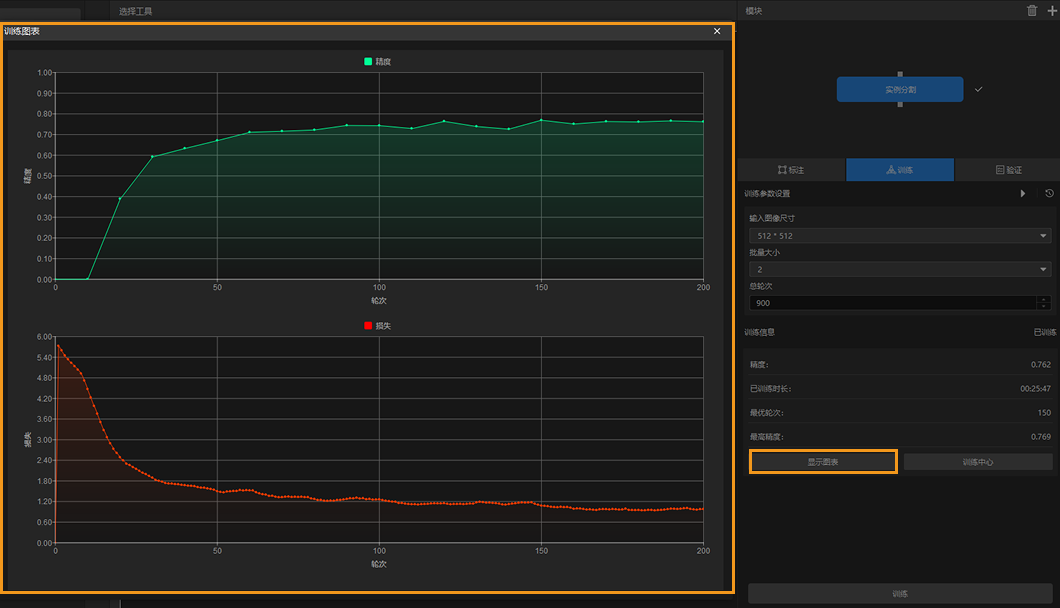
通过训练图表窗口和训练中心查看训练情况:单击训练选项卡下的显示图表和训练中心按钮,即可实时查看模型精度曲线和损失曲线变化情况以及训练进程。用户可等待模型训练结束,观察最高精度参数和测试集验证结果区域,判断模型训练效果。精度曲线整体呈现上升趋势、损失曲线整体呈现下降趋势表明当前训练正常运行。
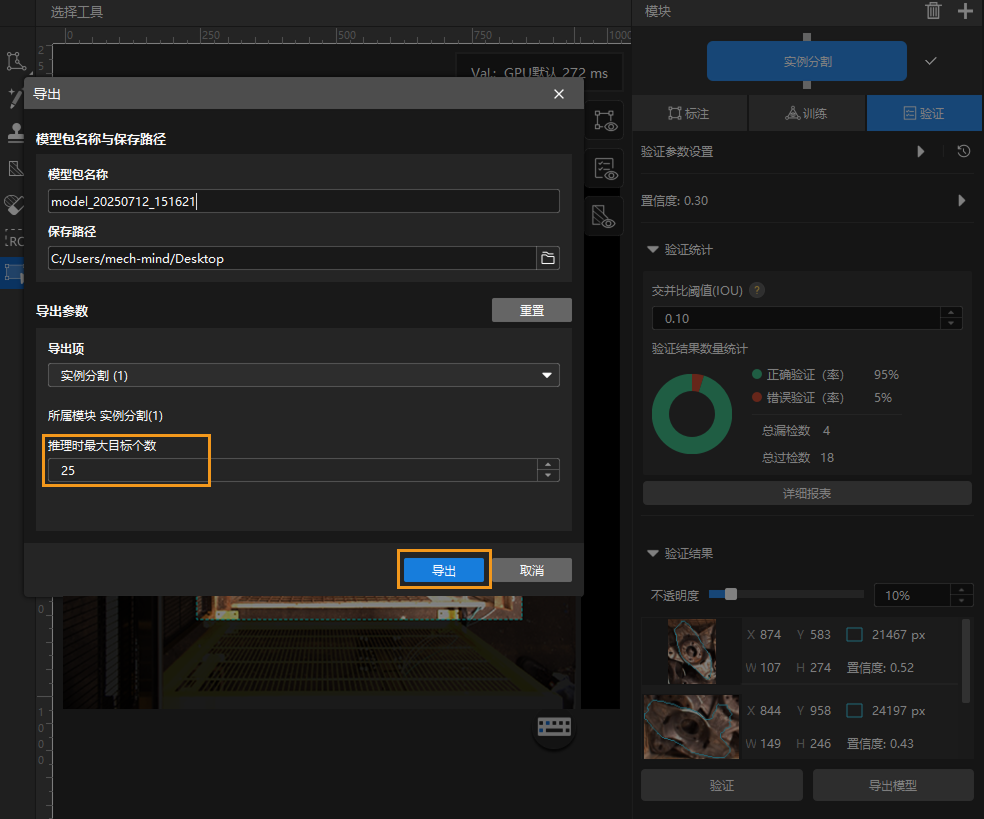
验证模型
-
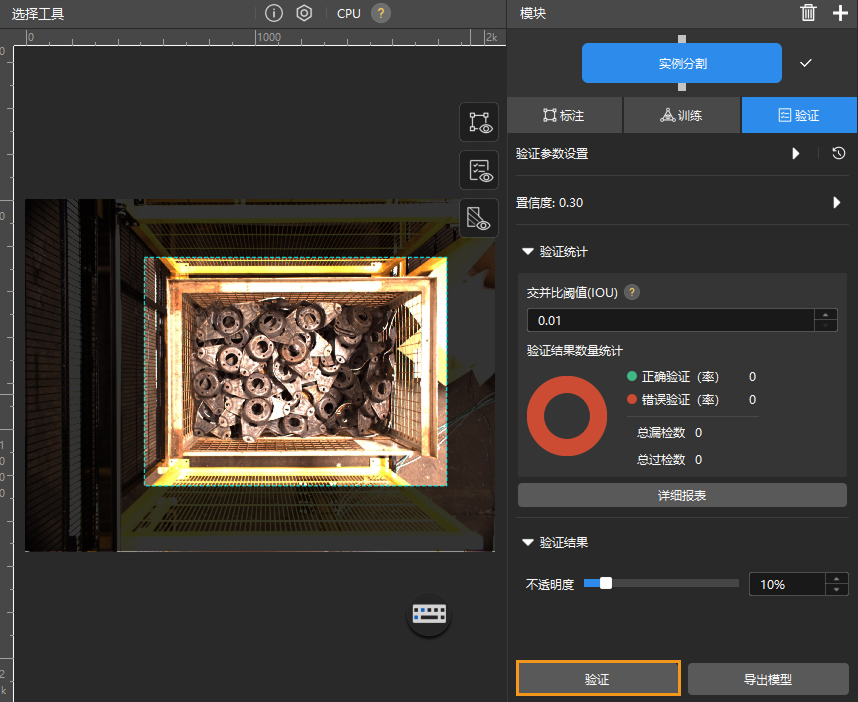
验证模型:训练完成后,单击验证选项卡下的验证按钮,验证模型。
-
检查训练集中模型的验证结果:验证结束后,可在验证选项卡的验证统计中查看验证结果数量统计。
-
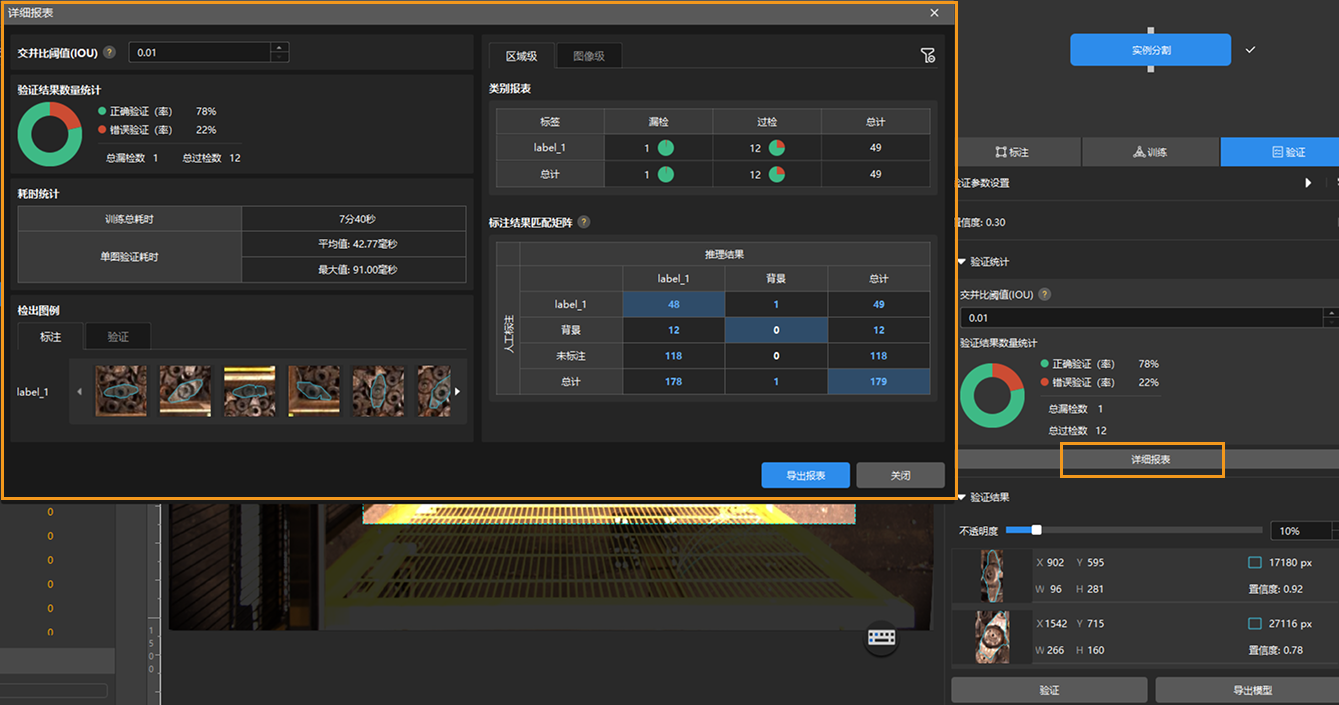
点击详细报表按钮可打开详细报表窗口,查看更具体的验证统计结果。
-
报表中的标注结果匹配矩阵显示模型推理结果与人工标注之间的对应关系,可以此判断模型中各类别的匹配情况。
-
矩阵纵向为人工标注数据,横向为推理结果;矩阵中蓝色单元格表示推理结果与人工标注一致,其余单元格表示存在误差,可用于模型优化参考。
-
点击矩阵里的数值,软件主界面图像列表将自动筛选,只显示点击数值对应的图像。
-
检查训练集和验证集,此外,测试集用于在验证过程中评估模型泛化能力,因此需要重点检查。
-
针对漏检问题,可以补充标注,但需要注意要把整张图像中检出和未检出的数据都进行标注,然后再将整张图像加入训练集重新训练、验证。
-
针对过检问题,多采用后处理方式,即后续在应用模型时通过设置置信度来筛选数据。
-
-
当模型在训练集上无过检、漏检,表明模型已初步具备泛化能力。
不需要把测试集中所有存在漏检或过检的图像都标注后划分为训练集。可补充标注一部分图像,加入训练集,重新训练和验证模型,将剩余图像作为参考,观察验证结果,检验模型迭代效果。 用户也可以点击详细报表窗口右下角的导出报表选择导出缩略图报表或原图报表。 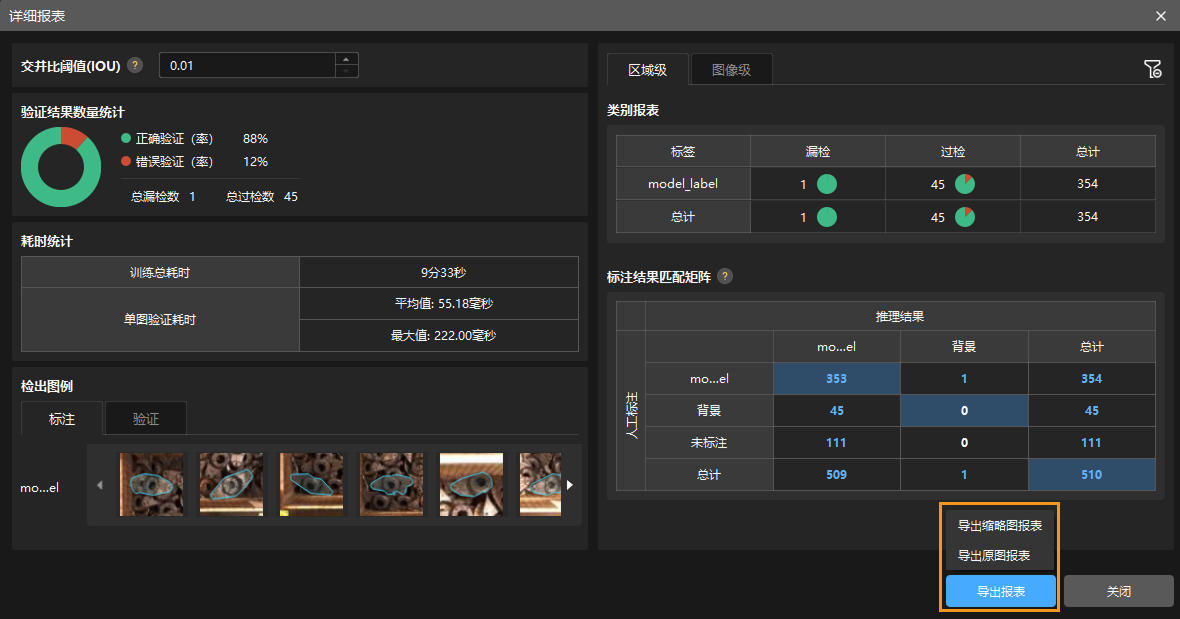
-
-
重新开始训练:将新标注的图像加入训练集后,单击训练按钮,重新开始训练。
-
重新检查模型验证结果:训练结束后,再次点击验证按钮验证模型,重新检查模型在各数据集上的验证结果。
-
模型微调(可选):用户可启用开发者模式,在训练参数设置中启用模型微调。
-
不断优化模型:重复以上步骤,不断优化模型性能,直至模型达到使用要求。