如何训练高质量模型
本节将介绍最影响模型质量的几个因素以及如何训练出高质量文本检测模型。
确保图像质量
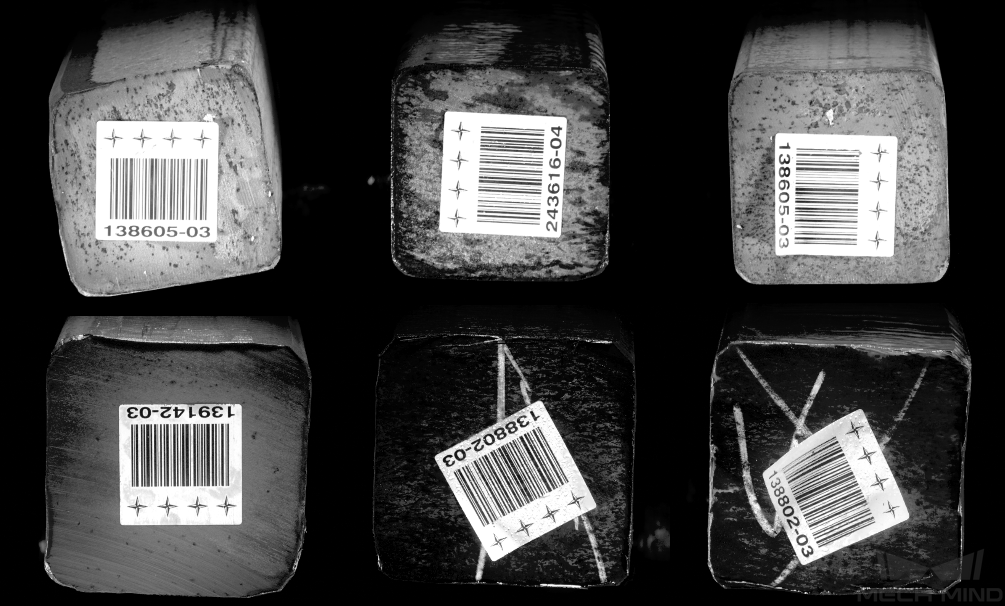
避免 过曝、过暗、模糊、遮挡 等。这些情况会导致深度学习模型所依赖的特征丢失,影响模型训练效果。
| 图像质量差:文本区域有遮挡,不利于文本区域检测,可能会导致后续文本识别不准确。 | |
|---|---|
|
|
优化建议:确保文本区域完整无遮挡。 |
|
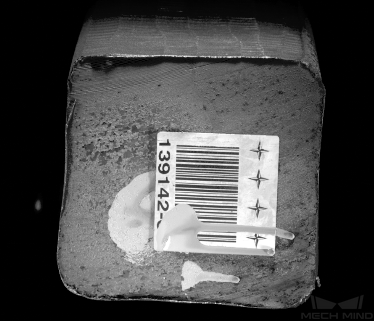

| 图像质量差:过曝 | 图像质量差:过暗 |
|---|---|
|
|
优化建议:建议通过遮光或补光的方式避免。 |
|
本节将介绍最影响模型质量的几个因素以及如何训练出高质量文本检测模型。
避免 过曝、过暗、模糊、遮挡 等。这些情况会导致深度学习模型所依赖的特征丢失,影响模型训练效果。
| 图像质量差:文本区域有遮挡,不利于文本区域检测,可能会导致后续文本识别不准确。 | |
|---|---|
|
|
优化建议:确保文本区域完整无遮挡。 |
|
| 图像质量差:过曝 | 图像质量差:过暗 |
|---|---|
|
|
优化建议:建议通过遮光或补光的方式避免。 |
|