Train a High-Quality Model
This section introduces the factors that most affect the model quality and how to train a high-quality instance segmentation model.
Ensure Image Quality
Single Module
Please pay attention to the following suggestions so as to train a high-quality text recognition model:
-
Avoid overexposure, dimming, blur, occlusion, etc. These conditions can lead to the loss of features that the deep learning model relies on, which will affect the model training effect.
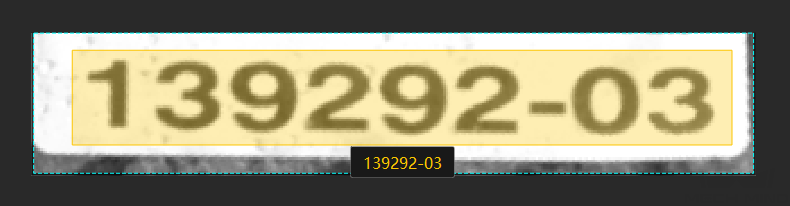
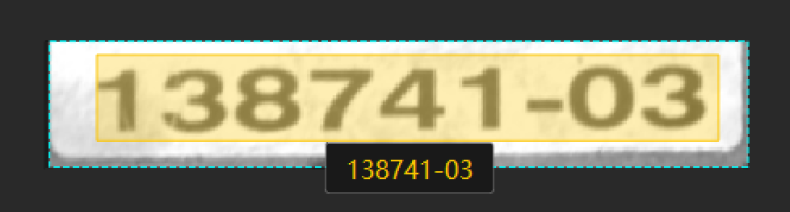
Poor images: The texts in the images are partially occluded, which affects recognition performance. 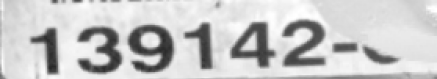

Suggestion: Make sure that the text areas are clear and complete.
Poor image: overexposure Poor image: underexposure 

Suggestion: You can avoid overexposure by methods such as shading and avoid dimming by methods such as supplemental light.
-
The texts in the imported images should be oriented toward the positive direction (0°). If the text orientations vary greatly, it is recommended to add a Text Detection module before this module. When importing data, select and make sure the Rectify image(s) function is enabled to rectify images to 0°.
Cascaded Modules
The Text Detection or Object Detection module can precede the Text Recognition module for better recognition results. Note that the Text Recognition module cannot be followed by any other modules.
-
If a Text Detection module precedes it, select when importing data and make sure the Rectify image(s) function is enabled to rectify images to 0°.
Typically, the Rectify image(s) function reliably carries out its designated task. However, occasionally, few images oriented at 0° may inadvertently undergo rectification to 180°. In such situations, it is advisable to exercise discretion in practical applications. Before rectification After rectification 

Ensure Data Quality
The Text Recognition module can recognize the characters in the selected text area of an image and automatically generate the recognition result. Manual checking is required for the result. The used data should be as consistent with the actual scenarios as possible for the training of a high-quality model.
Select Appropriate Data
-
Control the image quantity of training set
When you first use the Text Recognition module, it is recommended to use 20 to 30 images as a training set for model training. If the validation results are not up to standard, you can then add more data.
-
Balance data proportion
In the training set, the images with different text types should be balanced. Using diverse data can help improve model performance.

-
Reduce inadequate data
High-quality images can ensure better model training. Poor images or irrelevant images may do damage to model training.
| It is not true that the larger the number of images the better. Adding a large number of inadequate images in the early stage is not conducive to model improvement later and will slow down the training process. |
Ensure Labeling Quality
When the Text Recognition Tool is used to make a selection, the recognition result will automatically appear right under the selection frame. Manual verification and confirmation are required. Therefore, making a valid selection and confirming a correct recognition result in time are conducive to improving model quality.