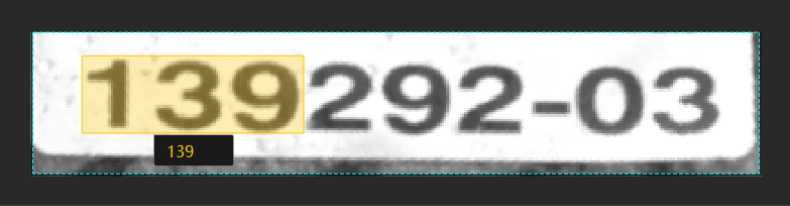
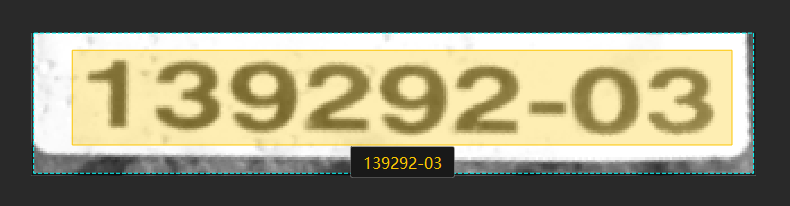
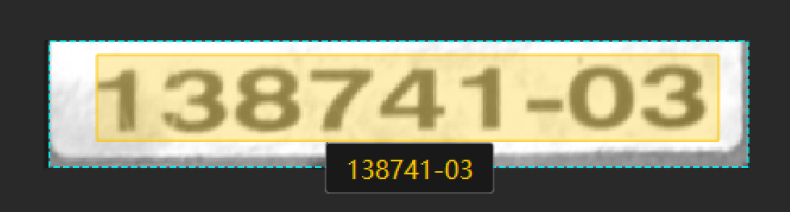
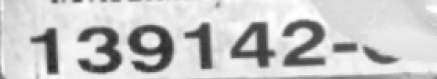如何训练高质量模型 您正在查看V2.5.0版本的文档。如果您想查阅其他版本的文档,可以点击页面右上角“切换版本”按钮进行切换。 ■ 如果您想使用最新版本,可以从梅卡曼德下载中心下载。 ■ 如果您不确定当前使用的产品是哪个版本,请随时联系梅卡曼德技术支持。 本章将介绍最影响模型质量的几个因素,以及如何训练出高质量文本识别模型。 确保图像质量 单级模型 若单独使用“文本识别”模块,为提升模型质量,应注意以下几点: 避免 过曝、过暗、模糊、遮挡 等。这些情况会导致深度学习模型所依赖的特征丢失,影响模型训练效果。 图像质量差:文本区域有遮挡,不利于文本识别。 优化建议:确保文本区域完整无遮挡。 图像质量差:过曝 图像质量差:过暗 优化建议:建议通过遮光或补光的方式避免。 导入图像中,待识别文本应尽量为正方向(0°)。如果文本朝向比较混乱,建议前置“文本检测”模块,选择 导入 从上一模块导入 时,确认“图像校正”功能已开启以校正图像文本区域至正方向(0°)。 级联模型 “文本识别”模块可前置“文本检测”或“目标检测”模块来提升模型效果,其后无法再级联其他模块。 若前置的是“文本检测”模块,选择 导入 从上一模块导入 时,并确认“图像校正”功能已开启(默认开启)。 通常,“图像校正”功能可校正图像至 0°,但也有可能将少数 0° 图像校正至 180°,建议根据实际情况判断是否开启该功能。 校正前 校正后 确保数据质量 “文本识别”模块可识别标注框绘制区域的文本,并自动生成结果,人工校验后可手动确认正确结果。选取的数据应尽量与实际场景情况一致,以训练出高质量模型。 选取合适的数据 训练集数量可控 初次使用“文本识别”模块时,建议使用 20~30 张图像作为训练集,后续可根据验证效果再调整数据。 数据占比均衡 训练集中的图像比例要均衡,采用多样化数据有助于提升模型识别效果。 减少无效数据 采用高质量图像,确保导入的每张图像都能有利于模型训练。添加低质量或不相关数据可能会对模型训练产生负面影响。 数据量并不是越大越好,前期加入大量无效的数据不利于后期的模型改进,同时还会延长模型训练时间。 确保标注质量 使用“文本识别工具”框选文本后,会自动生成识别结果,需人工校验和确认。因此,标注时绘制有效的标注框并及时确定正确的结果有助于提升模型质量。 绘制有效标注框 标注范围不完全会给模型训练带来干扰,影响模型效果。绘制的标注框应包含整个目标文本区域。 错误示例 正确示例 确认正确识别结果 自动识别结果有时是错误的,需要手动更正后再确认。确认错误的识别结果将影响模型识别准确性。 错误示例 正确示例 该页面是否有帮助? 我要反馈 感谢您的支持! 可以通过以下方式反馈意见: 社区 反馈表单 标注工具介绍 非监督分割算法介绍