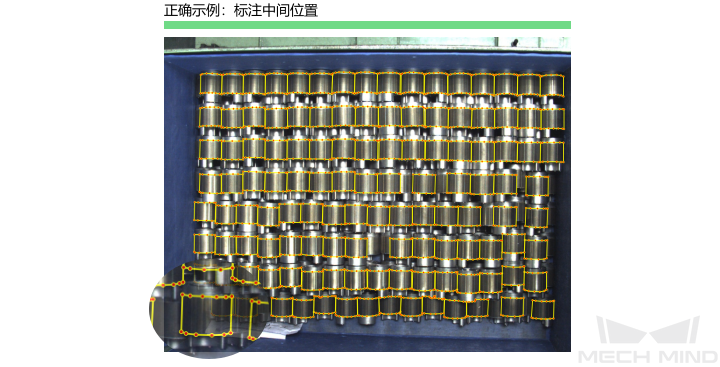
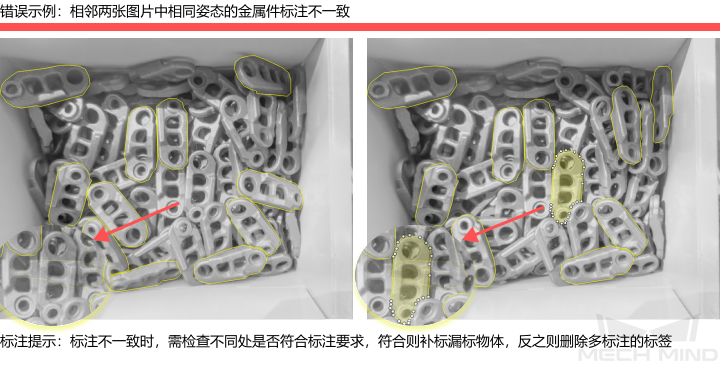
如何训练高质量模型
本章将介绍最影响模型质量的几个因素,以及如何训练出高质量实例分割模型。
确保图像质量
-
避免 过曝、过暗、颜色失真、模糊、遮挡 等。这些情况会导致深度学习模型所依赖的特征丢失,影响模型训练效果。





-
确保采集数据的 背景、视角、高度 与实际应用一致。任何不一致都会降低深度学习在实际应用时的效果,严重情况下必须返工重新采集数据,请务必提前确认实际应用时的情况。



确保数据质量
“实例分割”模块通过学习图像中物体的特征得出模型并应用到实际场景,因此采集和选取的数据集必须与实际场景情况一致才能训练出高质量模型。
采集数据
各种摆放情况均需按采集要求合理分配数量,例如实际生产时来料有横向、竖向和散乱堆叠的情况,但只采集了横向和竖向来料的图像数据进行训练,那么无法保证散乱堆叠的识别效果。因此,采集数据时需要能 包含实际生产的各种场景 ,具体包括:
-
确保采集的数据中包含实际应用所有可能出现的 物体朝向 。
-
确保采集的数据中包含实际应用所有可能出现的 物体位置 。
-
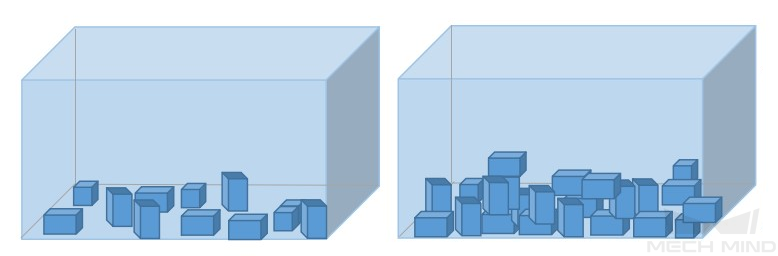
确保采集的数据中包含实际应用所有可能出现的 物体间关系 。
| 如果少采集了某种情况,深度学习模型将会缺少对于该情况的学习,会导致模型在该情况下无法有效识别,必须根据情况增加数据样本,降低误差。 |
物体朝向
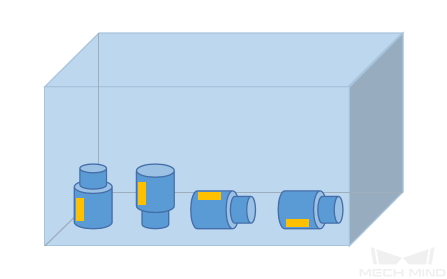
物体位置
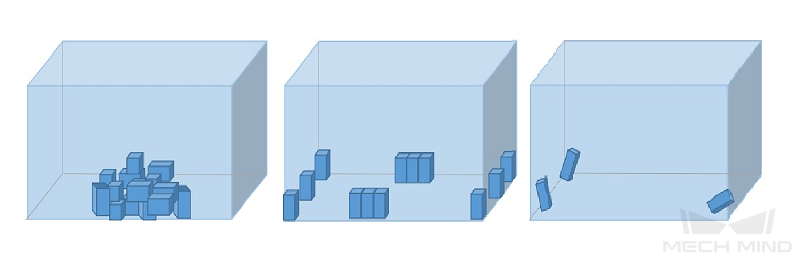
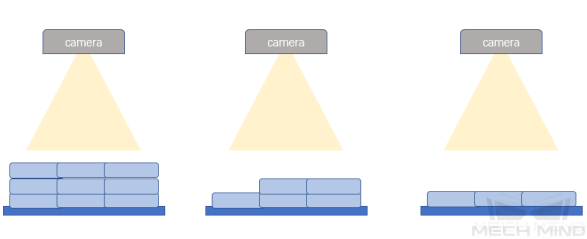
物体间关系

数据采集案例
-
某金属件项目,单类物体,因此采集 50 张。物体朝向方面,可能平躺或侧立,采集时都需要考虑。物体位置方面,需要考虑位于料筐中央、四周、边角以及不同高度的情况。物体间关系方面,除堆叠外还需要考虑少量并排。实际采集的图片如下:


-
某日用品项目,7 类物体混料,需要分类。采集时需考虑“单类物体多种朝向摆放”和“多类物体混合摆放”的情况,以全面地采集物体特征。单类物体采集数量 = 5 * 类别数量,多类物体混合摆放采集数量 = 20 * 类别数量。物体朝向方面,可能平躺、侧立或倾斜,采集时每个面都需要考虑。物体位置方面,需要考虑位于料筐中央、四周、边角。物体间关系方面,除堆叠外还需要考虑并排与紧密拼接情况。实际采集的图片如下:
-
单独摆放

-
混合摆放

-
-
某履带板项目,物体有多个型号,因此采集(30 * 型号数量)张。物体朝向方面,只需考虑正面向上摆放。物体位置方面,摆放方式单一,需包含考虑高、中、低层不同高度视野的数据。物体间关系方面,规则码放,需重点注意紧密贴合的情况。实际采集图片如下:

-
某金属件项目,仅平铺一层,因此采集 50 张。物体朝向方面,仅平铺一层,只需考虑正面向上摆放。物体位置方面,需考虑到位于料筐中央、四周、边角。物体间关系方面,需考虑紧密贴合等,实际采集图片如下:

-
某金属件项目,多层整齐码放,采集 30 张。物体朝向方面,只需考虑正面向上摆放。物体位置方面,需考虑到位于料筐中央、四周、边角以及高、中、低层不同高度的情况。物体间关系方面,需考虑紧密贴合等,实际采集图片如下:

选取合适的数据
-
训练集数量可控
对于“实例分割”模块初次建模,建议使用 30~50 张图像。数据量并不是越大越好,前期加入大量无效的数据不利于后期的模型改进,同时还会延长训练时间。
-
数据具有代表性
图像一定要涵盖待检测目标的所有光照、颜色、尺寸等信息。
-
光照:实际存在光照变化,数据应该包含不用光照情况下的图像。
-
颜色:工件存在不同颜色,数据应该包含所有颜色的图像。
-
尺寸:工件存在不同尺寸,数据应该包含所有不同大小尺寸的图像。
若实际现场工件会出现旋转、缩放、或其他情况,无法采集相应图像数据时,可以通过调整数据增强训练参数的方式来补充数据,以确保现场所有的情况都包含在训练集内。
-
-
数据占比均衡
训练集中不同种类的图像比例要均衡,否则会影响模型效果。禁止出现一种物体 20 张,另一种物体仅有3张的情况。
-
数据与终端场景保持一致
图像要与最终模型使用的终端场景保持一致,包括光照条件、工件特征、检测背景、视野大小等。