프로젝트 상세 설명¶
프로젝트 프로세스¶
빈에 물건이 배치되어 있을 때 빈 안의 물건의 상대적인 위치를 보다 정확하게 구별하기 위해 먼저 가장 높은 층의 포인트 클라우드를 획득하는 방식으로 빈의 포즈를 얻을 수 있습니다.
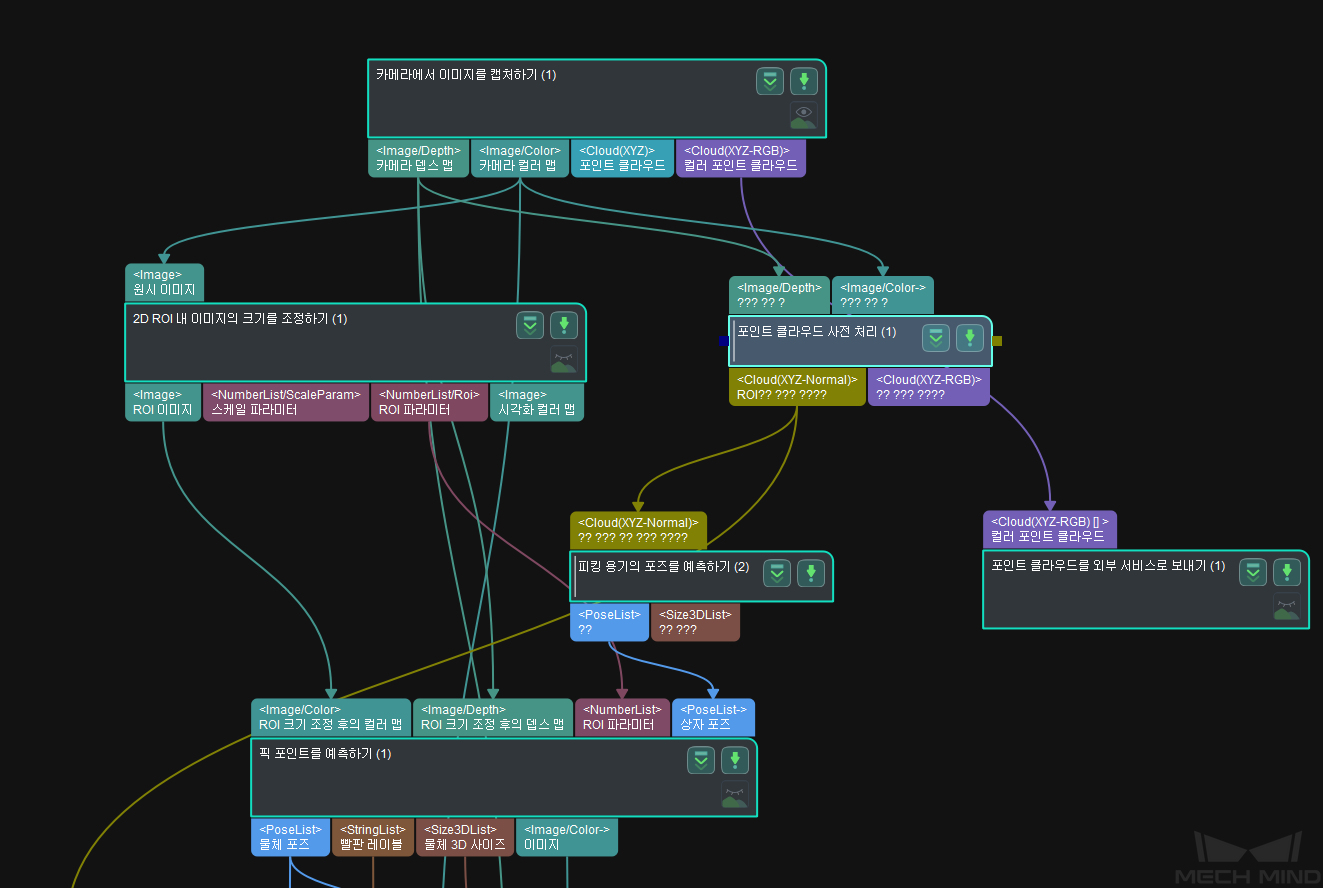
임의의 물체 피킹 프로젝트의 비전 프로세스는 아래 그림과 같습니다.

이 프로젝트의 스크린샷은 아래 그림과 같습니다.
관련된 스텝에 대한 자세한 설명¶
카메라에서 이미지를 캡처하기¶
이 스텝은 Mech-Vision과 카메라 간의 통신을 구현하는 데 사용됩니다. 이 스텝을 통해 시나리오의 뎁스 맵, 컬러 맵 및 포인트 클라우드를 획득하여 후속 비전 계산을 위한 데이터를 제공할 수 있습니다.
이 스텝에 대한 자세한 내용은 카메라에서 이미지를 캡처하기 를 참조하세요.
포인트 클라우드 사전 처리¶
후속 스텝의 처리 시간을 단축하기 위해 원시 포인트 클라우드는 사전 처리됩니다. 이 프로시저에서 뎁스 맵과 컬러 맵을 사용하여 포인트 클라우드를 생성한 다음 포인트 클라우드의 법선 방향을 계산하고 이상치와 노이즈를 삭제하고 마지막으로 관심 영역 내의 포인트 클라우드를 추출합니다.
이 프로시저의 자세한 내용은 :포인트 클라우드 사전 처리 를 참조하십시오.
포인트 클라우드 사전 처리 결과는 아래 그림과 같습니다.

2D ROI 내의 이미지 크기를 조정하기¶
이 스텝은 관심 있는 이미지 영역을 지정된 크기로 조정하는 데 사용됩니다. 물체의 포즈 예측 결과는 관심 영역과 크기 조정 비율에 크게 영향을 받으므로 더 나은 포즈 결과를 얻으려면 관심 영역과 크기 조정 비율을 잘 조정해야 합니다.
자세한 조정 방법은 :深度学习部署ROI设置 을 참조하세요.
빈의 포즈 예측¶
빈의 포즈를 계산하기 위해 빈의 상단 가장자리 포인트 클라우드를 얻습니다. 이 프로시저에서 먼저 포인트 클라우드의 크기를 줄이기 위해 샘플링한 다음 지정된 규칙에 따라 포인트 클라우드를 클러스터링하여 가장 높은 층의 포인트 클라우드를 획득하고 마지막으로 평면 포인트 클라우드를 계산하고 Z축을 뒤집어서 빈의 포즈를 출력합니다.
빈의 포즈는 아래 그림과 같습니다.

임의의 물체 피킹 포즈 예측¶
물체의 유형과 모양이 불확실하기 때문에 딥 러닝 방법을 사용하여 픽 포인트를 예측합니다. 사용할 스텝은 픽 포인트를 예측하기(임의의 물체) 입니다.
컬러 맵, 뎁스 맵, ROI 파라미터 및 상자의 포즈를 입력한 후 딥 러닝 알고리즘을 사용하여 다음을 얻을 수 있습니다. 카메라 좌표계에서 피킹 가능한 물체의 표면 포즈(아래 그림 참조), 피킹 가능한 물체의 3D 치수, 피킹 가능한 물체 표면과 대응하는 빨판 레이블.
참고
빈 포즈를 입력하는 것은 상자에 있는 물체의 상대적인 위치를 보다 정확하게 구별하기 위한 것입니다.

이 스텝에서 영역 레이블이 표시된 이미지도 실시간으로 표시할 수 있으며 사용자는 시각화 파라미터에서 표시 유형을 변경할 수 있으므로 사용자가 인식된 물체를 관찰하는 데 편리합니다. 빨판의 크기에 따라 감지 영역을 표시하면 아래 그림과 같은 효과가 나타납니다.

참고
시각화를 켜면 프로젝트의 전체 실행 속도가 느려집니다.
픽 포인트를 예측하기(임의의 물체) 를 참조해 이 스텝에 대해 자세히 알아보십시오.