プロジェクトの詳細な説明¶
プロジェクトプロセス¶
箱に置かれた物体の位置を正確に認識するために、まず、最高層の点群を取得して箱の位置姿勢を取得します。
対象物吸着のプロジェクトプロセスを下図に示します。
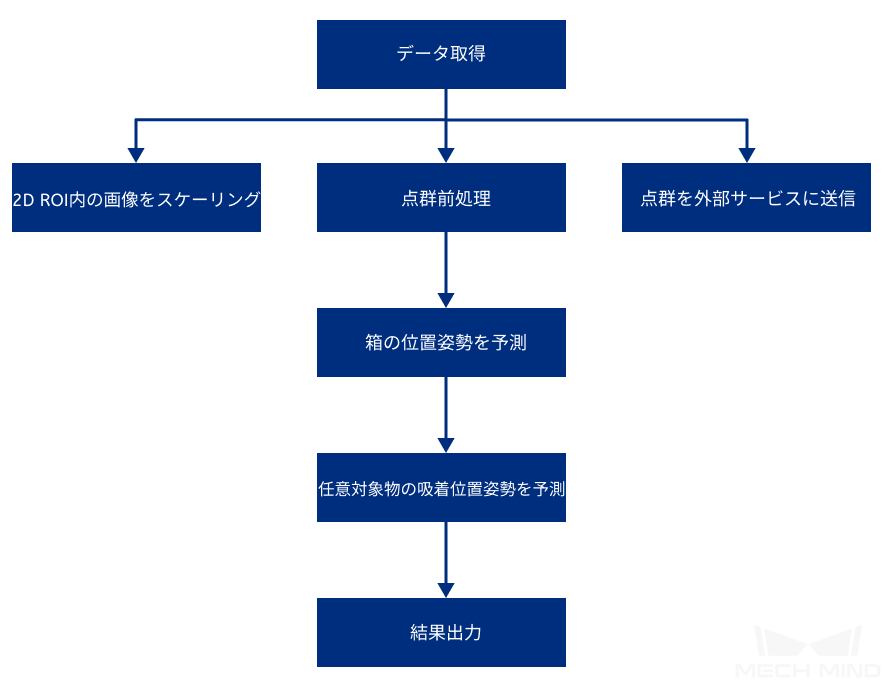
このプロジェクト画面は次の通りです。
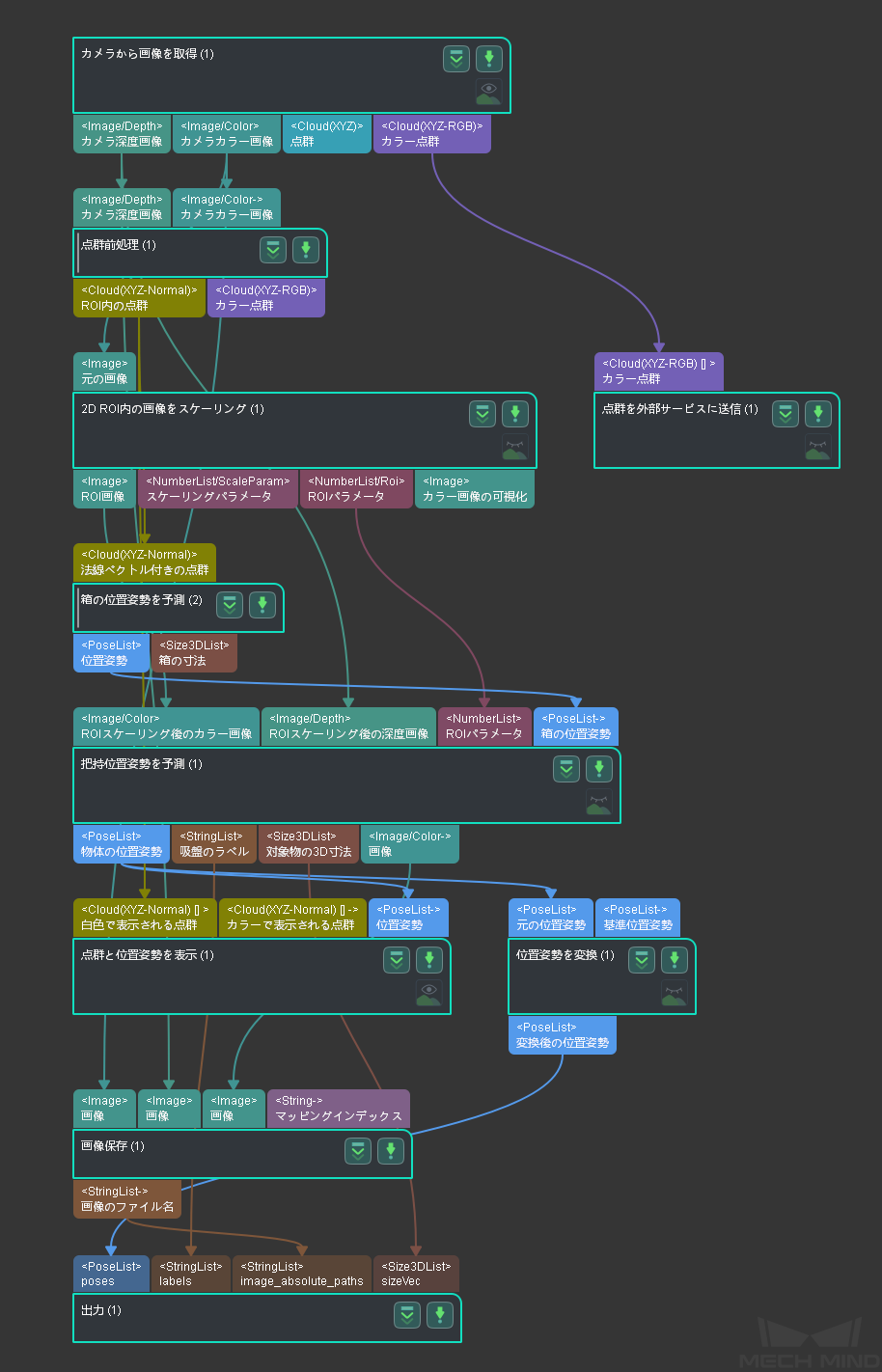
関連ステップ¶
カメラから画像を取得¶
このステップは、Mech-Visionとカメラを通信するために使用されます。これにより、シーンの深度画像、カラー画像および点群を取得し、その後の視覚計算に必要なデータを提供します。
詳細については、 カメラから画像を取得 をご参照ください。
点群前処理¶
元の点群を前処理すれば、後続のステップに使う時間を短縮できます。このステップの組合せでは、深度画像とカラー画像から点群を生成し、点群の法線ベクトルを計算し、外れ値とノイズを削除してROI内の点群を抽出します。
詳細については、 点群前処理 をご参照ください。
点群前処理の結果を下図に示します。

2D ROI内の画像をスケーリング¶
このステップは、画像内のROIを指定されたサイズにスケーリングするために使用されます。物体の位置姿勢の予測結果は、ROIとスケール比率に大きく影響されるので、正確な位置姿勢を取得するために、ROIとスケール比率を適切に調整してください。
ROIの設定については、 ROI 設定 をご参照ください。
箱の位置姿勢を推定¶
箱の上端点群を取得してボックスの位置姿勢を計算します。このステップの組合せでは、最初に点群をサンプリングして点群のサイズを縮小し、次に指定されたルールに従って点群をクラスタリングして最高層の点群を取得します。最後に平面点群の位置姿勢とサイズを計算し、Z軸を反転して箱の位置姿勢を出力します。
箱の位置姿勢を下図に示します。

任意対象物の吸着位置姿勢を予測¶
物体は多種類があって、形状も異なるので対応するモデルはないため、ディープラーニングアルゴリズムを備えた 把持位置姿勢を予測(複数タイプ) ステップを使用して把持位置姿勢を予測します。
カラー画像、深度画像、ROIパラメータ及び箱の位置姿勢を入力した後、ディープラーニングアルゴリズムにより、カメラ座標系における吸着可能な物体表面位置姿勢(下図に示すように)、吸着可能な物体の3D寸法、吸着可能な物体表面に対応する吸盤ラベルを取得できます。
注釈
箱の位置姿勢を入力すると、箱の物体の相対位置をより正確に区別できます。

さらに、このステップでは、領域ラベルでマークされた画像もリアルタイムで表示でき、可視化パラメータで表示タイプを変更できます。吸盤の大きさに合わせて検出エリアを表示すると、下図のような効果になります。

注釈
可視化を有効にすると、プロジェクトの全体的な実行速度が低下します。
詳細については、 把持位置姿勢を予測(複数タイプ) をご参照ください。