종이 상자 인식
이 부분을 시작하기 전에 "핸드-아이 캘리브레이션" 장에서 “동일한 종류의 상자” 샘플 프로젝트를 사용하여 Mech-Vision 프로젝트를 만들어야 합니다.
이 부분에서는 먼저 프로젝트 설계를 이해한 다음 스텝 파라미터를 조정을 통해 프로젝트 배포를 완료하여 종이 상자의 포즈를 인식하고 비전 결과를 출력할 것입니다.
프로젝트 설계 소개
프로젝트의 각 프로시저의 기능은 아래의 표와 같습니다.
| 번호 | 스텝/프로시저 | 예시 그림 | 기능 설명 |
|---|---|---|---|
1 |
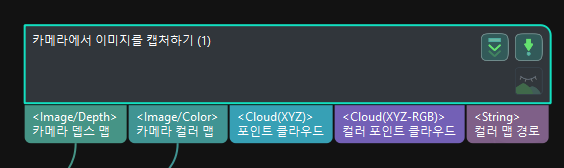
카메라에서 이미지를 캡처하기 |
|
카메라 연결 및 이미지 캡처합니다. |
2 |
포인트 클라우드 사전 처리 및 최상층 포인트 클라우드를 얻기 |
|
종이 상자의 포인트 클라우드에 대해 사전 처리하고 최상층 포인트 클라우드를 얻습니다. |
3 |
딥 러닝을 통해 단일 종이 상자의 마스크를 세그먼테이션하기 |
|
단일 종이 상자의 마스크를 이용하여 해당 포인트 클라우드를 얻을 수 있기 위해 입력한 최상층 종이 상자 마스크에 따라 딥 러닝을 사용하여 해당 영역의 단일 종이 상자 마스크를 추론합니다. |
4 |
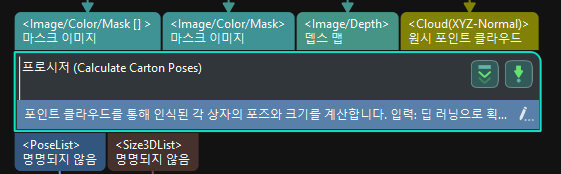
상자 포즈를 계산하기 |
|
종이 상자 포즈를 인식하고 입력한 종이 상자의 치수 정보에 의해 인식 결과를 확인하거나 조정합니다. |
5 |
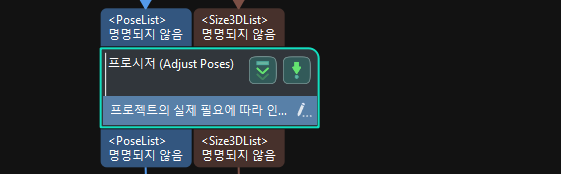
포즈 조정 |
|
종이 상자 포즈의 좌표계를 변환하고 여러 상자의 포즈를 행과 열로 정렬합니다. |
6 |
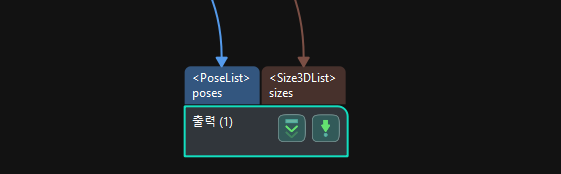
출력 |
|
종이 상자의 포즈를 출력하여 로봇 피킹에 사용합니다. |


파라미터 조절에 대한 설명
이 부분에서는 각 스텝이나 프로시저의 파라미터를 조정하여 프로젝트 배포를 완료할 것입니다.
카메라에서 이미지를 캡처하기
“동일한 종류의 상자” 샘플 프로젝트에 가상 데이터가 배치되어 있기 때문에 먼저 “카메라에서 이미지를 캡처하기” 스텝의 가상 모드를 닫아야 실제 카메라와 연결됩니다.
-
"카메라에서 이미지를 캡처하기" 스텝을 선택하고 인터페이스의 오른쪽 하단 모서리에 있는 스텝 파라미터에서 가상 모드를 닫고 카메라를 선택하기를 클릭합니다.
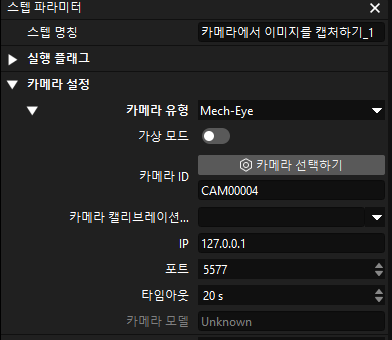
-
팝업창에서 연결할 카메라 번호 우측의
 버튼을 클릭하면 카메라와 연결됩니다. 카메라가 성공적으로 연결되면 버튼이
버튼을 클릭하면 카메라와 연결됩니다. 카메라가 성공적으로 연결되면 버튼이  로 변경됩니다.
로 변경됩니다.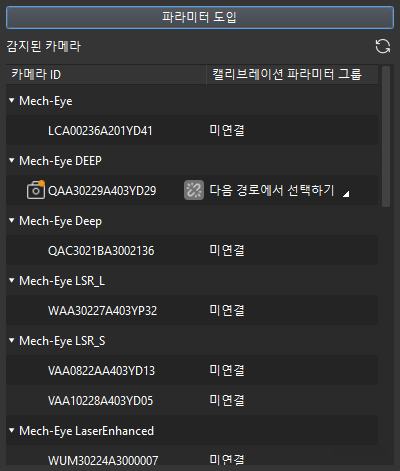
카메라와 연결된 후 파라미터 그룹을 선택하기를 클릭하여 캘리브레이션한 파라미터 그룹을 선택합니다.
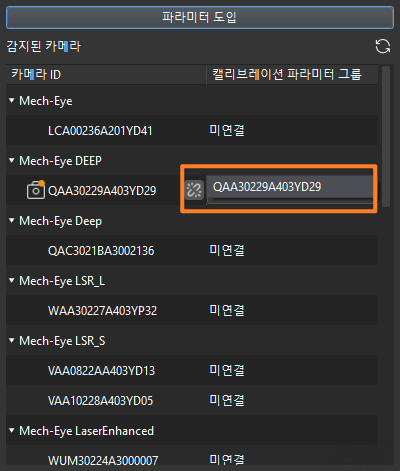
-
카메라를 연결하고 파라미터 그룹을 설정하면 카메라 캘리브레이션 파라미터 그룹, IP 주소 및 포트와 같은 파라미터가 자동으로 획득되며 나머지 파라미터는 기본값으로 유지하면 됩니다.
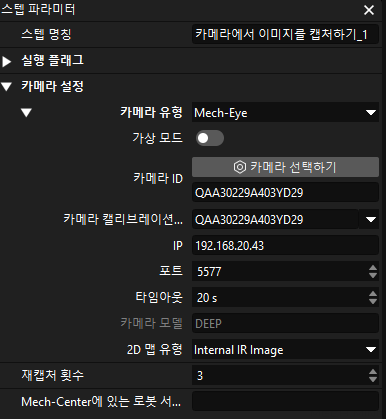
이로써 카메라 연결이 완료되었습니다.
포인트 클라우드 사전 처리 및 최상층 포인트 클라우드를 얻기
최상층이 아닌 종이 상자를 피킹해서 로봇이 다른 상자와 충돌하는 것을 피하기 위해 이 프로시저에서 최상층 종이 상자의 포인트 클라우드를 얻어 로봇이 우선적으로 최상층 상자를 피킹하는 것을 가이드해야 합니다.
이 프로시저에서 3D ROI와 층 높이를 조정해야 합니다.
-
인터페이스 오른쪽 하단에 있는 스텝 파라미터에서 3D ROI 설정 버튼을 클릭하여 3D ROI를 설정합니다.
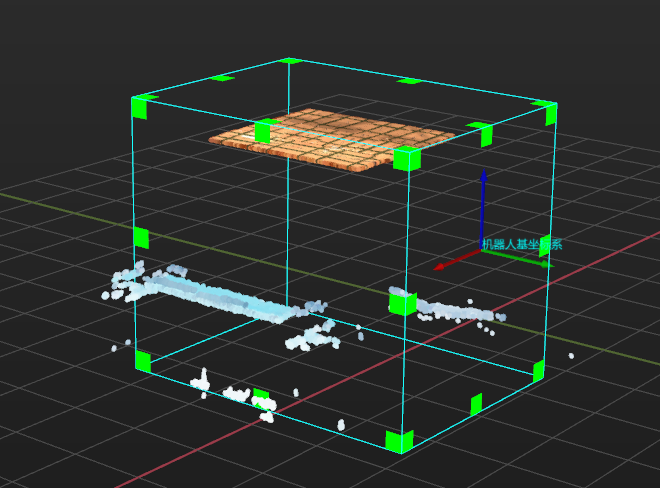
종이 상자 스택의 가장 높은 영역과 가장 낮은 영역을 포함하도록 3D ROI를 설정하며 3D ROI 내의 불필요한 포인트 클라우드를 제거하십시오.
-
아래 층 종이 상자의 포인트 클라우드를 얻지 않기 위해 층 높이 파라미터를 설정합니다. 층 높이는 스택의 개별 상자 높이 값보다 낮게 설정해야 합니다(예: 상자 높이의 절반). 일반적으로 권장 값을 사용합니다.
다른 종이 상자 스택에 있는 상자 사이즈가 현장에서 다른 경우 가장 낮은 상자의 높이에 따라 층 높이 파라미터를 설정해야 합니다.
층 높이 파라미터 값이 적절하게 설정되지 않은 경우 가장 높지 않은 상자의 포인트 클라우드를 얻게 되어 로봇이 피킹할 때 다른 상자와 충돌할 수 있습니다.
딥 러닝을 통해 단일 종이 상자의 마스크를 세그먼테이션하기
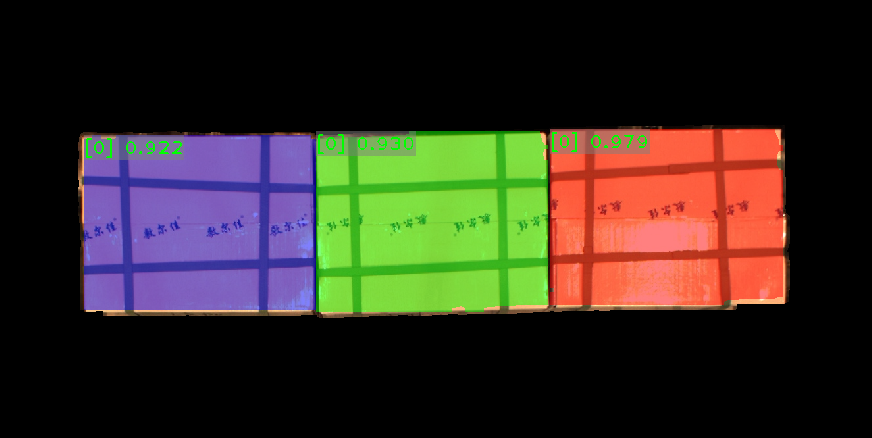
최상층 상자의 포인트 클라우드를 얻은 후에는 딥 러닝을 통해 단일 종이 상자의 마스크를 세그먼테이션합니다.
현재 샘플 프로젝트에는 종이 상자의 일반적인 인스턴스 세그먼테이션 모델 패키지가 내장되어 있습니다. 아래 그림과 같이 이 프로시저를 실행하여 단일 상자의 마스크를 얻습니다.
|
세그먼테이션 효과가 충분하지 않은 경우 3D ROI의 크기를 적절하게 조정할 수 있습니다. |
상자 포즈를 계산하기
단일 상자의 포인트 클라우드를 얻은 후 상자의 포즈를 계산할 수 있습니다. 이 밖에 입력한 상자의 치수를 통해 비전 인식 결과의 정확성를 확인할 수 있습니다.
“상자 포즈를 계산하기” 프로시저에서 X、Y、Z축에 있는 길이와 상자 치수 허용 편차를 설정합니다.
-
X、Y、Z축에 있는 길이: 실제 종이 상자의 치수에 따라 이 파라미터를 설정합니다.
-
상자 치수 허용 편차: 기본 값인 30 mm를 유지하면 됩니다. 입력한 상자의 치수가 인식된 치수와 큰 차이가 있는 경우 이 파라미터를 조정할 수 있습니다.
포즈 조정
종이 상자의 포즈를 얻은 후 로봇이 정상적으로 피킹하도록 상자 포즈를 카메라 좌표계에서 로봇 좌표계로 변환해야 합니다.
이 프로시저에서 로봇이 순서대로 피킹하도록 종이 상자의 포즈를 행과 열로 정렬할 수 있습니다.
-
오름차순 배열(로봇 베이스 좌표계 기준으로 상자 포즈의 X값): 일반적으로 기본 설정을 유지합니다(선택됨). 이 옵션을 선택하면 행은 로봇 베이스 좌표계 기준으로의 상자 포즈 X값대로 오름차순으로 배열하고 이 옵션을 선택하지 않으면 내림차순으로 배열합니다.
-
오름차순 배열(로봇 베이스 좌표계 기준으로 상자 포즈의 Y값): 일반적으로 기본 설정을 유지합니다(선택됨). 이 옵션을 선택하면 행은 로봇 베이스 좌표계 기준으로의 상자 포즈 Y값대로 오름차순으로 배열하고 이 옵션을 선택하지 않으면 내림차순으로 배열합니다.