任意物体吸取工程详解¶
Mech-Vision工程流程¶
物体放置于料筐之中,为了更准确区分物体在料筐内的相对位置,首先可以通过获取最高层点云的方式得到料筐的位姿。
任意物体吸取工程的视觉流程如图1所示。
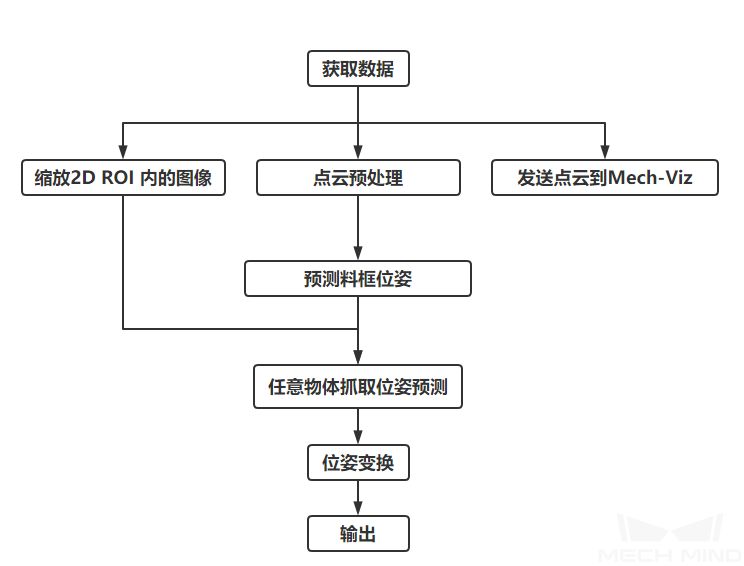
图1 任意物体吸取工程流程¶
图2为该工程截图。
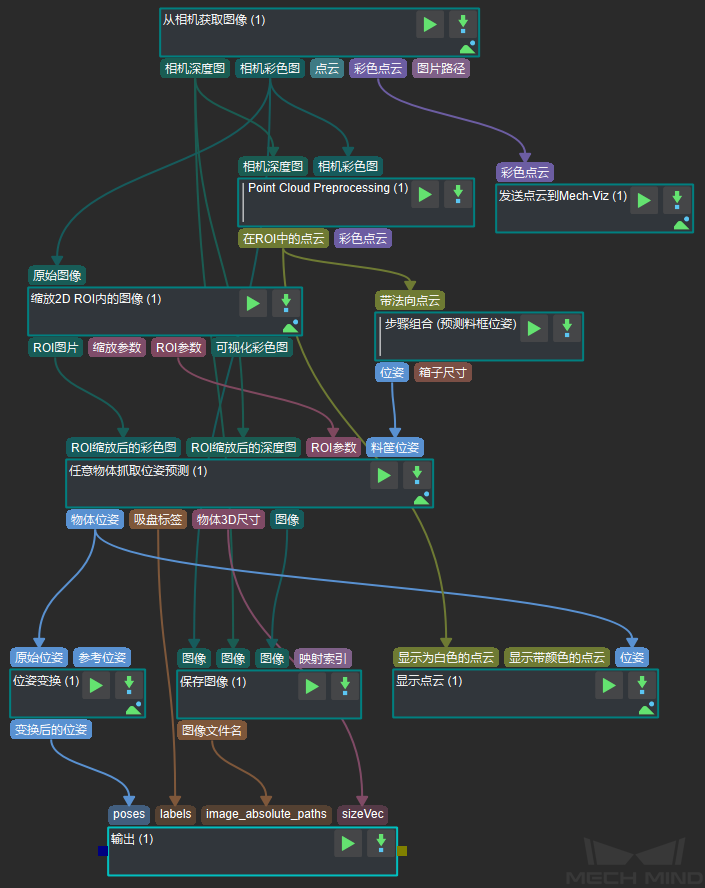
图2 工程截图¶
相关步骤详解¶
点云预处理¶

缩放2D ROI 内的图像¶
该步骤用于将图片感兴趣区域缩放至指定尺寸。预测物体位姿的结果很大程度上受感兴趣区域及缩放比例的影响,若想获得较理想的位姿结果,必须调整好感兴趣区域及缩放比例。
具体调节方法请参考:深度学习部署ROI设置 。
预测料筐位姿¶
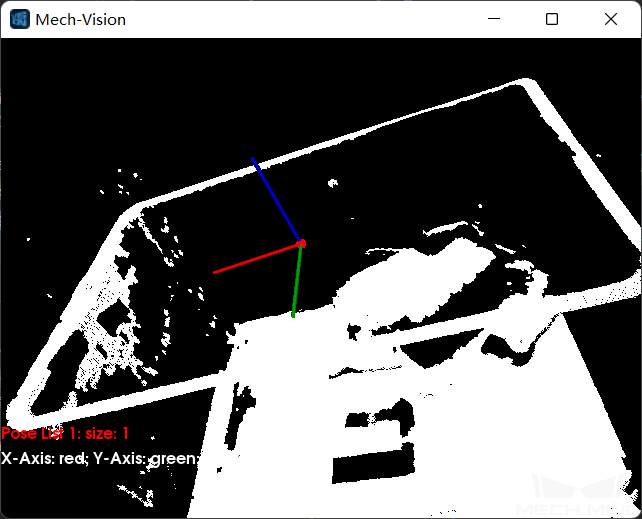
任意物体抓取位姿预测¶
由于物体种类不定、形状各异,所以使用深度学习方法来预测抓取点。 运行此步骤前需在该步骤属性中加载经过深度学习训练后的模型文件、配置文件、位姿估计模型文件、压叠检测模型文件与配置文件。
输入彩色图、深度图、ROI参数及料筐位姿后,利用深度学习算法可得到:相机坐标系下的物体可吸取表面位姿(如图5所示)、可吸物体3D空间尺寸、可吸物体表面对应的吸盘标签。
注解
输入料筐位姿是为了更准确区分物体在料筐内的相对位置。

图5 抓取位姿预测结果¶
该步骤还可以实时显示标记了区域标签的图片,方便用户观察所识别的物体。 按吸盘大小显示检测区域的图片如图6所示。 用户在可视化属性中可更改显示类型。
注解
开启可视化会降低工程整体运行速度。
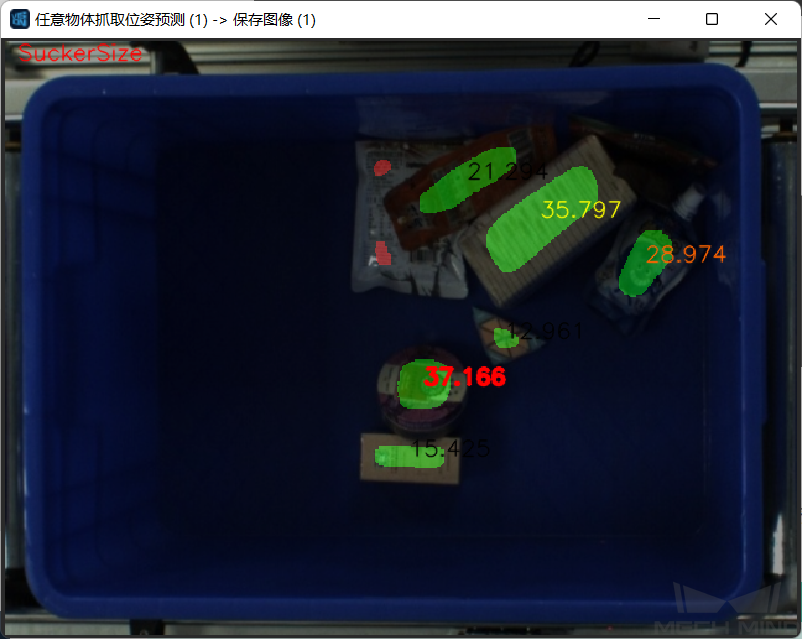
图6 按吸盘大小显示¶