Details of the Project¶
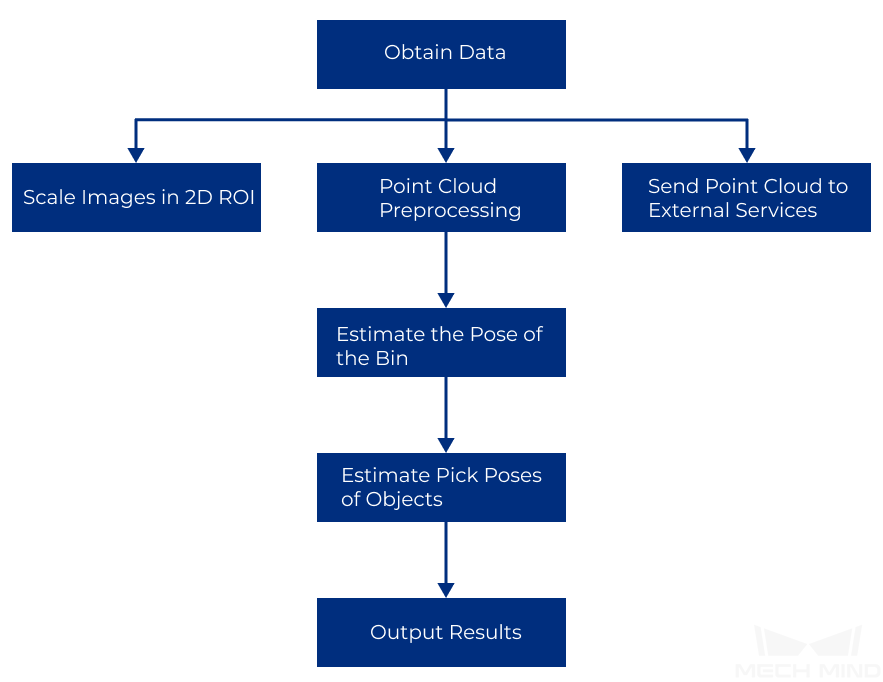
Project Workflow¶
In this project, all objects are placed in a bin. In order to determine the relative positions of objects in the bin, the pose of the bin can be obtained first with the Get Highest Layer Clouds Step.
The vision result processing framework of a Pick Anything project is shown below.
The project screenshot is shown below.

Explanation of the Steps¶
Capture Images from Camera¶
This Step is used to enable communictaion between Mech-Vision and the camera. You can obtain depth maps, color images, and point clouds from this Step and use these data for further computation to obtain the final vision results.
Please refer to Capture Images from Camera for detailed infomation of this Step.
Point Cloud Preprocessing¶
This Procedure is used to preprocess original point clouds and therefore reduce the processing time in subsequent Steps. This Procedure generates point clouds from depth maps and color images first, and calculates normals of point clouds. Then it removes the outliers, and extract point clouds in the ROI at last.
Please refer to Point Cloud Preprocessing for detailed infomation of this Procedure.
The result of point cloud preprocessing is shown below.

Scale Image in 2D ROI¶
This Step is used to scale the ROI in an image to a specified size. The prediction result of the object pose is largely influenced by the ROI and the scaling ratio. Proper ROI and scaling ratio are necessary to obtain the desired pose results.
Please refer to Deep Learning Deployment ROI Settings for detailed instructions.
Estimate the Pose of the Bin¶
The pose of the bin can be estimated from the point clouds of the bin’s top edges. This Procesure down-samples the point clouds first to reduce their sizes, and then clusters point clouds according to the specified rule. Then it obtains the point cloud on the highest layer, and computes the pose and size of the planar point cloud and outputs the pose of the bin after flipping the Z axis.
The pose of the bin is shown below.

Predict Pick Points (Any Objects)¶
Since the objects to be picked are of different types and shapes, deep learning algorithms are utilized to estimate pick points. The Step used here is Predict Pick Points (Any Object).
After inputing color images, depth maps, ROI parameters, and the bin pose, with the assistance of deep learning algorithm, you can obtain pick points on the object in the camera reference frame (as shown below), dimensions of the pickable objects, and the corresponding suction cup label.
Note
The bin pose is used to determine relative positions of objects more precisely in the bin.

This Step can also be used to visualize the labeled regions of pickable objects in real time. You can modify the visualization type in the visualization parameters. The figure below is an example of setting Show Suction Cup Diameter as the Visualization Type.

Note
Enabling visualization may slow down the execution speed of the project.
Please refer to Predict Pick Points (Any Object) for detailed infomation of this Step.