深度学习模型包管理工具¶
本文介绍深度学习模型包管理工具的使用方法和注意事项。
工具介绍¶
深度学习模型包管理工具是 Mech-Vision 软件提供的管理深度学习模型包的工具,可对 Mech-DLK 2.2.0 及之后版本导出的深度学习模型包(单级模型包或级联模型包)进行优化,并对运行模式、硬件类型、模型效率、模型包状态进行管理。此外,该工具还可以监控工控机的 GPU 使用率。
当工程中使用深度学习相关步骤时,可将模型包先导入到深度学习模型包管理工具,然后在深度学习相关步骤中使用。将模型包提前导入该工具,可提前完成模型包的优化。
注解
自 Mech-DLK 2.4.1 开始,模型包分为单级模型包、级联模型包两种。
单级模型包:模型包中有且只有一个深度学习算法模块的模型,例如“实例分割”模型。
级联模型包:模型包中有多个深度学习算法模块的模型,以串联形式存在,上一模型的输出是下一模型的输入。例如,当模型包中存在“目标检测”、“实例分割”两个模型时,模型推理顺序为 ,“目标检测”模型的输出将作为“实例分割”模型的输入。
界面介绍¶
该工具可通过以下两种方式打开:
依次单击菜单栏中 。
在工程中,选中“深度学习模型包推理”步骤,然后在步骤参数中单击 模型包管理工具 按钮。
下表介绍了深度学习模型包管理工具界面中的各选项字段。
字段名 |
介绍 |
缓存模型包名称 |
可查看导入的模型包名称 |
使用工程 |
可查看使用模型包的 Mech-Vision 工程 |
模型包类型 |
可查看模型包的类型,如“目标检测”(单级模型包)、“目标检测+缺陷分割”(级联模型包) |
运行模式 |
可选择模型包推理的运行模式,包括“共享模式”和“性能模式” |
硬件类型 |
可查看、更改模型包推理使用的硬件的类型,如 GPU(默认)、GPU(优化)、CPU |
模型效率 |
可对模型包推理效率进行配置 |
模型包状态 |
可查看模型包的状态,如“优化中”、“就绪” 、“优化失败” |
注解
运行模式
共享模式:选择该选项后,多个步骤使用同一模型包时,将排队推理,可节省更多运行资源。
性能模式:选择该选项后,多个步骤使用同一模型包时,将并行推理,可提高运行速度,但会消耗更多运行资源。
硬件类型
CPU:使用 CPU 进行模型包推理,与 GPU 相比,推理时间会增加,并且识别精度会有所降低。
GPU(默认):选择该选项后,无需根据硬件设备对模型包进行优化,模型包推理将不会被提速。
GPU(优化):选择该选项后,将根据硬件设备对模型包进行优化,此过程仅需一次,预计耗时 5~15 分钟,优化后的模型包推理时间将缩短。
操作指南¶
本节介绍深度学习模型包管理工具的常用操作。
导入深度学习模型包¶
打开深度学习模型包管理工具,在其界面左上角处单击 导入模型包 。
在弹出的文件选择窗口中选中想要导入的模型包,然后单击打开,该模型包即可出现在深度学习模型包管理工具的列表中,此时即完成了深度学习模型包的导入。
注意
导入深度学习模型包时,GPU 驱动的最低版本要求为 472.50(不建议使用 500 以上版本的 GPU 驱动,可能导致深度学习步骤运行时间存在波动),CPU 的最低要求为英特尔第 6 代 Core。当硬件条件不满足时将出现深度学习模型包导入失败的情况。

注销深度学习模型包¶
如需注销已导入的深度学习模型包,需先选中该模型包,然后单击深度学习模型包管理工具右上角的 注销模型包 按钮,即可注销该深度学习模型包。
注意
当深度学习模型包处于 优化中 或 正在使用 (使用该深度学习模型包的工程正在运行)时,该深度学习模型包不能被注销。
切换深度学习模型包推理的运行模式¶
如需切换深度学习模型包推理的运行模式,可在深度学习模型包管理工具的 运行模式 字段下单击 ![]() 按钮,然后选择 共享模式 或 性能模式 。
按钮,然后选择 共享模式 或 性能模式 。

注意
当模型包的优化状态为 优化中 或 正在使用 (使用该模型包的工程正在运行)时,无法切换 运行模式 。
当模型包的运行模式为 共享模式 时,无法在 深度学习模型包推理 步骤参数中切换 GPU ID 。
切换深度学习模型包推理的硬件类型¶
深度学习模型包推理的硬件类型可切换至 GPU(默认)、GPU(优化)或 CPU。
在深度学习模型包管理工具的 硬件类型 字段下单击 ![]() 按钮,然后选择 GPU(默认) 、GPU(优化) 或 CPU。
按钮,然后选择 GPU(默认) 、GPU(优化) 或 CPU。

注意
仅 Mech-DLK 2.4.1 及之后版本导出的模型包支持 CPU、GPU 的切换。
下列导入的模型包不支持使用 GPU(默认) 硬件类型:
Mech-DLK 2.2.0 导出的实例分割以及实例分割超级模型包。
Mech-DLK 导出的仅包含 .dlkmt 文件的模型包。
当模型包的优化状态为 优化中 或 正在使用 (使用该模型包的工程正在运行)时,无法切换 硬件类型 。
配置模型效率¶
当使用 Mech-DLK 2.4.1 及之后版本导出的模型包时,可配置模型效率,方法如下。
导入深度学习模型包。
单击“模型效率”下方的 配置 按钮,弹出模型效率配置窗口,对“批量大小”和“精度”进行配置。
模型运行效率受“批量大小”和“精度”参数影响。
批量大小:模型推理时,一次性送入神经网络的图像数量,范围为 1~128。增大该值可以加快模型推理速度,但会占用较多显存。当该值设置不合理时,将导致推理速度变慢。实例分割模型不支持设置“批量大小”,“批量大小”必须为 1。
精度(仅“硬件类型”为“GPU 优化”时可开启):FP32:模型精度高,推理速度较慢;FP16:模型精度低,推理速度较快。
提示
建议“批量大小”的取值与实际送入神经网络的图像数量保持一致。
当设置的“批量大小”远大于实际送入神经网络的图像数量时,将浪费部分资源,导致推理速度变慢。
例如:图像数量为 26,“批量大小”设置为 20,此时将分两次进行推理,第一次送入 20 张图像至神经网络,第二次送入 6 张图像至神经网络。第二次推理时,设置的“批量大小”远大于实际送入神经网络的图像数量,浪费了部分资源,将导致推理速度变慢。所以,请合理设置“批量大小”,以确保资源的合理使用。
注意事项¶
深度学习模型包导入失败¶
当已导入模型包,再导入名称相同的模型包时,需 修改模型包名称 或 注销同名模型包 ,再进行导入。

当重复导入了内容相同的模型包时,将提示 深度学习模型包导入失败 。
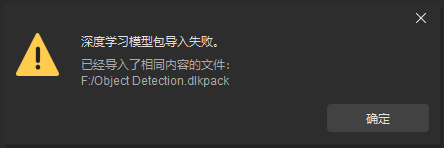
当软件、硬件条件不满足时,将导致模型包导入失败。GPU 驱动的最低版本要求为 472.50,CPU 的最低要求为英特尔第 6 代 Core。当 GPU 驱动版本为 500 以上时,模型包推理时间存在波动。
深度学习模型包优化失败¶
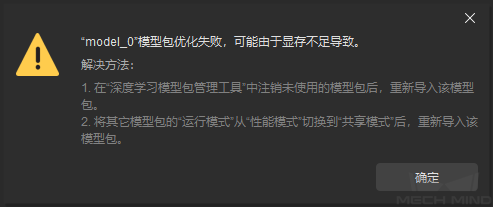
当显存不足时,可能导致模型包优化失败,如下图所示。可按照提示窗口的解决办法来解决该问题。
注意
对于级联模型包,若其中任一模型优化失败,则级联模型包整体优化失败,需重新进行模型包优化。
兼容性说明¶
Mech-Vision 1.7.1 可使用 Mech-DLK 2.4.1 及以上版本导出的深度学习模型包,但会存在以下兼容性问题。建议 Mech-Vision 1.7.2 及以上版本与 Mech-DLK 2.4.1 及更高版本导出的深度学习模型包配合使用。
Mech-Vision 无法使用级联模型包;
无法调整模型效率;
图像分类效果可能变差;
模型包无法在 CPU 设备上使用。
如果在 Mech-Vision 1.7.2 中使用 Mech-Vision 1.7.1 优化过的模型包,模型包在“深度学习模型包推理”步骤中首次运行时速度较慢。
当 Mech-DLK 2.4.1 导出的目标检测模型包的“推理时最大实例个数”为 1,且深度学习模型包管理工具的硬件类型为 CPU 时,模型包推理速度将会变得很慢,建议“推理时最大实例个数”大于 1。