Details of the Project¶
Project Workflow¶
Since there is no single model that can be applied to all objects of varying types and shapes, deep learning algorithms are needed to estimate pick points.
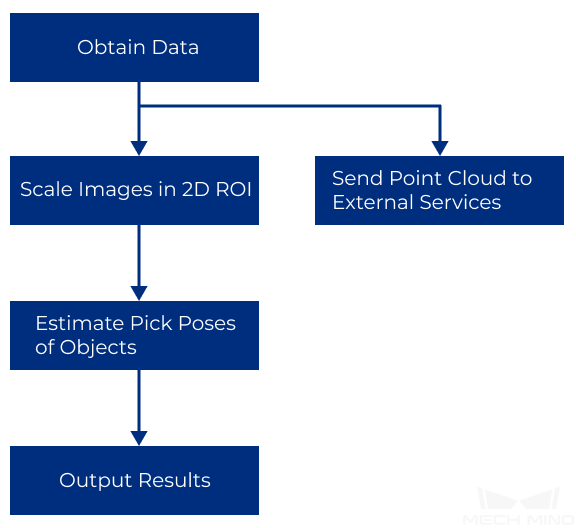
The vision result processing framework of a Pick Anything (Without Bin) project is shown below.
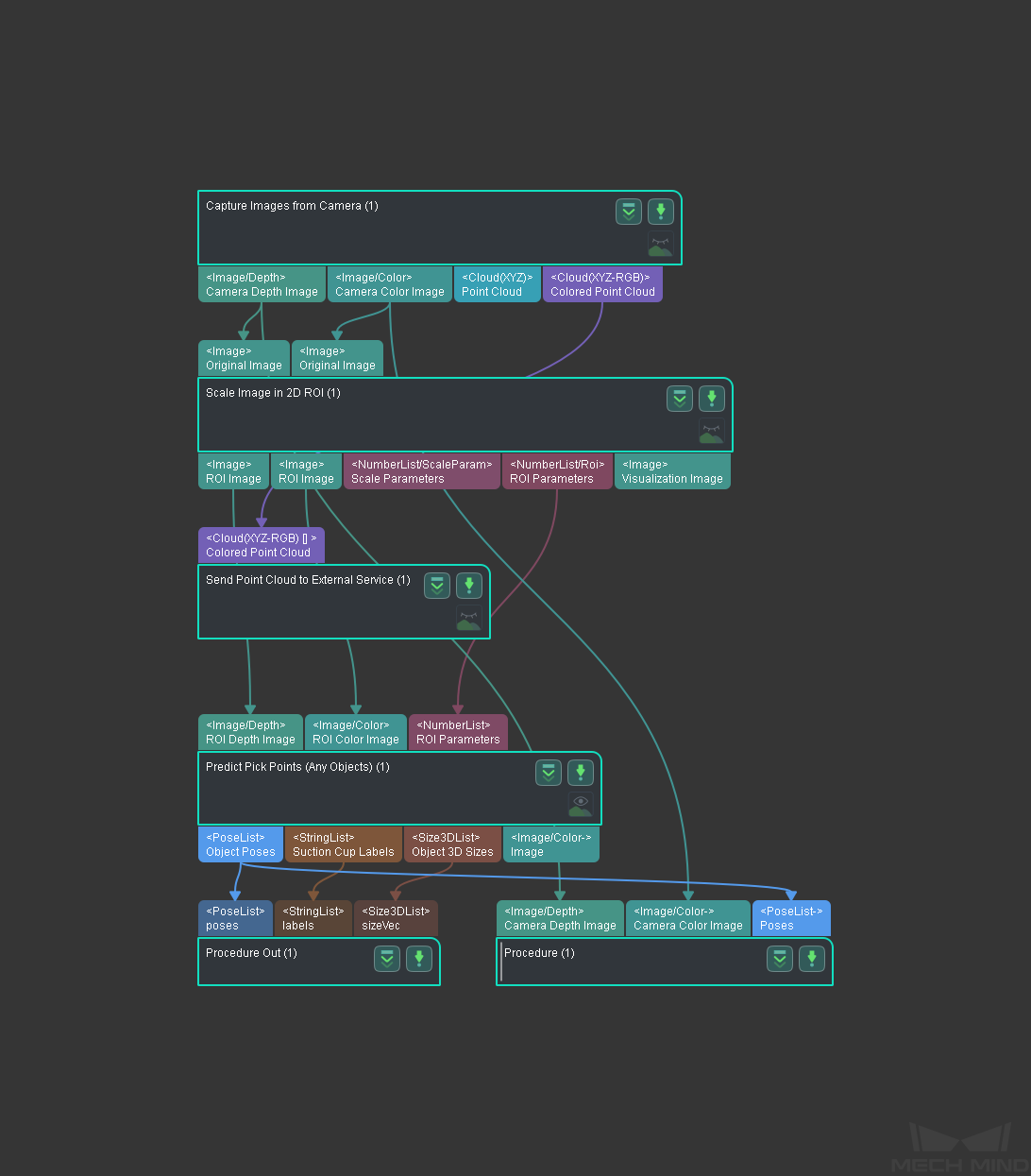
The project screenshot is shown below.
Explanation of the Steps¶
Capture Images from Camera¶
This Step is used to enable communictaion between Mech-Vision and the camera. You can obtain depth maps, color images, and point clouds from this Step and use these data for further computation to obtain the final vision results.
Please refer to Capture Images from Camera for detailed infomation of this Step.
Scale Image in 2D ROI¶
This Step is used to scale the ROI in an image to a specified size. The prediction result of the object pose is largely influenced by the ROI and the scaling ratio. Proper ROI and scaling ratio are necessary to obtain the desired pose results.
Predict Pick Points (Any Objects)¶
Since the objects to be picked are of different types and shapes, deep learning algorithms are utilized to estimate pick points. The Step used here is Predict Pick Points (Any Object).
After inputing color images, depth maps, and ROI parameters, with the assistance of deep learning algorithm, you can obtain pick points on the object in the camera reference frame (as shown below), dimensions of the pickable objects, and the corresponding suction cup label.

This Step can also be used to visualize the labeled regions of pickable objects in real time. You can modify the visualization type in the visualization parameters. The figure below is an example of setting Show Suction Cup Diameter as the Visualization Type.

Note
Enabling visualization may slow down the execution of the project.
Please refer to Predict Pick Points (Any Object) for detailed infomation of this Step.