全体的な紹介¶
画像分類の機能¶
画像分類では、 「これは何?」 を回答します。
即ち、画像にある物体のカテゴリ、ワークのサイズと型番を認識し、物体の正面か背面か、正確な位置にあるかないかを判断します。
具体例:
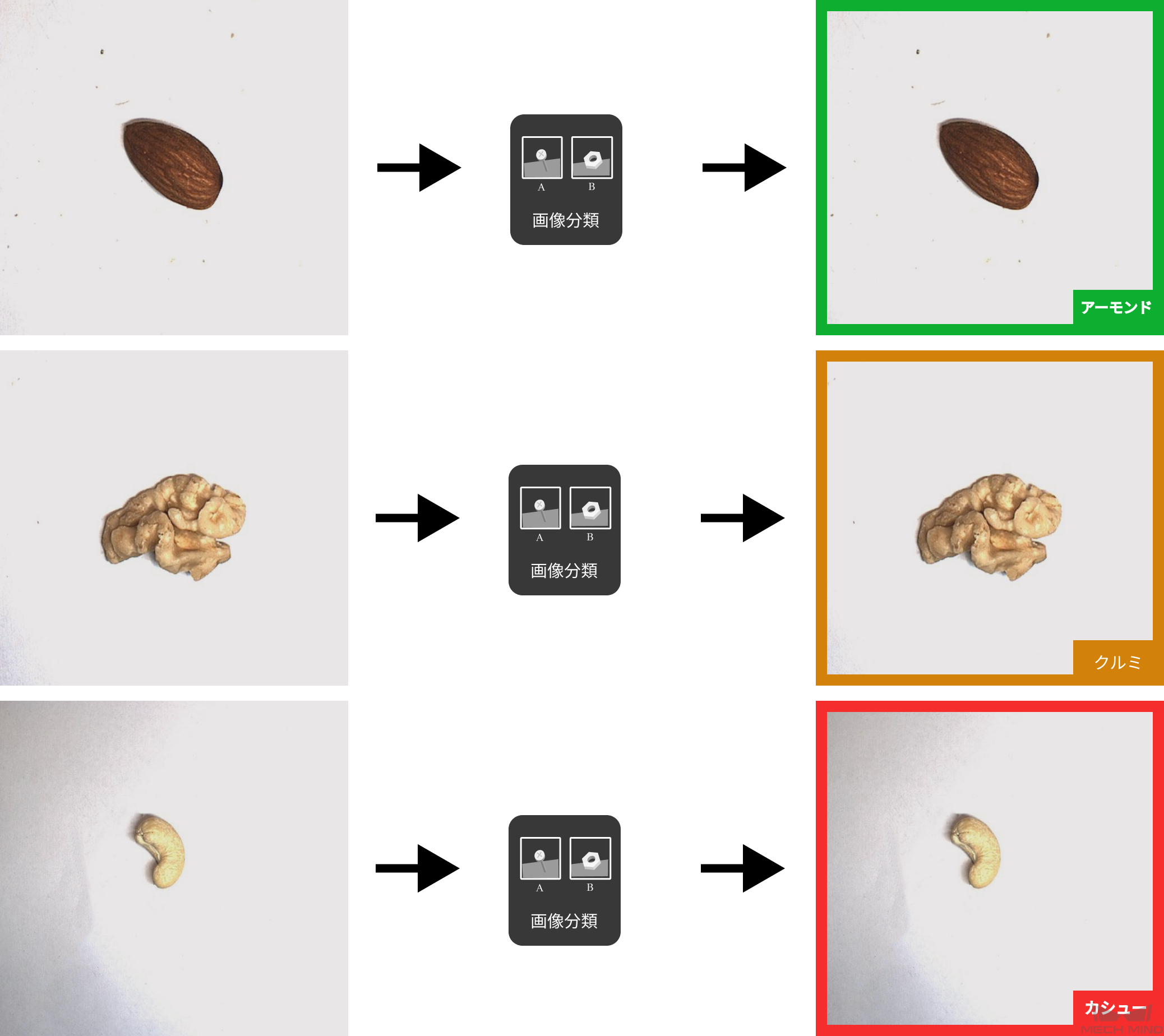
対象物はアーモンド、クルミ、カシューです。画像を入力し、その中のものはどの種類の対象物であるかを判断し、対応するカテゴリラベルが出力されます。
注意
画像分類によって出力されたラベルは、画像全体を対象とします。画像に複数のカテゴリの物体があり、それらを分類する場合は、画像を分割する必要があります(より小さな画像に分割し、分割された画像に1つだけの物体があるようにします)。また、状況に応じて インスタンスセグメンテーション もしくは「対象物検出」を使用することもできます。
業界の代表的な応用シーン¶
画像分類モデルを使用すれば、プロジェクトで異なるカテゴリの画像を区別することができます。以下では、典型的な応用シーンを紹介します。
ワークのロードとアンロードプロジェクトで、ワークの種類、向き、正面/背面を認識します。

組立/ピッキングのプロジェクトでは、物体が正確に配置されたかどうかなどを判断します。

応用プロセス¶
ディープラーニングに基づく画像分類では、ユーザーは実際応用の物体画像を十分に入力し、認識される物体が属するラベルカテゴリをマークする限り、画像分類モデルはその区別を学習できます。 ディープラーニングの画像分類の応用プロセスは以下の通りです。
トレニンーグに必要なデータを取得:カメラで各カテゴリの物体の画像を十分に取得します。
データラベリング:取得した各画像に対応するカテゴリラベルを設定します。
モデルトレニンーグ:前の2つのステップで取得されたラベル付きデータを画像分類モデルに入力して学習を実行します。
モデルを使用して予測:トレニンーグ済みモデルをプロジェクトに応用します。