纸箱拆/码垛项目应用¶
纸箱拆/码垛项目中,通常需要使用 实例分割 来分割出图中的每个纸箱并给出位置信息。
本公司专门针对纸箱拆/码垛场景提供了 超级模型 ,可以直接应用到Mech-Vision中,在无需训练的情况下正确分割绝大多数纸箱。
1. 使用超级模型并确认是否满足需求
注意
无论超级模型效果如何,请务必保留所有测试数据,便于后期可能需要的测试。
2. 采集超级模型分割错误的纸箱数据用于训练
一般情况下,超级模型可以识别大部分纸箱。极端情况下,如纸箱紧密贴合摆放或表面花纹复杂时,可能出现分割错误或掩膜不完整的情况;用户只需针对识别有问题的纸箱采集数据迭代模型即可。
例如,20种纸箱中有18种可以正确分割,有2种不能,则只需要采集这2种的数据。又如,单独摆放的纸箱都可以被正确分割,但紧密贴合摆放的纸箱不能,则只需要采集紧密贴合摆放的数据。
采集数量:每种纸箱(或摆放方式)采集20张。
数据要求:①在不同垛型高度(高层、中间层、底层)采集紧密贴合的纸箱图像10张;②在不同垛型高度(高层、中间层、底层)采集纸箱满垛、半垛、少量的情况图像10张。
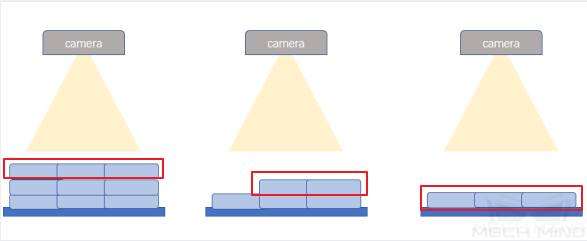
高层(图左)&中间层(图中)&底层(图右)¶
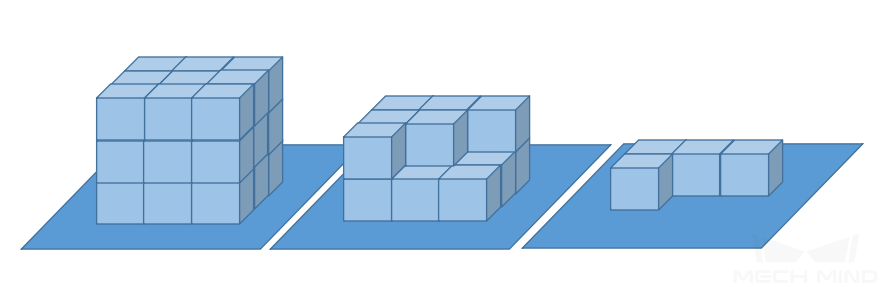
最高层满垛(图左)&中间层半垛(图中)&最底层少量(图右)¶
3. 对数据进行去背景操作
由于纸箱拆/码垛场景中纸箱都以成垛形式出现,进行去背景操作可以避免背景干扰,显著提高模型效果。在Mech-Vision中,通过去背景组合步骤处理得到去背景的数据。
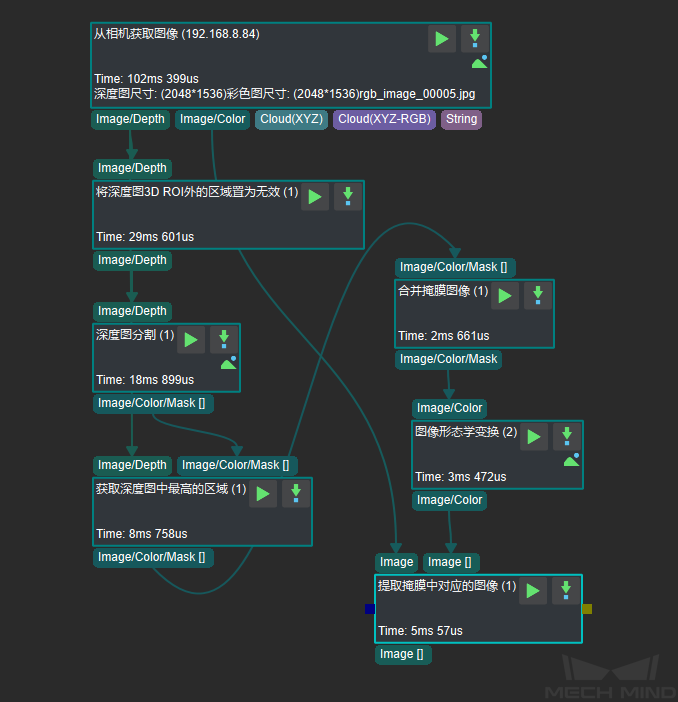

原图&去背景图¶
4. 标注数据

标注上表面轮廓¶
5. 训练模型
6. 使用新模型进行预测
7. 视情况重复步骤2-6再次进行模型更新
对于纸箱种类较多的情况,项目初期无法拿到所有类型的纸箱来测试。可以先用模型测试现有种类的纸箱数据,若后续有新类型纸箱加入且出现分割错误的情况,则需要重复步骤2-6再次进行模型更新。
注解
超级模型指基于海量数据训练的适用于某类物体(如纸箱、麻袋、快递包裹等)的通用深度学习模型。