종이 상자 디팔레타이징/팔레타이징¶
종이 상자 디팔레타이징/팔레타이징 프로젝트에 보통 인스턴스 세그멘테이션 을 사용하여 이미지 속의 모든 종이 상자를 분할하여 해당 위치를 지정합니다.
본사는 종이 상자 디팔레타이징/팔레타이징 시나리오를 위해 전문적으로 《슈퍼 모델》을 제공하고 Mech-Vision에서 직접 사용할 수 있으며 훈련하지 않아도 대부분 종이 상자를 정확하게 분할할 수 있습니다.
1. 슈퍼 모델을 사용하고 수요에 만족할 수 있는지를 확인하기
주의
슈퍼 모델의 효과가 좋든지 좋지 않든지를 막론하고 나중에 필요한 테스트를 위해 모든 테스트 데이터를 보관해야 합니다.
2. 정확하게 분할되지 못한 모든 종이 상자의 데이터를 수집하여 훈련에 쓰이기
일반적으로 슈퍼 모델을 통해 대부분 종이 상자를 분할할 수 있습니다. 극히 특별한 경우(예를 들어 종이 상자가 밀착하게 붙여 있거나 표면의 무늬가 복잡한 경우)에 정확하게 분할하지 못하거나 마스크가 불완전한 문제들이 나타날 수 있습니다. 사용자들은 인식할 때 문제가 있는 종이 상자의 데이터만 다시 수집하여 반복 모델에 사용하면 됩니다.
예를 들어 20개의 상자 중 18개의 상자를 올바르게 분할할 수 있고 그 중 2개는 할 수 없는 경우 2 가지 유형의 데이터만 수집하면 됩니다. 또한 개별적으로 배치된 모든 상자는 올바르게 분할될 수 있지만 서로 밀착하게 붙여 있는 상자는 할 수 없는 경우 밀착하게 붙여 있는 상자의 데이터만 수집하면 됩니다.
캡처 수량: 각 종류별(또는 배치 방법)에 대해 20 장을 수집합니다.
데이터에 대한 요구:①더미의 다양한 높이(높은 층, 중간 층, 낮은 층)에 배치된 서로 밀착하게 붙여 있는 종이 상자에 대해 이미지 약 10장 정도 캡처합니다;②더미의 다양한 높이(높은 층, 중간 층, 낮은 층)에서 종이 상자가 한 층을 꽉 채우는 경우, 반을 채우는 경우 그리고 소량 배치된 경우의 이미지를 각각 10장을 캡처합니다.
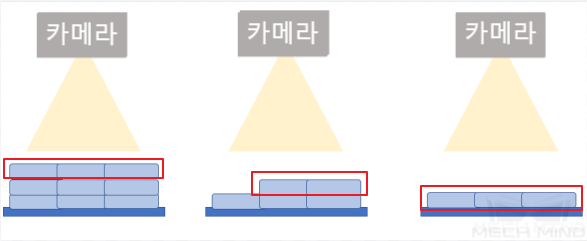
높은 층(왼쪽) & 중간 충(가운데) & 가장 낮은 층(오른쪽)¶

종이 상자가 가장 높은 층을 꽉 채우는 경우(왼쪽) & 중간 층에 반을 채우는 경우(가운데) & 가장 낮은 층에서 소량의 종이 상자가 배치되는 경우(오른쪽)¶
3. 데이터에 대해 배경을 제거하기
종이 상자 디팔레타이징/팔레타이징 프로젝트에 종이 상자가 보통 더미 식으로 나타나기 때문에 배경을 제거하면 배경으로 인한 간섭을 피할 수 있어서 모델의 사용 효과를 크게 향상시킬 수 있습니다. Mech-Vision에서 배경 제거 스텝 세트를 통해 배경을 제거한 뒤의 데이터를 획득할 수 있습니다.

배경을 제거하기 전/ 후의 이미지¶
4. 데이터 레이블링하기

상단 표면의 윤곽에 대해 레이블링하기¶
5. 모델을 훈련시키기
6. 새로운 모델을 통해 예측하기
인스턴스 세그멘테이션:모델을 통해 예측하기 를 참고하세요.
7. 상황에 따라 2-6을 반복하여 모델을 다시 업데이트하기
종이 상자의 수량이 매우 많은 경우 프로젝트 실행 초기에 모든 유형의 종이 상자에 대해 테스트할 수 없습니다. 이 때 모델을 사용하여 기존 유형의 종이 상자 데이터에 대해 태스트를 진행하고 나중에 새로운 유형의 종이 상자가 나타나고 정확하게 분할되지 못하면 스텝2-6를 반복하여 모델을 다시 업데이트해야 합니다.
참고
슈퍼 모델 :대량 데이터 훈련을 기반으로 하는 특정 유형의 물체(예: 상자, 마대, 택배 소포 등)에 적합한 일반적인 딥러닝 모델을 가리킵니다.