モデルを使用して予測する¶
Mech-Visionでインスタンスセグメンテーションモデルを使用する¶
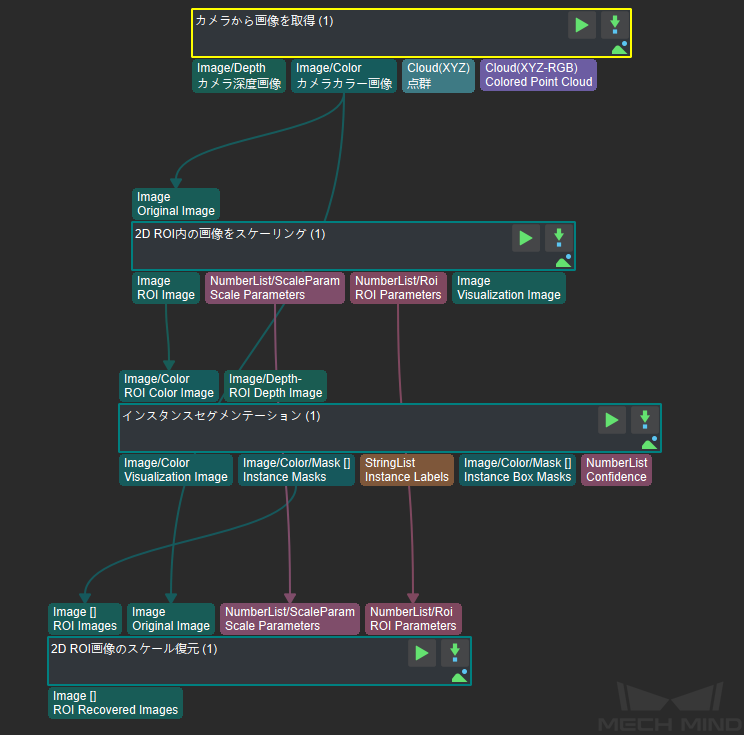
ステップ1:「カメラから画像を取得」を実行します。
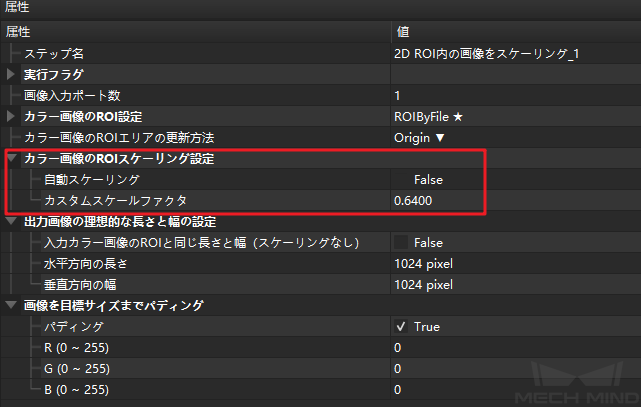
ステップ2:「2D ROI内の画像をスケーリング」し、実際のデータをトレーニングデータのROIと一致させます。ROIの手動・自動スケーリング設定に注意する必要があります。通常、デフォルトの自動スケーリングを使用します。
ステップ3:「インスタンスセグメンテーション」によりディープラーニングのセグメンテーション結果が出力されます。セグメンテーションの結果が要件を満たすかどうか、マスクが完全であるかどうか、認識に誤りや漏れが発生したかどうかを判断できます(モデルファイル.pthとコンフィグファイル.pyを正しく入力してください)。以下のパラメータに注意してください。
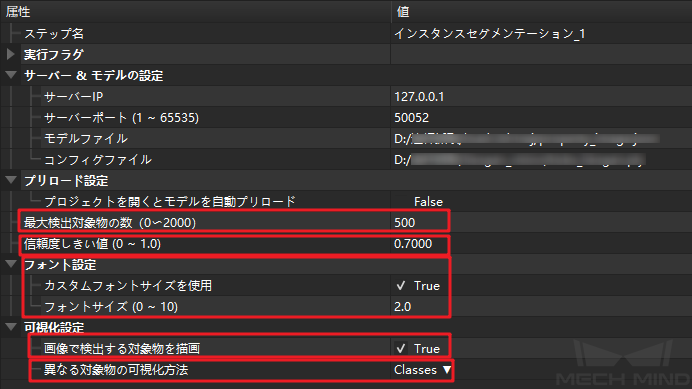
- プリロード設定-最大検出対象物の数
- モデルが一回で数十または数百の物体を認識する場合は、最大検出対象物の数を調整してください。対象物の数が少なくてかつプロジェクトのタクトが指定された場合は、このパラメータを小さくすれば、タクト向上を実現できます。
- プリロード設定-信頼度しきい値
- 普通、信頼度しきい値は、デフォルトの0.7にすればいいです。認識された物体のマスクの信頼度がデフォルトより低ければ、この物体を把持できないと判断し、信頼度の値が赤字で表示されます。プロジェクトの精度に対する要求に従ってこのパラメータを調整できます。例えば、信頼度の値が低くて物体のマスクが完全で把持できると判断した場合に、信頼度のパラメータを適切に低く調整することで把持可能な物体数を増やします。
- フォント設定-カスタムフォントサイズを使用
- 通常はデフォルトのフォントサイズを使用すればいいです。認識対象物が小さければ、効果を確認しやすいようにフォントサイズを適切に小さく調整できます。
- 可視化設定-画像で検出する対象物を描画
- 「True」をチェックにすれば認識対象物のマスクを認識でき、それでモデルの認識効果を確認できます。実際に実行する時はオフにしてタクト向上が可能です。
- 可視化設定-異なる対象物を可視化する方式
- 「Classes」を選択すると、色が異なるマスクで異なるラベル種類を表示します。「Instances」を選択すると、色が異なるマスクで異なる物体を表示します。「Threshold」を選択すると、色が異なるマスクで信頼度しきい値より高い物体と低い物体を表示します。
ちなみに
あるプロジェクトで2つのインスタンスセグメンテーションモデルが必要な場合は、2つの「インスタンスセグメンテーション」ステップを使用することになり、対応するモデルファイルとコンフィグファイルを設定します。さらに、 サーバーIPアドレス をそれぞれ「127.0.0.1:50052」と「127.0.0.1:50053」に設定する必要があります。そうしないと、ポートの衝突が発生します。
ステップ4:「2D ROI画像のスケール復元」を実行します(画像を元のサイズに戻します)。